 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMpoxSLDNet: A Novel CNN Model for Detecting Monkeypox Lesions and Performance Comparison with Pre-trained Models
May 31, 2024
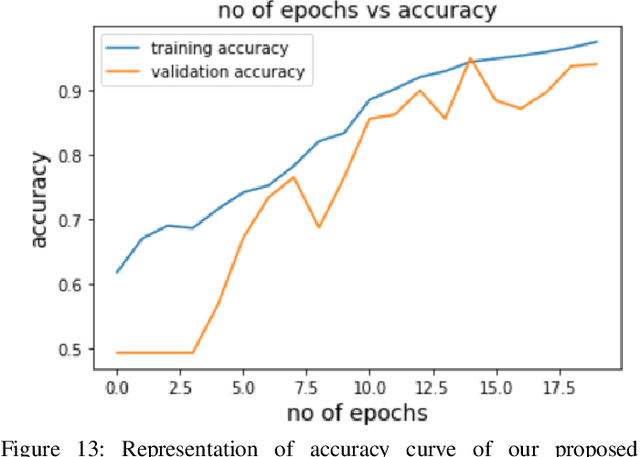
Monkeypox virus (MPXV) is a zoonotic virus that poses a significant threat to public health, particularly in remote parts of Central and West Africa. Early detection of monkeypox lesions is crucial for effective treatment. However, due to its similarity with other skin diseases, monkeypox lesion detection is a challenging task. To detect monkeypox, many researchers used various deep-learning models such as MobileNetv2, VGG16, ResNet50, InceptionV3, DenseNet121, EfficientNetB3, MobileNetV2, and Xception. However, these models often require high storage space due to their large size. This study aims to improve the existing challenges by introducing a CNN model named MpoxSLDNet (Monkeypox Skin Lesion Detector Network) to facilitate early detection and categorization of Monkeypox lesions and Non-Monkeypox lesions in digital images. Our model represents a significant advancement in the field of monkeypox lesion detection by offering superior performance metrics, including precision, recall, F1-score, accuracy, and AUC, compared to traditional pre-trained models such as VGG16, ResNet50, and DenseNet121. The key novelty of our approach lies in MpoxSLDNet's ability to achieve high detection accuracy while requiring significantly less storage space than existing models. By addressing the challenge of high storage requirements, MpoxSLDNet presents a practical solution for early detection and categorization of monkeypox lesions in resource-constrained healthcare settings. In this study, we have used "Monkeypox Skin Lesion Dataset" comprising 1428 skin images of monkeypox lesions and 1764 skin images of Non-Monkeypox lesions. Dataset's limitations could potentially impact the model's ability to generalize to unseen cases. However, the MpoxSLDNet model achieved a validation accuracy of 94.56%, compared to 86.25%, 84.38%, and 67.19% for VGG16, DenseNet121, and ResNet50, respectively.
Impact Learning: A Learning Method from Features Impact and Competition
Nov 04, 2022

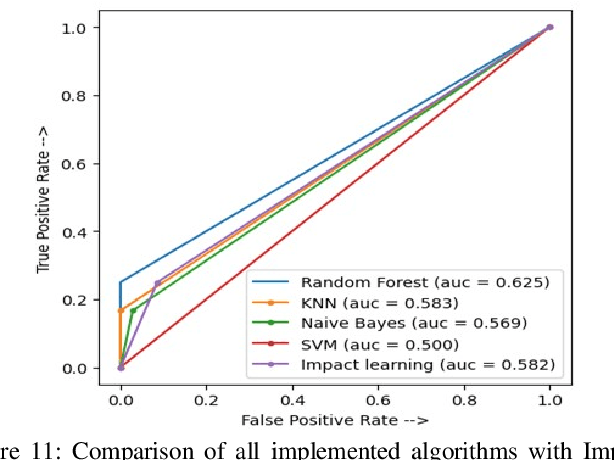

Machine learning is the study of computer algorithms that can automatically improve based on data and experience. Machine learning algorithms build a model from sample data, called training data, to make predictions or judgments without being explicitly programmed to do so. A variety of wellknown machine learning algorithms have been developed for use in the field of computer science to analyze data. This paper introduced a new machine learning algorithm called impact learning. Impact learning is a supervised learning algorithm that can be consolidated in both classification and regression problems. It can furthermore manifest its superiority in analyzing competitive data. This algorithm is remarkable for learning from the competitive situation and the competition comes from the effects of autonomous features. It is prepared by the impacts of the highlights from the intrinsic rate of natural increase (RNI). We, moreover, manifest the prevalence of the impact learning over the conventional machine learning algorithm.