 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Artificial General or Personalized Intelligence? A Survey on Foundation Models for Personalized Federated Intelligence
May 11, 2025



The rise of large language models (LLMs), such as ChatGPT, DeepSeek, and Grok-3, has reshaped the artificial intelligence landscape. As prominent examples of foundational models (FMs) built on LLMs, these models exhibit remarkable capabilities in generating human-like content, bringing us closer to achieving artificial general intelligence (AGI). However, their large-scale nature, sensitivity to privacy concerns, and substantial computational demands present significant challenges to personalized customization for end users. To bridge this gap, this paper presents the vision of artificial personalized intelligence (API), focusing on adapting these powerful models to meet the specific needs and preferences of users while maintaining privacy and efficiency. Specifically, this paper proposes personalized federated intelligence (PFI), which integrates the privacy-preserving advantages of federated learning (FL) with the zero-shot generalization capabilities of FMs, enabling personalized, efficient, and privacy-protective deployment at the edge. We first review recent advances in both FL and FMs, and discuss the potential of leveraging FMs to enhance federated systems. We then present the key motivations behind realizing PFI and explore promising opportunities in this space, including efficient PFI, trustworthy PFI, and PFI empowered by retrieval-augmented generation (RAG). Finally, we outline key challenges and future research directions for deploying FM-powered FL systems at the edge with improved personalization, computational efficiency, and privacy guarantees. Overall, this survey aims to lay the groundwork for the development of API as a complement to AGI, with a particular focus on PFI as a key enabling technique.
FedFeat+: A Robust Federated Learning Framework Through Federated Aggregation and Differentially Private Feature-Based Classifier Retraining
Apr 08, 2025In this paper, we propose the FedFeat+ framework, which distinctively separates feature extraction from classification. We develop a two-tiered model training process: following local training, clients transmit their weights and some features extracted from the feature extractor from the final local epochs to the server. The server aggregates these models using the FedAvg method and subsequently retrains the global classifier utilizing the shared features. The classifier retraining process enhances the model's understanding of the holistic view of the data distribution, ensuring better generalization across diverse datasets. This improved generalization enables the classifier to adaptively influence the feature extractor during subsequent local training epochs. We establish a balance between enhancing model accuracy and safeguarding individual privacy through the implementation of differential privacy mechanisms. By incorporating noise into the feature vectors shared with the server, we ensure that sensitive data remains confidential. We present a comprehensive convergence analysis, along with theoretical reasoning regarding performance enhancement and privacy preservation. We validate our approach through empirical evaluations conducted on benchmark datasets, including CIFAR-10, CIFAR-100, MNIST, and FMNIST, achieving high accuracy while adhering to stringent privacy guarantees. The experimental results demonstrate that the FedFeat+ framework, despite using only a lightweight two-layer CNN classifier, outperforms the FedAvg method in both IID and non-IID scenarios, achieving accuracy improvements ranging from 3.92 % to 12.34 % across CIFAR-10, CIFAR-100, and Fashion-MNIST datasets.
Advancing Ultra-Reliable 6G: Transformer and Semantic Localization Empowered Robust Beamforming in Millimeter-Wave Communications
Jun 04, 2024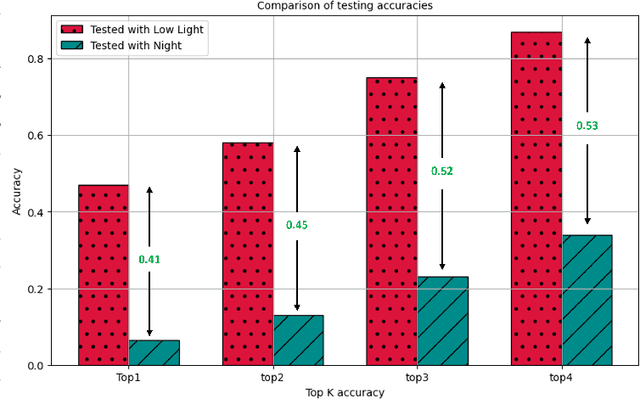
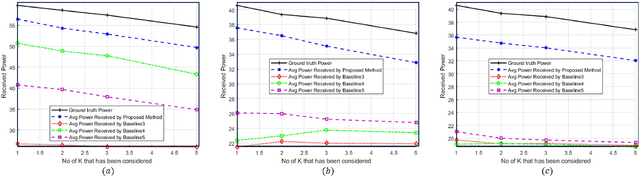
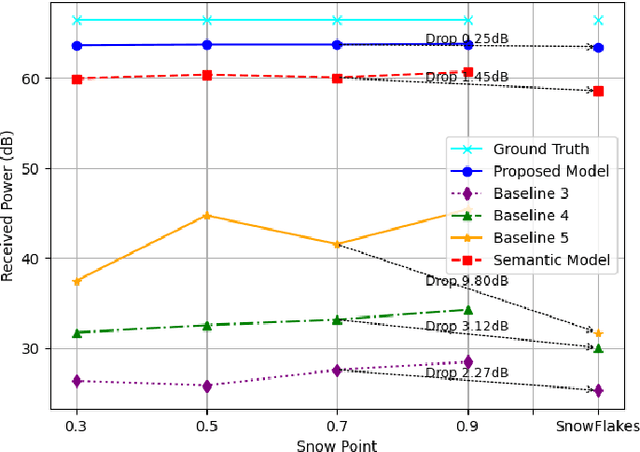
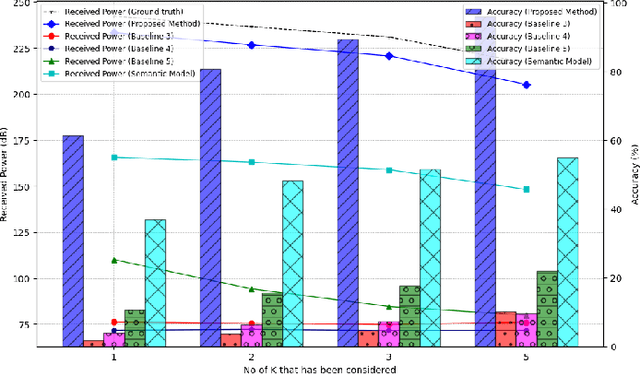
Advancements in 6G wireless technology have elevated the importance of beamforming, especially for attaining ultra-high data rates via millimeter-wave (mmWave) frequency deployment. Although promising, mmWave bands require substantial beam training to achieve precise beamforming. While initial deep learning models that use RGB camera images demonstrated promise in reducing beam training overhead, their performance suffers due to sensitivity to lighting and environmental variations. Due to this sensitivity, Quality of Service (QoS) fluctuates, eventually affecting the stability and dependability of networks in dynamic environments. This emphasizes a critical need for more robust solutions. This paper proposes a robust beamforming technique to ensure consistent QoS under varying environmental conditions. An optimization problem has been formulated to maximize users' data rates. To solve the formulated NP-hard optimization problem, we decompose it into two subproblems: the semantic localization problem and the optimal beam selection problem. To solve the semantic localization problem, we propose a novel method that leverages the k-means clustering and YOLOv8 model. To solve the beam selection problem, we propose a novel lightweight hybrid architecture that utilizes various data sources and a weighted entropy-based mechanism to predict the optimal beams. Rapid and accurate beam predictions are needed to maintain QoS. A novel metric, Accuracy-Complexity Efficiency (ACE), has been proposed to quantify this. Six testing scenarios have been developed to evaluate the robustness of the proposed model. Finally, the simulation result demonstrates that the proposed model outperforms several state-of-the-art baselines regarding beam prediction accuracy, received power, and ACE in the developed test scenarios.
CCC++: Optimized Color Classified Colorization with Segment Anything Model (SAM) Empowered Object Selective Color Harmonization
Mar 18, 2024In this paper, we formulate the colorization problem into a multinomial classification problem and then apply a weighted function to classes. We propose a set of formulas to transform color values into color classes and vice versa. To optimize the classes, we experiment with different bin sizes for color class transformation. Observing class appearance, standard deviation, and model parameters on various extremely large-scale real-time images in practice we propose 532 color classes for our classification task. During training, we propose a class-weighted function based on true class appearance in each batch to ensure proper saturation of individual objects. We adjust the weights of the major classes, which are more frequently observed, by lowering them, while escalating the weights of the minor classes, which are less commonly observed. In our class re-weight formula, we propose a hyper-parameter for finding the optimal trade-off between the major and minor appeared classes. As we apply regularization to enhance the stability of the minor class, occasional minor noise may appear at the object's edges. We propose a novel object-selective color harmonization method empowered by the Segment Anything Model (SAM) to refine and enhance these edges. We propose two new color image evaluation metrics, the Color Class Activation Ratio (CCAR), and the True Activation Ratio (TAR), to quantify the richness of color components. We compare our proposed model with state-of-the-art models using six different dataset: Place, ADE, Celeba, COCO, Oxford 102 Flower, and ImageNet, in qualitative and quantitative approaches. The experimental results show that our proposed model outstrips other models in visualization, CNR and in our proposed CCAR and TAR measurement criteria while maintaining satisfactory performance in regression (MSE, PSNR), similarity (SSIM, LPIPS, UIUI), and generative criteria (FID).
CCC: Color Classified Colorization
Mar 03, 2024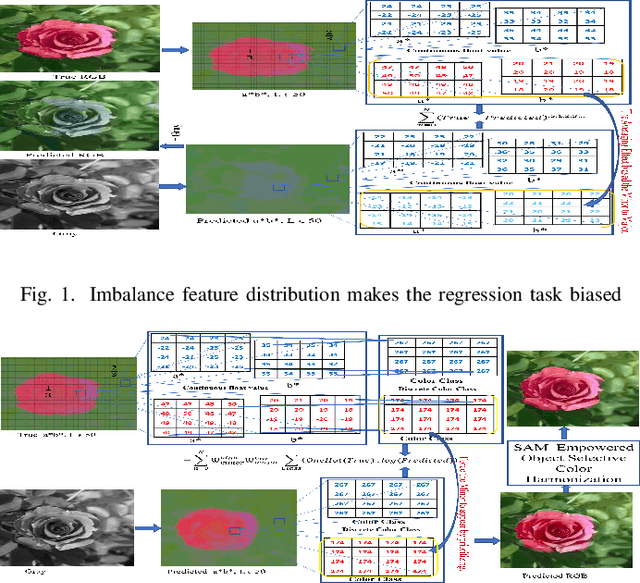
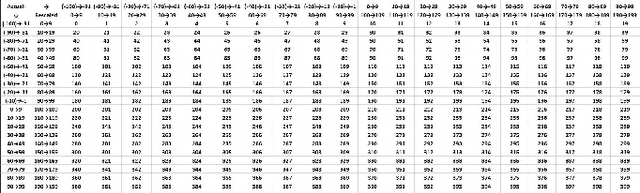
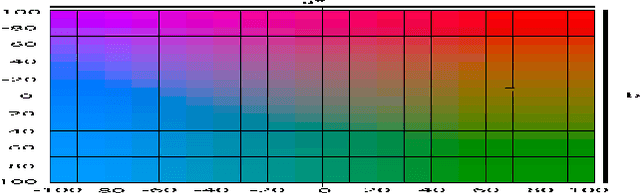
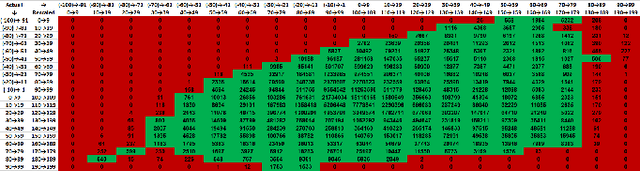
Automatic colorization of gray images with objects of different colors and sizes is challenging due to inter- and intra-object color variation and the small area of the main objects due to extensive backgrounds. The learning process often favors dominant features, resulting in a biased model. In this paper, we formulate the colorization problem into a multinomial classification problem and then apply a weighted function to classes. We propose a set of formulas to transform color values into color classes and vice versa. Class optimization and balancing feature distribution are the keys for good performance. Observing class appearance on various extremely large-scale real-time images in practice, we propose 215 color classes for our colorization task. During training, we propose a class-weighted function based on true class appearance in each batch to ensure proper color saturation of individual objects. We establish a trade-off between major and minor classes to provide orthodox class prediction by eliminating major classes' dominance over minor classes. As we apply regularization to enhance the stability of the minor class, occasional minor noise may appear at the object's edges. We propose a novel object-selective color harmonization method empowered by the SAM to refine and enhance these edges. We propose a new color image evaluation metric, the Chromatic Number Ratio (CNR), to quantify the richness of color components. We compare our proposed model with state-of-the-art models using five different datasets: ADE, Celeba, COCO, Oxford 102 Flower, and ImageNet, in both qualitative and quantitative approaches. The experimental results show that our proposed model outstrips other models in visualization and CNR measurement criteria while maintaining satisfactory performance in regression (MSE, PSNR), similarity (SSIM, LPIPS, UIQI), and generative criteria (FID).
MP-FedCL: Multi-Prototype Federated Contrastive Learning for Edge Intelligence
Apr 01, 2023
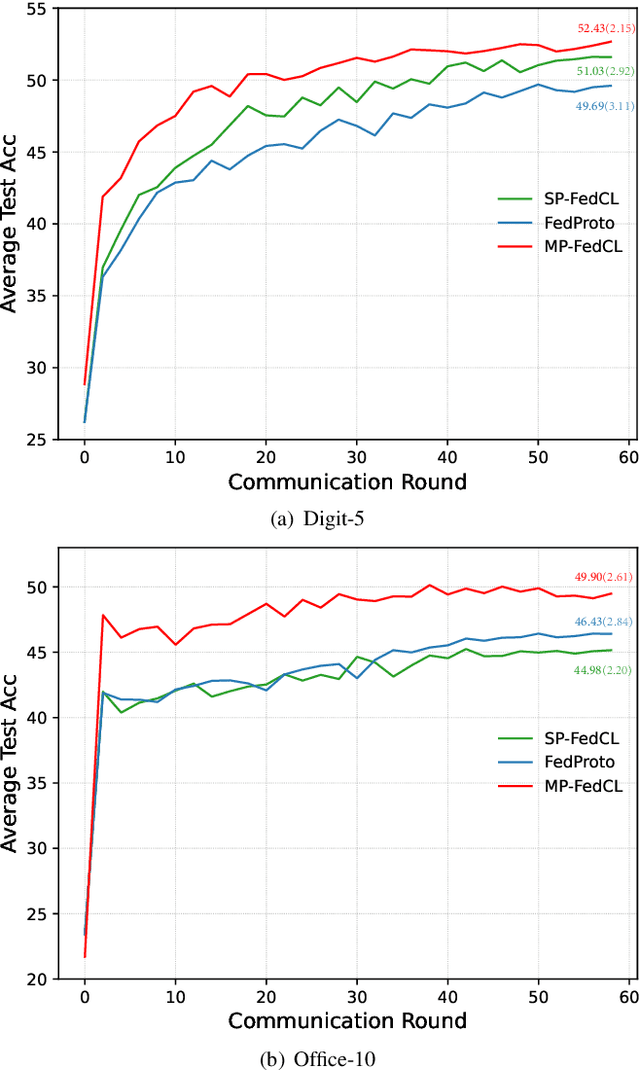
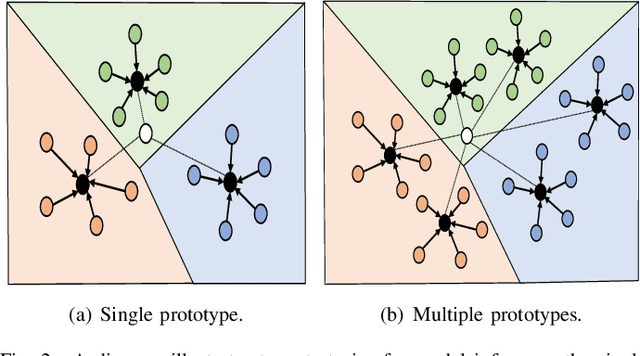
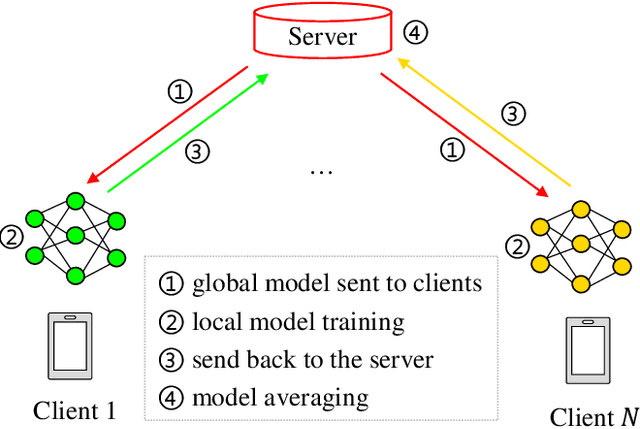
Federated learning-assisted edge intelligence enables privacy protection in modern intelligent services. However, not Independent and Identically Distributed (non-IID) distribution among edge clients can impair the local model performance. The existing single prototype-based strategy represents a sample by using the mean of the feature space. However, feature spaces are usually not clustered, and a single prototype may not represent a sample well. Motivated by this, this paper proposes a multi-prototype federated contrastive learning approach (MP-FedCL) which demonstrates the effectiveness of using a multi-prototype strategy over a single-prototype under non-IID settings, including both label and feature skewness. Specifically, a multi-prototype computation strategy based on \textit{k-means} is first proposed to capture different embedding representations for each class space, using multiple prototypes ($k$ centroids) to represent a class in the embedding space. In each global round, the computed multiple prototypes and their respective model parameters are sent to the edge server for aggregation into a global prototype pool, which is then sent back to all clients to guide their local training. Finally, local training for each client minimizes their own supervised learning tasks and learns from shared prototypes in the global prototype pool through supervised contrastive learning, which encourages them to learn knowledge related to their own class from others and reduces the absorption of unrelated knowledge in each global iteration. Experimental results on MNIST, Digit-5, Office-10, and DomainNet show that our method outperforms multiple baselines, with an average test accuracy improvement of about 4.6\% and 10.4\% under feature and label non-IID distributions, respectively.