 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgevieCap4H-VLSP 2021: Vietnamese Image Captioning for Healthcare Domain using Swin Transformer and Attention-based LSTM
Sep 03, 2022
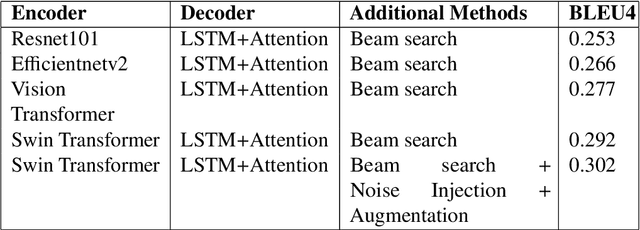
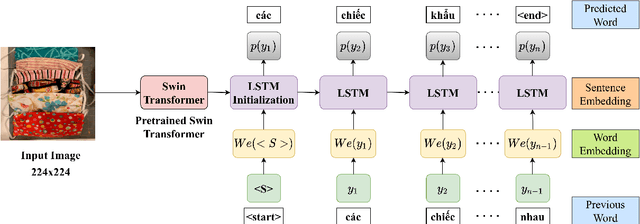

This study presents our approach on the automatic Vietnamese image captioning for healthcare domain in text processing tasks of Vietnamese Language and Speech Processing (VLSP) Challenge 2021, as shown in Figure 1. In recent years, image captioning often employs a convolutional neural network-based architecture as an encoder and a long short-term memory (LSTM) as a decoder to generate sentences. These models perform remarkably well in different datasets. Our proposed model also has an encoder and a decoder, but we instead use a Swin Transformer in the encoder, and a LSTM combined with an attention module in the decoder. The study presents our training experiments and techniques used during the competition. Our model achieves a BLEU4 score of 0.293 on the vietCap4H dataset, and the score is ranked the 3$^{rd}$ place on the private leaderboard. Our code can be found at \url{https://git.io/JDdJm}.
Fruit-CoV: An Efficient Vision-based Framework for Speedy Detection and Diagnosis of SARS-CoV-2 Infections Through Recorded Cough Sounds
Sep 06, 2021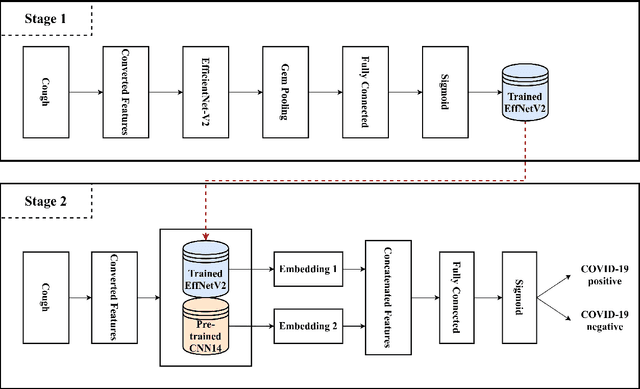
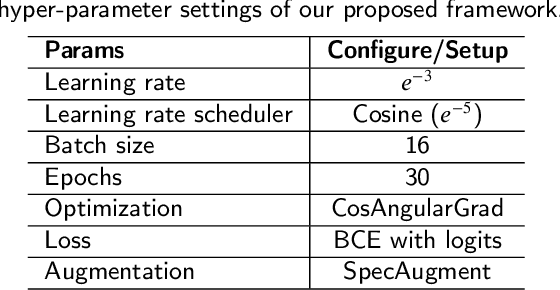
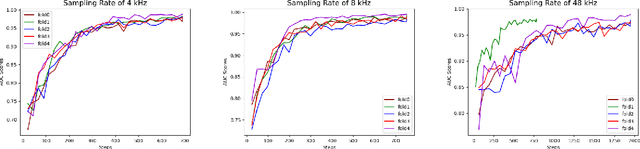
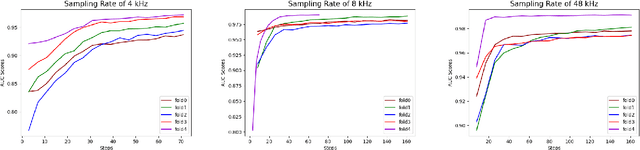
SARS-CoV-2 is colloquially known as COVID-19 that had an initial outbreak in December 2019. The deadly virus has spread across the world, taking part in the global pandemic disease since March 2020. In addition, a recent variant of SARS-CoV-2 named Delta is intractably contagious and responsible for more than four million deaths over the world. Therefore, it is vital to possess a self-testing service of SARS-CoV-2 at home. In this study, we introduce Fruit-CoV, a two-stage vision framework, which is capable of detecting SARS-CoV-2 infections through recorded cough sounds. Specifically, we convert sounds into Log-Mel Spectrograms and use the EfficientNet-V2 network to extract its visual features in the first stage. In the second stage, we use 14 convolutional layers extracted from the large-scale Pretrained Audio Neural Networks for audio pattern recognition (PANNs) and the Wavegram-Log-Mel-CNN to aggregate feature representations of the Log-Mel Spectrograms. Finally, we use the combined features to train a binary classifier. In this study, we use a dataset provided by the AICovidVN 115M Challenge, which includes a total of 7371 recorded cough sounds collected throughout Vietnam, India, and Switzerland. Experimental results show that our proposed model achieves an AUC score of 92.8% and ranks the 1st place on the leaderboard of the AICovidVN Challenge. More importantly, our proposed framework can be integrated into a call center or a VoIP system to speed up detecting SARS-CoV-2 infections through online/recorded cough sounds.
Review, Analyze, and Design a Comprehensive Deep Reinforcement Learning Framework
Feb 27, 2020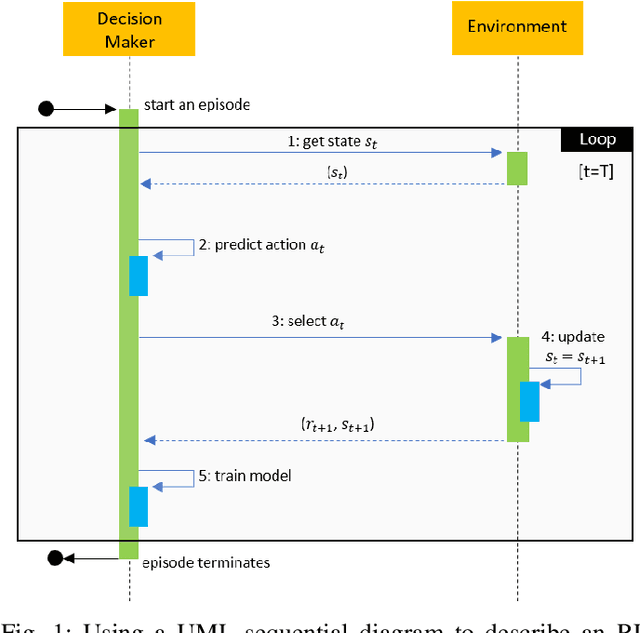
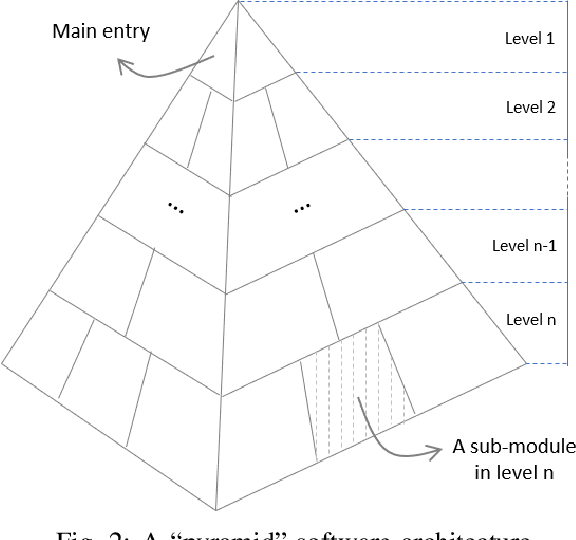
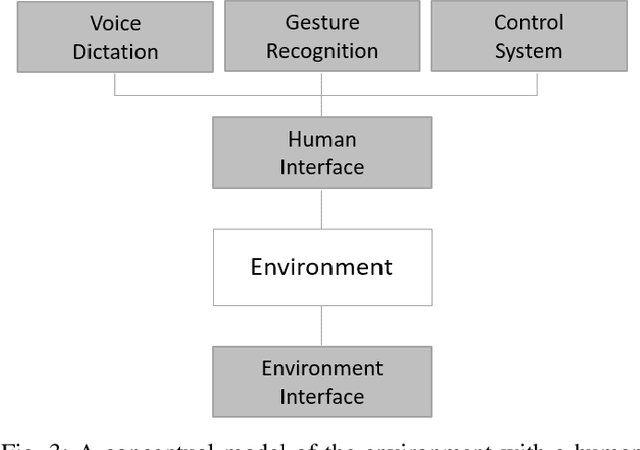
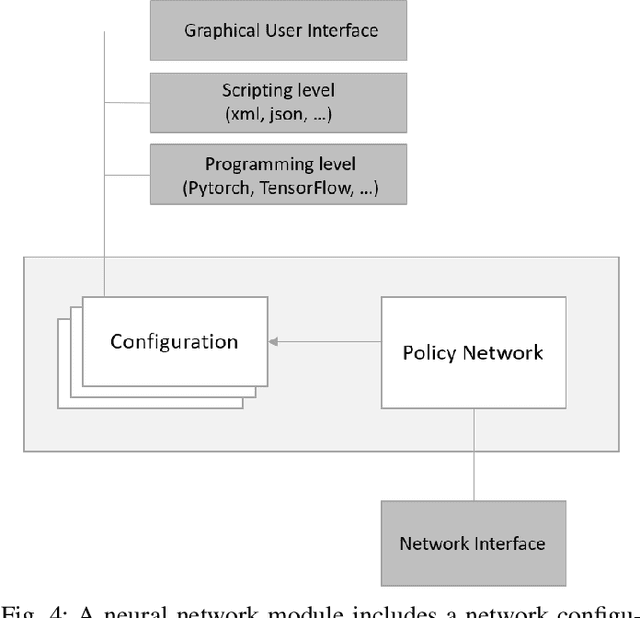
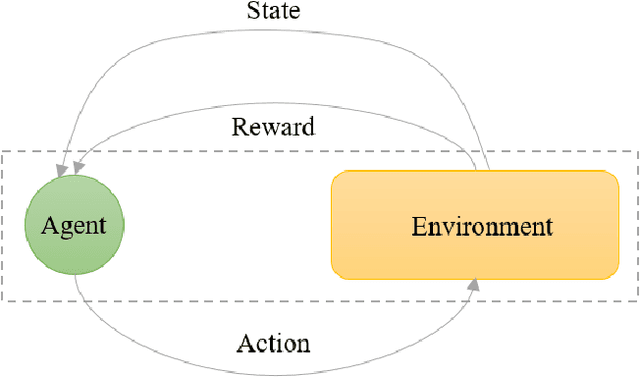
Reinforcement learning (RL) has emerged as a standard approach for building an intelligent system, which involves multiple self-operated agents to collectively accomplish a designated task. More importantly, there has been a great attention to RL since the introduction of deep learning that essentially makes RL feasible to operate in high-dimensional environments. However, current research interests are diverted into different directions, such as multi-agent and multi-objective learning, and human-machine interactions. Therefore, in this paper, we propose a comprehensive software architecture that not only plays a vital role in designing a connect-the-dots deep RL architecture but also provides a guideline to develop a realistic RL application in a short time span. By inheriting the proposed architecture, software managers can foresee any challenges when designing a deep RL-based system. As a result, they can expedite the design process and actively control every stage of software development, which is especially critical in agile development environments. For this reason, we designed a deep RL-based framework that strictly ensures flexibility, robustness, and scalability. Finally, to enforce generalization, the proposed architecture does not depend on a specific RL algorithm, a network configuration, the number of agents, or the type of agents.
A Visual Communication Map for Multi-Agent Deep Reinforcement Learning
Feb 27, 2020
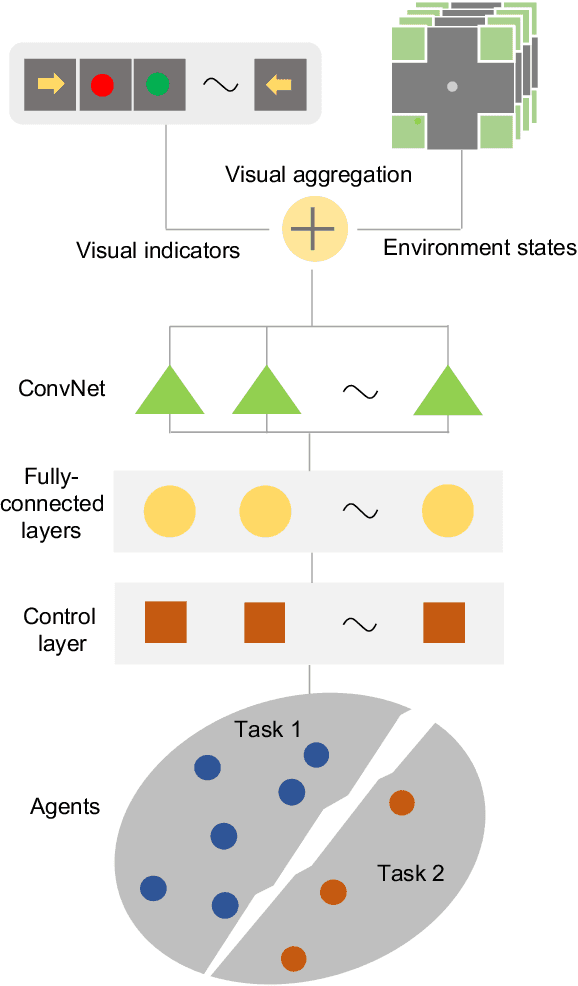

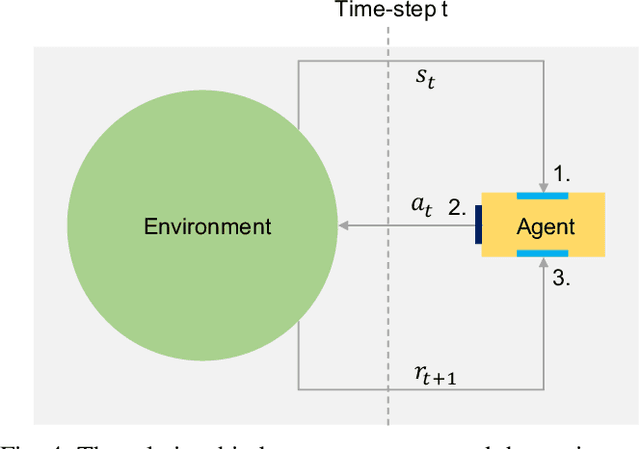
Multi-agent learning distinctly poses significant challenges in the effort to allocate a concealed communication medium. Agents receive thorough knowledge from the medium to determine subsequent actions in a distributed nature. Apparently, the goal is to leverage the cooperation of multiple agents to achieve a designated objective efficiently. Recent studies typically combine a specialized neural network with reinforcement learning to enable communication between agents. This approach, however, limits the number of agents or necessitates the homogeneity of the system. In this paper, we have proposed a more scalable approach that not only deals with a great number of agents but also enables collaboration between dissimilar functional agents and compatibly combined with any deep reinforcement learning methods. Specifically, we create a global communication map to represent the status of each agent in the system visually. The visual map and the environmental state are fed to a shared-parameter network to train multiple agents concurrently. Finally, we select the Asynchronous Advantage Actor-Critic (A3C) algorithm to demonstrate our proposed scheme, namely Visual communication map for Multi-agent A3C (VMA3C). Simulation results show that the use of visual communication map improves the performance of A3C regarding learning speed, reward achievement, and robustness in multi-agent problems.
Manipulating Soft Tissues by Deep Reinforcement Learning for Autonomous Robotic Surgery
Feb 14, 2019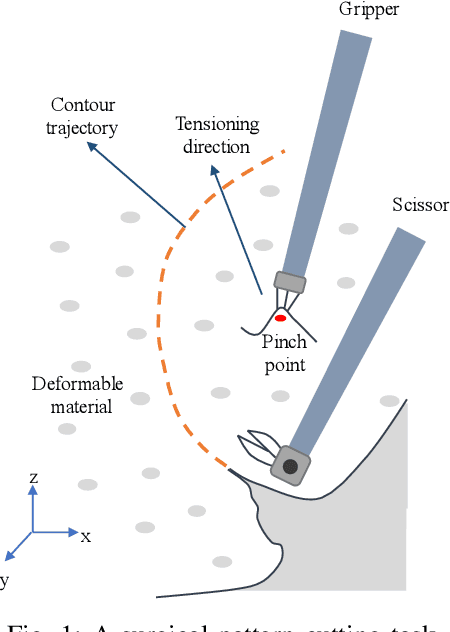
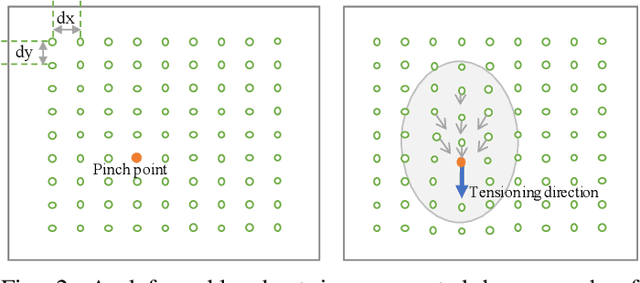
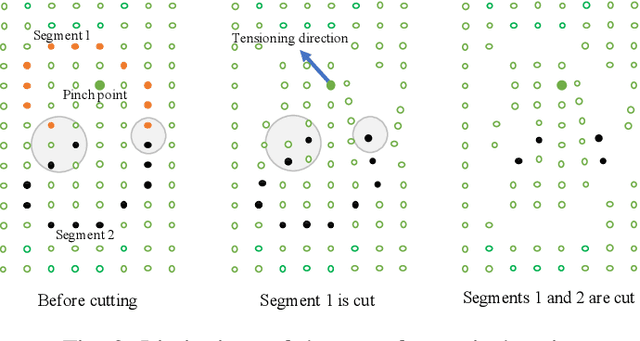
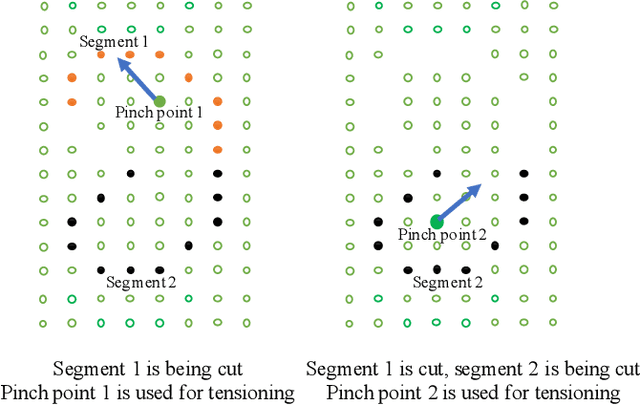
In robotic surgery, pattern cutting through a deformable material is a challenging research field. The cutting procedure requires a robot to concurrently manipulate a scissor and a gripper to cut through a predefined contour trajectory on the deformable sheet. The gripper ensures the cutting accuracy by nailing a point on the sheet and continuously tensioning the pinch point to different directions while the scissor is in action. The goal is to find a pinch point and a corresponding tensioning policy to minimize damage to the material and increase cutting accuracy measured by the symmetric difference between the predefined contour and the cut contour. Previous study considers finding one fixed pinch point during the course of cutting, which is inaccurate and unsafe when the contour trajectory is complex. In this paper, we examine the soft tissue cutting task by using multiple pinch points, which imitates human operations while cutting. This approach, however, does not require the use of a multi-gripper robot. We use a deep reinforcement learning algorithm to find an optimal tensioning policy of a pinch point. Simulation results show that the multi-point approach outperforms the state-of-the-art method in soft pattern cutting task with respect to both accuracy and reliability.
A New Tensioning Method using Deep Reinforcement Learning for Surgical Pattern Cutting
Jan 10, 2019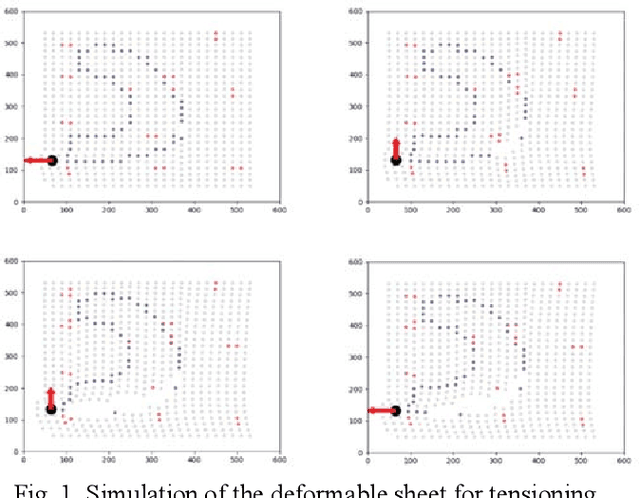
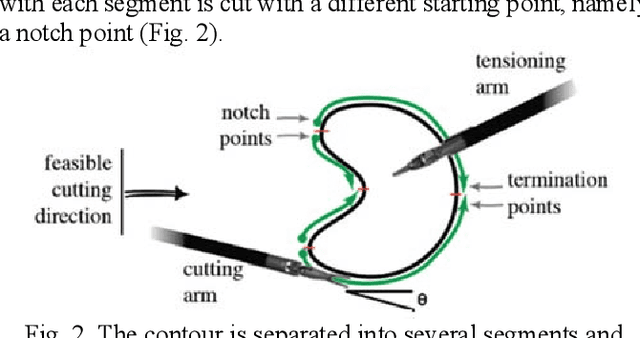
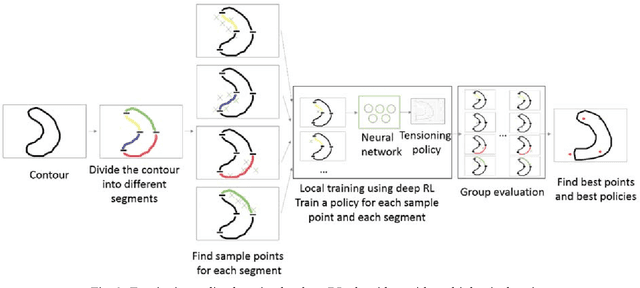
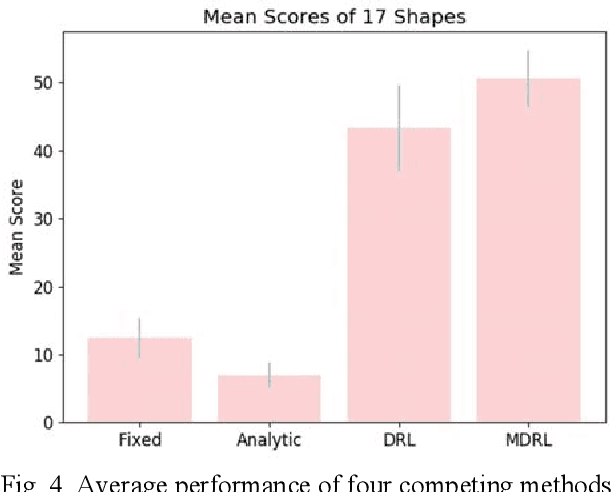
Surgeons normally need surgical scissors and tissue grippers to cut through a deformable surgical tissue. The cutting accuracy depends on the skills to manipulate these two tools. Such skills are part of basic surgical skills training as in the Fundamentals of Laparoscopic Surgery. The gripper is used to pinch a point on the surgical sheet and pull the tissue to a certain direction to maintain the tension while the scissors cut through a trajectory. As the surgical materials are deformable, it requires a comprehensive tensioning policy to yield appropriate tensioning direction at each step of the cutting process. Automating a tensioning policy for a given cutting trajectory will support not only the human surgeons but also the surgical robots to improve the cutting accuracy and reliability. This paper presents a multiple pinch point approach to modelling an autonomous tensioning planner based on a deep reinforcement learning algorithm. Experiments on a simulator show that the proposed method is superior to existing methods in terms of both performance and robustness.
Deep Reinforcement Learning for Multi-Agent Systems: A Review of Challenges, Solutions and Applications
Dec 31, 2018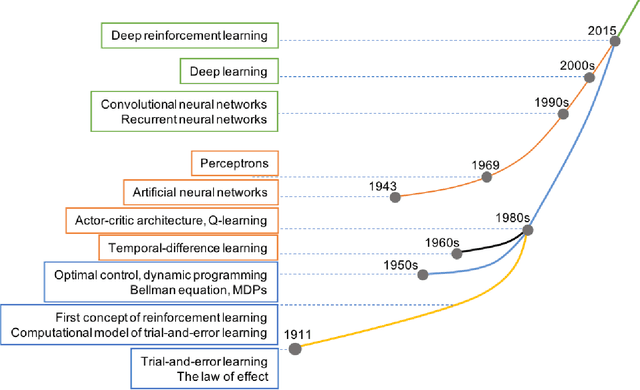
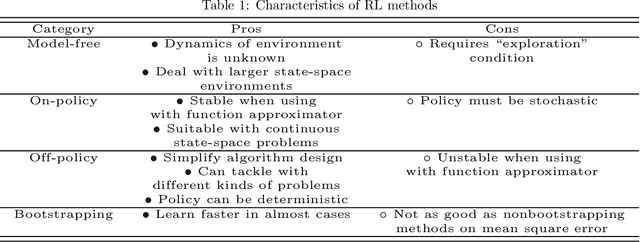

Reinforcement learning (RL) algorithms have been around for decades and been employed to solve various sequential decision-making problems. These algorithms however have faced great challenges when dealing with high-dimensional environments. The recent development of deep learning has enabled RL methods to drive optimal policies for sophisticated and capable agents, which can perform efficiently in these challenging environments. This paper addresses an important aspect of deep RL related to situations that demand multiple agents to communicate and cooperate to solve complex tasks. A survey of different approaches to problems related to multi-agent deep RL (MADRL) is presented, including non-stationarity, partial observability, continuous state and action spaces, multi-agent training schemes, multi-agent transfer learning. The merits and demerits of the reviewed methods will be analyzed and discussed, with their corresponding applications explored. It is envisaged that this review provides insights about various MADRL methods and can lead to future development of more robust and highly useful multi-agent learning methods for solving real-world problems.
Multi-Agent Deep Reinforcement Learning with Human Strategies
Jun 12, 2018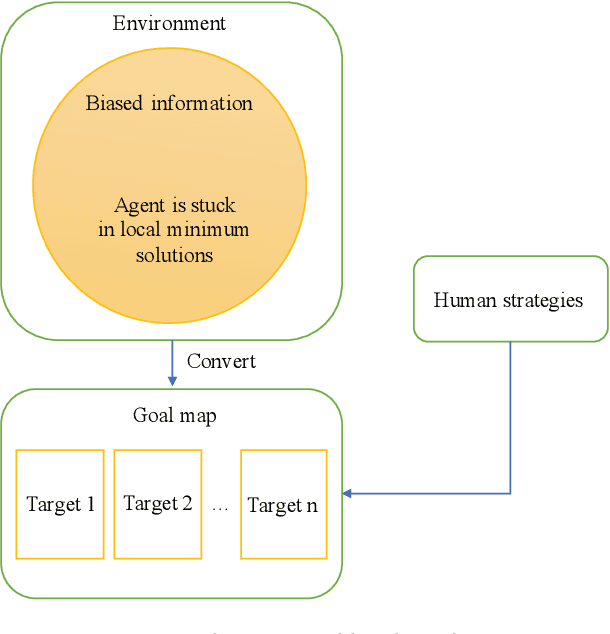
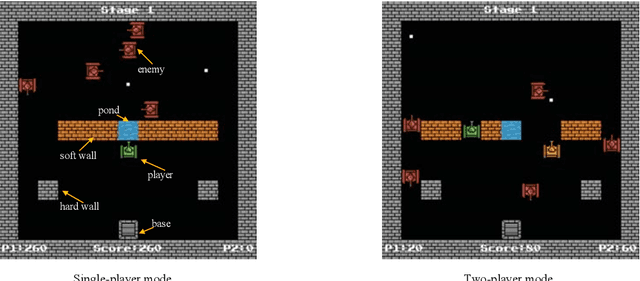
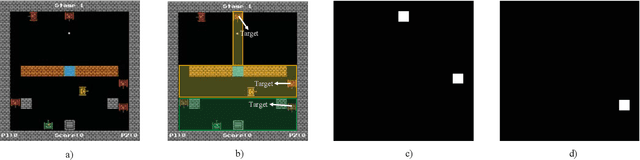
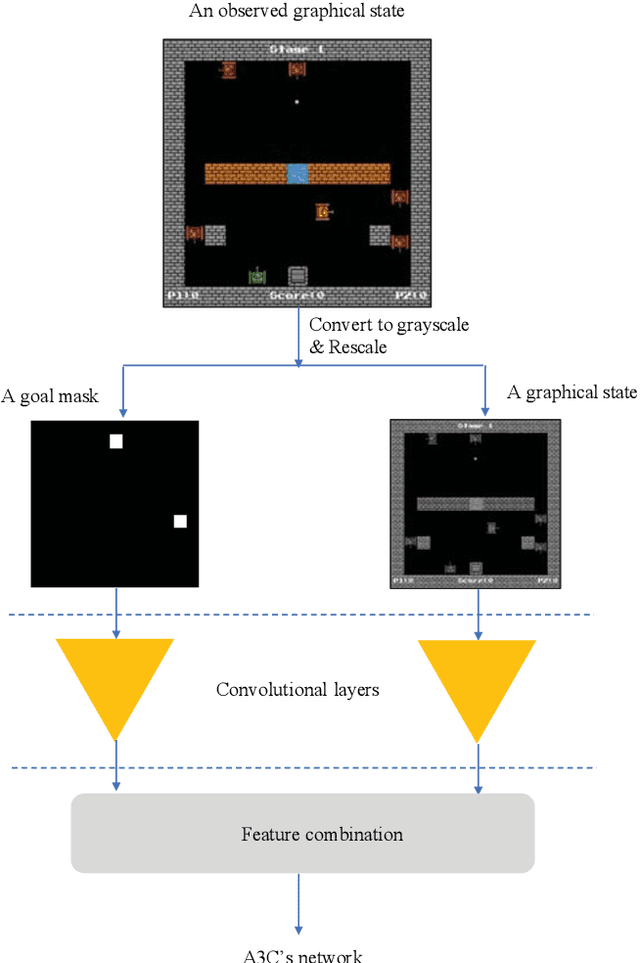
Deep learning has enabled traditional reinforcement learning methods to deal with high-dimensional problems. However, one of the disadvantages of deep reinforcement learning methods is the limited exploration capacity of learning agents. In this paper, we introduce an approach that integrates human strategies to increase the exploration capacity of multiple deep reinforcement learning agents. We also report the development of our own multi-agent environment called Multiple Tank Defence to simulate the proposed approach. The results show the significant performance improvement of multiple agents that have learned cooperatively with human strategies. This implies that there is a critical need for human intellect teamed with machines to solve complex problems. In addition, the success of this simulation indicates that our developed multi-agent environment can be used as a testbed platform to develop and validate other multi-agent control algorithms. Details of the environment implementation can be referred to http://www.deakin.edu.au/~thanhthi/madrl_human.htm
A Human Mixed Strategy Approach to Deep Reinforcement Learning
Apr 05, 2018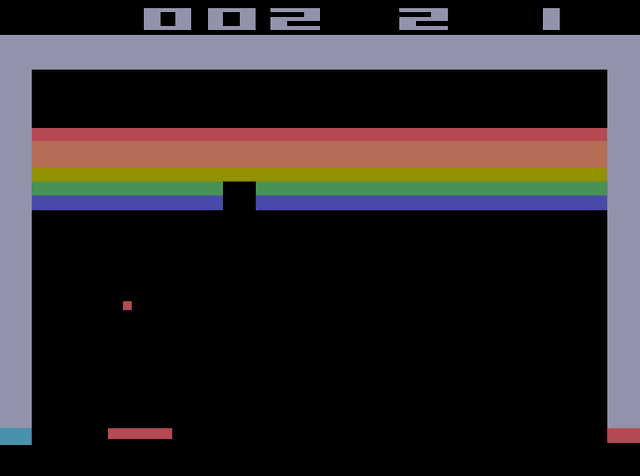
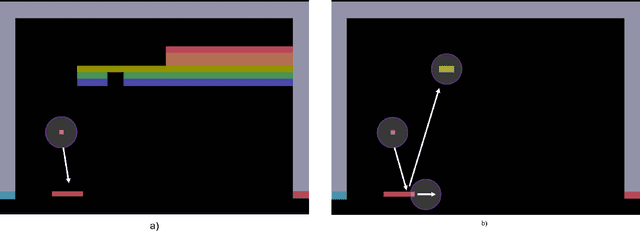
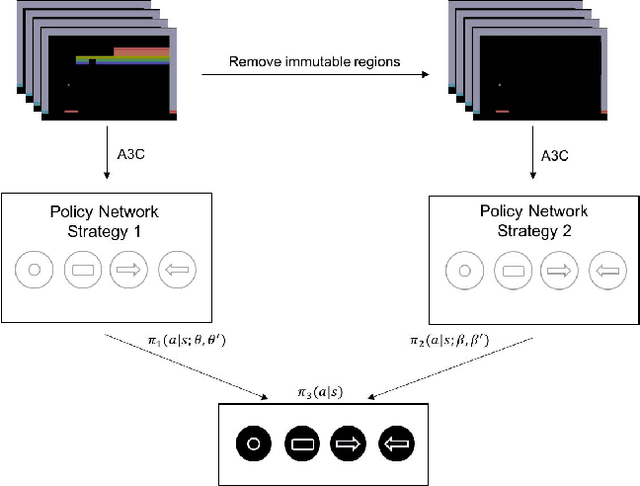
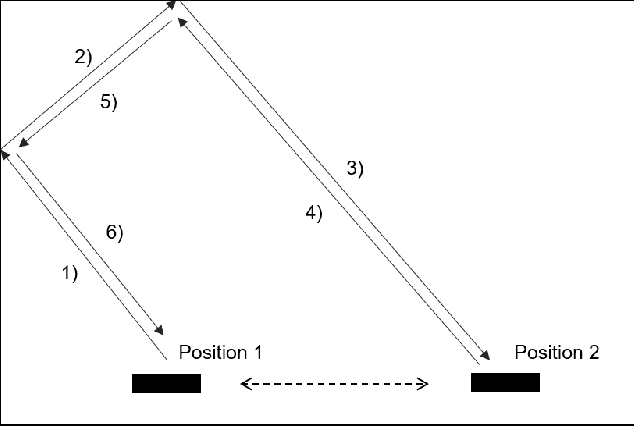
In 2015, Google's DeepMind announced an advancement in creating an autonomous agent based on deep reinforcement learning (DRL) that could beat a professional player in a series of 49 Atari games. However, the current manifestation of DRL is still immature, and has significant drawbacks. One of DRL's imperfections is its lack of "exploration" during the training process, especially when working with high-dimensional problems. In this paper, we propose a mixed strategy approach that mimics behaviors of human when interacting with environment, and create a "thinking" agent that allows for more efficient exploration in the DRL training process. The simulation results based on the Breakout game show that our scheme achieves a higher probability of obtaining a maximum score than does the baseline DRL algorithm, i.e., the asynchronous advantage actor-critic method. The proposed scheme therefore can be applied effectively to solving a complicated task in a real-world application.