 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Human Mixed Strategy Approach to Deep Reinforcement Learning
Paper and Code
Apr 05, 2018
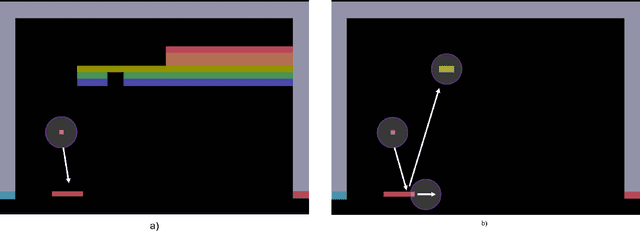
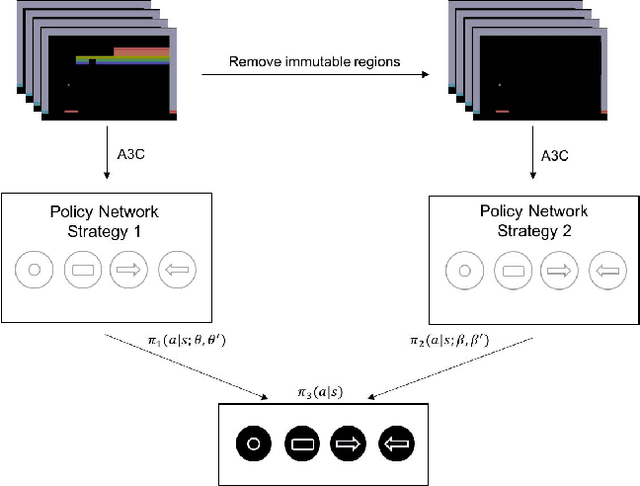
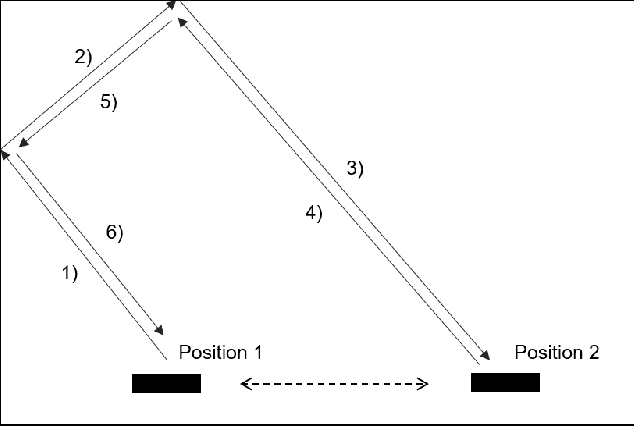
In 2015, Google's DeepMind announced an advancement in creating an autonomous agent based on deep reinforcement learning (DRL) that could beat a professional player in a series of 49 Atari games. However, the current manifestation of DRL is still immature, and has significant drawbacks. One of DRL's imperfections is its lack of "exploration" during the training process, especially when working with high-dimensional problems. In this paper, we propose a mixed strategy approach that mimics behaviors of human when interacting with environment, and create a "thinking" agent that allows for more efficient exploration in the DRL training process. The simulation results based on the Breakout game show that our scheme achieves a higher probability of obtaining a maximum score than does the baseline DRL algorithm, i.e., the asynchronous advantage actor-critic method. The proposed scheme therefore can be applied effectively to solving a complicated task in a real-world application.