 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Data Augmentation and Deep Attention-based Dilated Convolutional-Recurrent Neural Networks for Speech Emotion Recognition
Paper and Code
Sep 18, 2021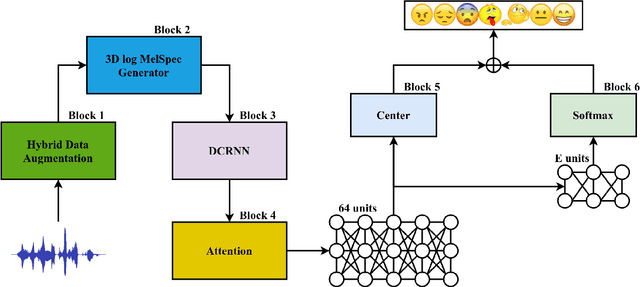
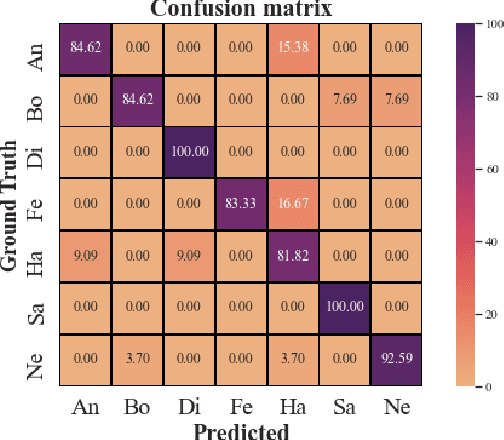
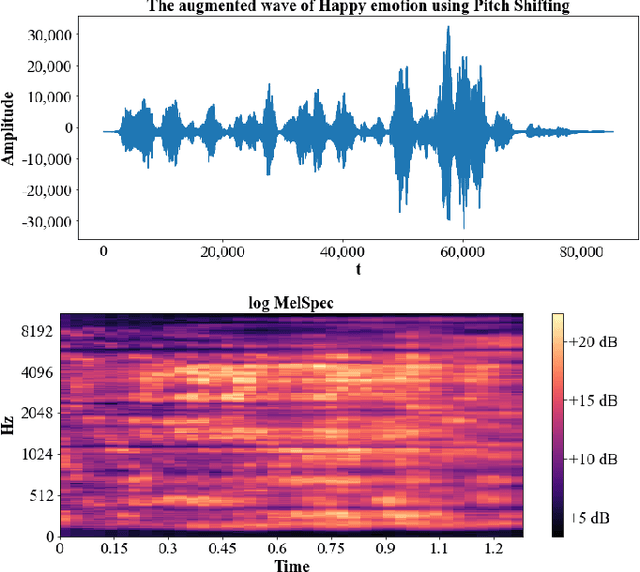
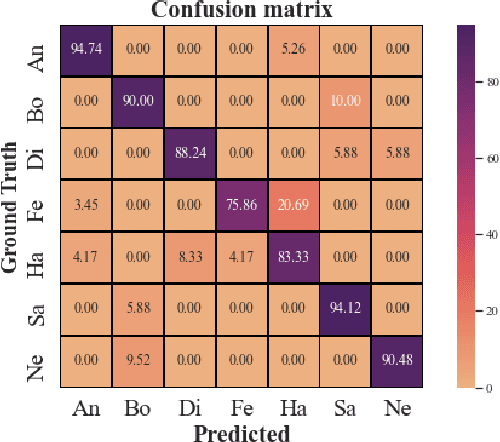
Speech emotion recognition (SER) has been one of the significant tasks in Human-Computer Interaction (HCI) applications. However, it is hard to choose the optimal features and deal with imbalance labeled data. In this article, we investigate hybrid data augmentation (HDA) methods to generate and balance data based on traditional and generative adversarial networks (GAN) methods. To evaluate the effectiveness of HDA methods, a deep learning framework namely (ADCRNN) is designed by integrating deep dilated convolutional-recurrent neural networks with an attention mechanism. Besides, we choose 3D log Mel-spectrogram (MelSpec) features as the inputs for the deep learning framework. Furthermore, we reconfigure a loss function by combining a softmax loss and a center loss to classify the emotions. For validating our proposed methods, we use the EmoDB dataset that consists of several emotions with imbalanced samples. Experimental results prove that the proposed methods achieve better accuracy than the state-of-the-art methods on the EmoDB with 87.12% and 88.47% for the traditional and GAN-based methods, respectively.