 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast SAM2 with Text-Driven Token Pruning
Dec 24, 2025Segment Anything Model 2 (SAM2), a vision foundation model has significantly advanced in prompt-driven video object segmentation, yet their practical deployment remains limited by the high computational and memory cost of processing dense visual tokens across time. The SAM2 pipelines typically propagate all visual tokens produced by the image encoder through downstream temporal reasoning modules, regardless of their relevance to the target object, resulting in reduced scalability due to quadratic memory attention overhead. In this work, we introduce a text-guided token pruning framework that improves inference efficiency by selectively reducing token density prior to temporal propagation, without modifying the underlying segmentation architecture. Operating after visual encoding and before memory based propagation, our method ranks tokens using a lightweight routing mechanism that integrates local visual context, semantic relevance derived from object-centric textual descriptions (either user-provided or automatically generated), and uncertainty cues that help preserve ambiguous or boundary critical regions. By retaining only the most informative tokens for downstream processing, the proposed approach reduces redundant computation while maintaining segmentation fidelity. Extensive experiments across multiple challenging video segmentation benchmarks demonstrate that post-encoder token pruning provides a practical and effective pathway to efficient, prompt-aware video segmentation, achieving up to 42.50 percent faster inference and 37.41 percent lower GPU memory usage compared to the unpruned baseline SAM2, while preserving competitive J and F performance. These results highlight the potential of early token selection to improve the scalability of transformer-based video segmentation systems for real-time and resource-constrained applications.
Exploring Kernel Transformations for Implicit Neural Representations
Apr 07, 2025Implicit neural representations (INRs), which leverage neural networks to represent signals by mapping coordinates to their corresponding attributes, have garnered significant attention. They are extensively utilized for image representation, with pixel coordinates as input and pixel values as output. In contrast to prior works focusing on investigating the effect of the model's inside components (activation function, for instance), this work pioneers the exploration of the effect of kernel transformation of input/output while keeping the model itself unchanged. A byproduct of our findings is a simple yet effective method that combines scale and shift to significantly boost INR with negligible computation overhead. Moreover, we present two perspectives, depth and normalization, to interpret the performance benefits caused by scale and shift transformation. Overall, our work provides a new avenue for future works to understand and improve INR through the lens of kernel transformation.
Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation
Mar 08, 2024


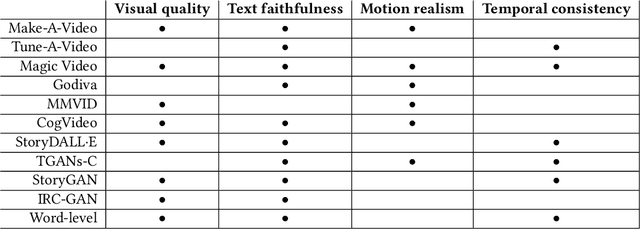
Text-to-video generation marks a significant frontier in the rapidly evolving domain of generative AI, integrating advancements in text-to-image synthesis, video captioning, and text-guided editing. This survey critically examines the progression of text-to-video technologies, focusing on the shift from traditional generative models to the cutting-edge Sora model, highlighting developments in scalability and generalizability. Distinguishing our analysis from prior works, we offer an in-depth exploration of the technological frameworks and evolutionary pathways of these models. Additionally, we delve into practical applications and address ethical and technological challenges such as the inability to perform multiple entity handling, comprehend causal-effect learning, understand physical interaction, perceive object scaling and proportioning, and combat object hallucination which is also a long-standing problem in generative models. Our comprehensive discussion covers the topic of enablement of text-to-video generation models as human-assistive tools and world models, as well as eliciting model's shortcomings and summarizing future improvement direction that mainly centers around training datasets and evaluation metrics (both automatic and human-centered). Aimed at both newcomers and seasoned researchers, this survey seeks to catalyze further innovation and discussion in the growing field of text-to-video generation, paving the way for more reliable and practical generative artificial intelligence technologies.