 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient LLaMA-3.2-Vision by Trimming Cross-attended Visual Features
Paper and Code
Apr 01, 2025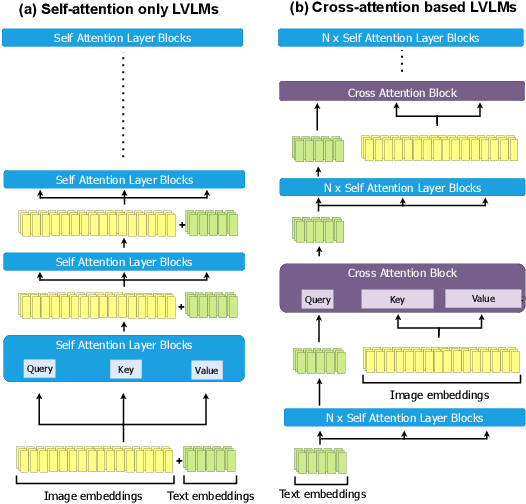
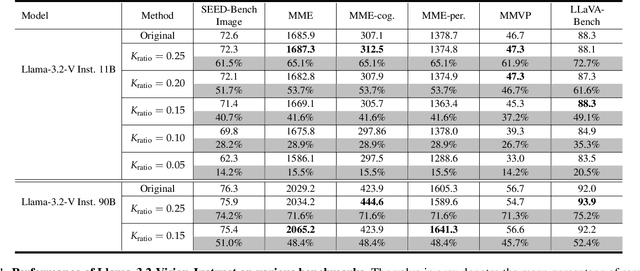
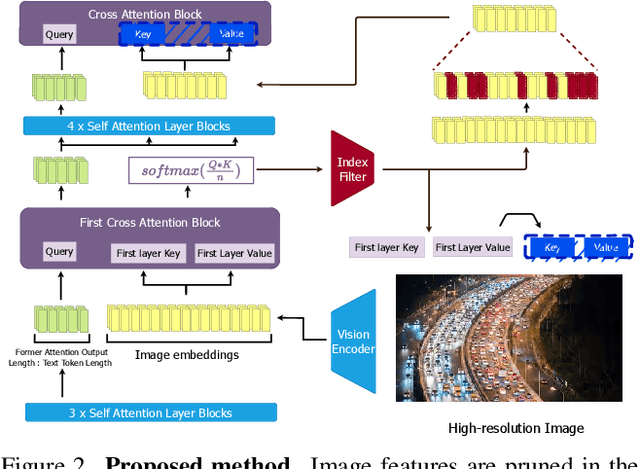
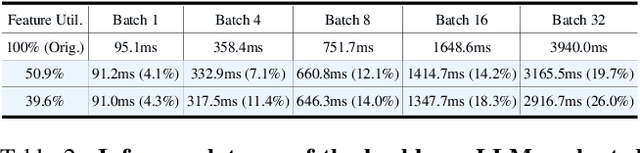
Visual token reduction lowers inference costs caused by extensive image features in large vision-language models (LVLMs). Unlike relevant studies that prune tokens in self-attention-only LVLMs, our work uniquely addresses cross-attention-based models, which achieve superior performance. We identify that the key-value (KV) cache size for image tokens in cross-attention layers significantly exceeds that of text tokens in self-attention layers, posing a major compute bottleneck. To mitigate this issue, we exploit the sparse nature in cross-attention maps to selectively prune redundant visual features. Our Trimmed Llama effectively reduces KV cache demands without requiring additional training. By benefiting from 50%-reduced visual features, our model can reduce inference latency and memory usage while achieving benchmark parity.