 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards quantitative precision for ECG analysis: Leveraging state space models, self-supervision and patient metadata
Aug 29, 2023Deep learning has emerged as the preferred modeling approach for automatic ECG analysis. In this study, we investigate three elements aimed at improving the quantitative accuracy of such systems. These components consistently enhance performance beyond the existing state-of-the-art, which is predominantly based on convolutional models. Firstly, we explore more expressive architectures by exploiting structured state space models (SSMs). These models have shown promise in capturing long-term dependencies in time series data. By incorporating SSMs into our approach, we not only achieve better performance, but also gain insights into long-standing questions in the field. Specifically, for standard diagnostic tasks, we find no advantage in using higher sampling rates such as 500Hz compared to 100Hz. Similarly, extending the input size of the model beyond 3 seconds does not lead to significant improvements. Secondly, we demonstrate that self-supervised learning using contrastive predictive coding can further improve the performance of SSMs. By leveraging self-supervision, we enable the model to learn more robust and representative features, leading to improved analysis accuracy. Lastly, we depart from synthetic benchmarking scenarios and incorporate basic demographic metadata alongside the ECG signal as input. This inclusion of patient metadata departs from the conventional practice of relying solely on the signal itself. Remarkably, this addition consistently yields positive effects on predictive performance. We firmly believe that all three components should be considered when developing next-generation ECG analysis algorithms.
Explaining Deep Learning for ECG Analysis: Building Blocks for Auditing and Knowledge Discovery
May 26, 2023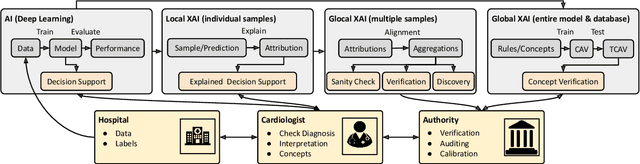
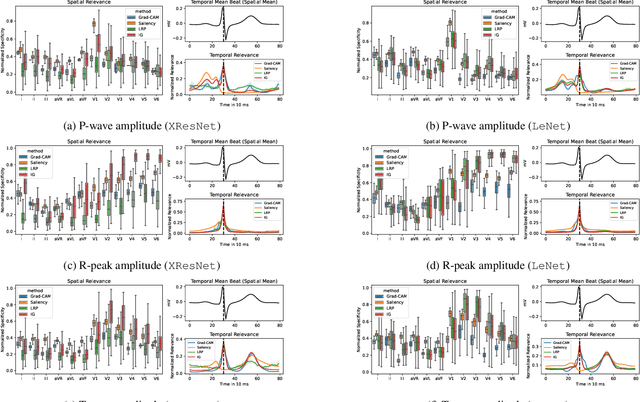
Deep neural networks have become increasingly popular for analyzing ECG data because of their ability to accurately identify cardiac conditions and hidden clinical factors. However, the lack of transparency due to the black box nature of these models is a common concern. To address this issue, explainable AI (XAI) methods can be employed. In this study, we present a comprehensive analysis of post-hoc XAI methods, investigating the local (attributions per sample) and global (based on domain expert concepts) perspectives. We have established a set of sanity checks to identify sensible attribution methods, and we provide quantitative evidence in accordance with expert rules. This dataset-wide analysis goes beyond anecdotal evidence by aggregating data across patient subgroups. Furthermore, we demonstrate how these XAI techniques can be utilized for knowledge discovery, such as identifying subtypes of myocardial infarction. We believe that these proposed methods can serve as building blocks for a complementary assessment of the internal validity during a certification process, as well as for knowledge discovery in the field of ECG analysis.
ECG Feature Importance Rankings: Cardiologists vs. Algorithms
Apr 05, 2023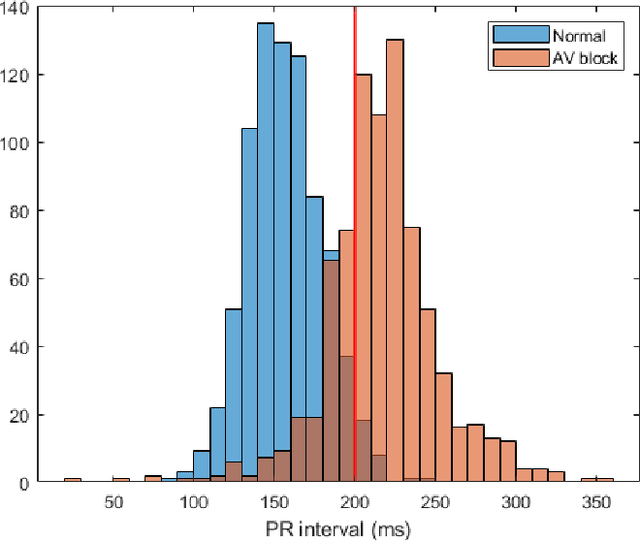
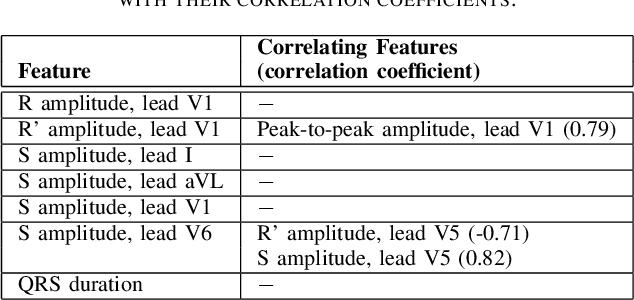
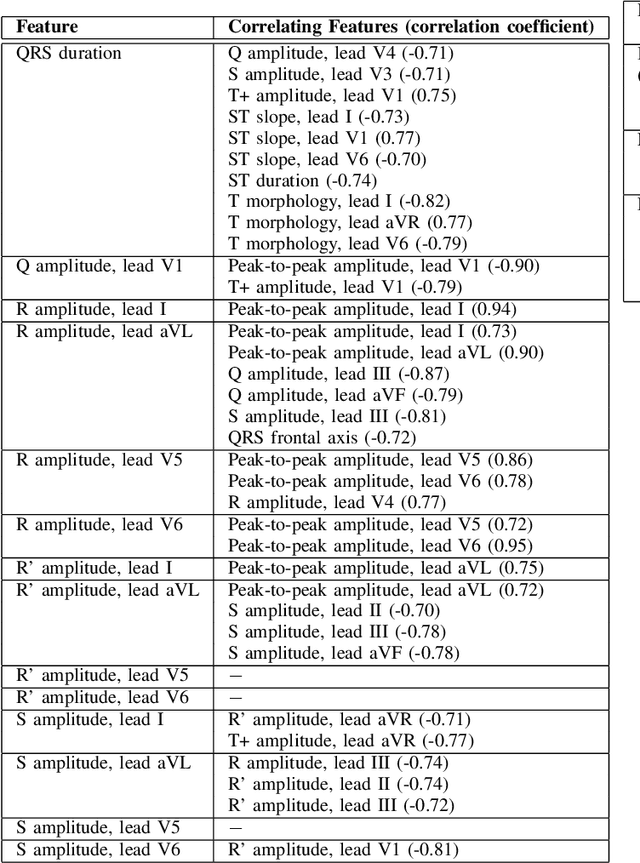

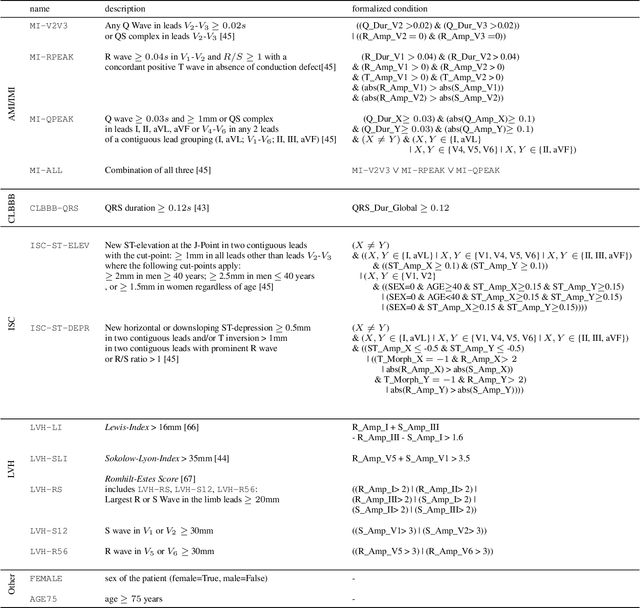
Feature importance methods promise to provide a ranking of features according to importance for a given classification task. A wide range of methods exist but their rankings often disagree and they are inherently difficult to evaluate due to a lack of ground truth beyond synthetic datasets. In this work, we put feature importance methods to the test on real-world data in the domain of cardiology, where we try to distinguish three specific pathologies from healthy subjects based on ECG features comparing to features used in cardiologists' decision rules as ground truth. Some methods generally performed well and others performed poorly, while some methods did well on some but not all of the problems considered.
Advancing the State-of-the-Art for ECG Analysis through Structured State Space Models
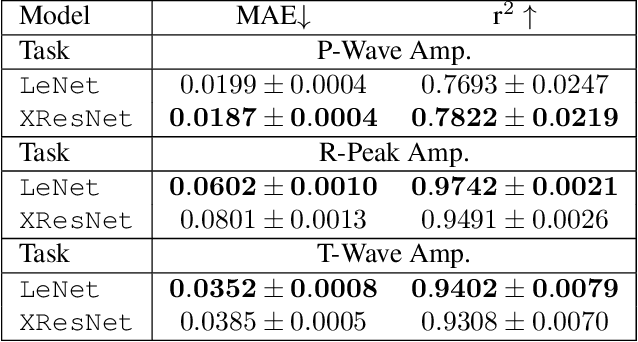
Nov 14, 2022The field of deep-learning-based ECG analysis has been largely dominated by convolutional architectures. This work explores the prospects of applying the recently introduced structured state space models (SSMs) as a particularly promising approach due to its ability to capture long-term dependencies in time series. We demonstrate that this approach leads to significant improvements over the current state-of-the-art for ECG classification, which we trace back to individual pathologies. Furthermore, the model's ability to capture long-term dependencies allows to shed light on long-standing questions in the literature such as the optimal sampling rate or window size to train classification models. Interestingly, we find no evidence for using data sampled at 500Hz as opposed to 100Hz and no advantages from extending the model's input size beyond 3s. Based on this very promising first assessment, SSMs could develop into a new modeling paradigm for ECG analysis.
Self-supervised representation learning from 12-lead ECG data
Mar 23, 2021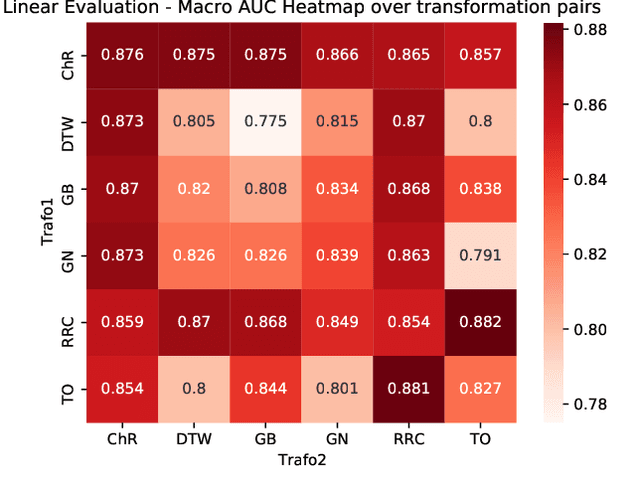

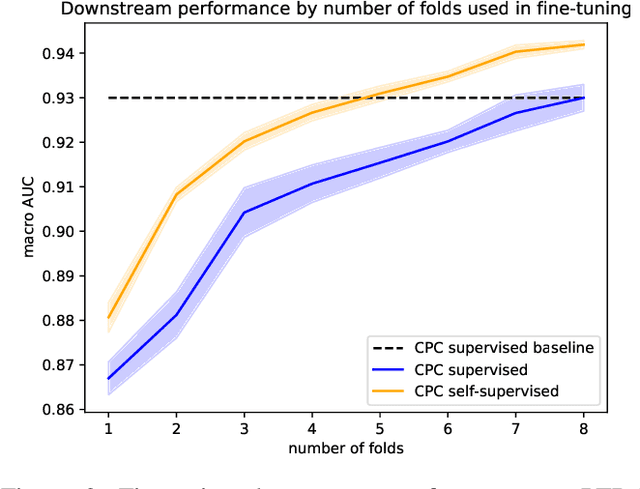
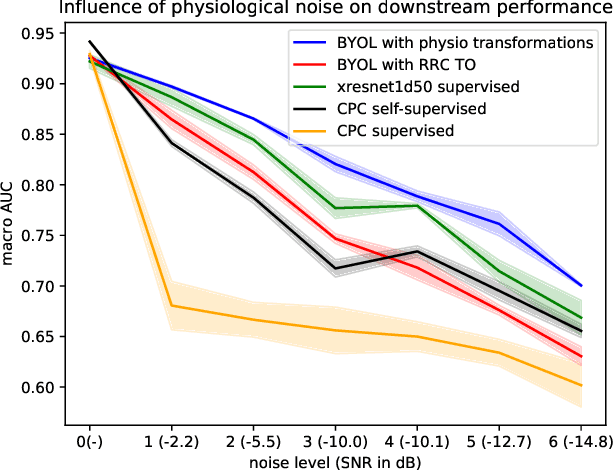
We put forward a comprehensive assessment of self-supervised representation learning from short segments of clinical 12-lead electrocardiography (ECG) data. To this end, we explore adaptations of state-of-the-art self-supervised learning algorithms from computer vision (SimCLR, BYOL, SwAV) and speech (CPC). In a first step, we learn contrastive representations and evaluate their quality based on linear evaluation performance on a downstream classification task. For the best-performing method, CPC, we find linear evaluation performances only 0.8% below supervised performance. In a second step, we analyze the impact of self-supervised pretraining on finetuned ECG classifiers as compared to purely supervised performance and find improvements in downstream performance of more than 1%, label efficiency, as well as an increased robustness against physiological noise. All experiments are carried out exclusively on publicly available datasets, the to-date largest collection used for self-supervised representation learning from ECG data, to foster reproducible research in the field of ECG representation learning.
Dithered backprop: A sparse and quantized backpropagation algorithm for more efficient deep neural network training
Apr 16, 2020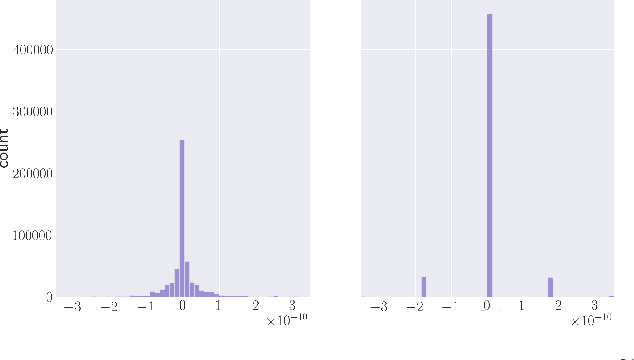
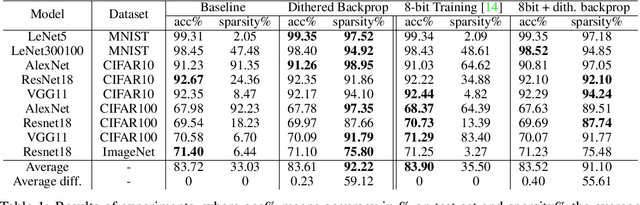
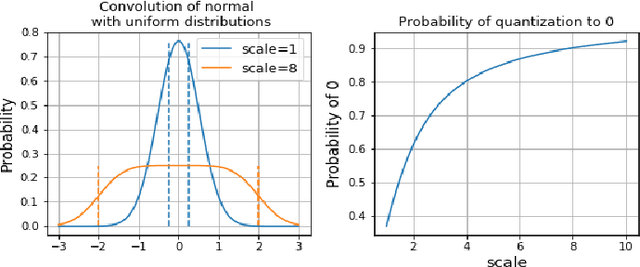
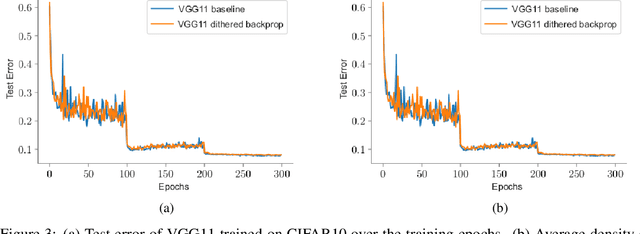
Deep Neural Networks are successful but highly computationally expensive learning systems. One of the main sources of time and energy drains is the well known backpropagation (backprop) algorithm, which roughly accounts for 2/3 of the computational complexity of training. In this work we propose a method for reducing the computational cost of backprop, which we named dithered backprop. It consists in applying a stochastic quantization scheme to intermediate results of the method. The particular quantisation scheme, called non-subtractive dither (NSD), induces sparsity which can be exploited by computing efficient sparse matrix multiplications. Experiments on popular image classification tasks show that it induces 92% sparsity on average across a wide set of models at no or negligible accuracy drop in comparison to state-of-the-art approaches, thus significantly reducing the computational complexity of the backward pass. Moreover, we show that our method is fully compatible to state-of-the-art training methods that reduce the bit-precision of training down to 8-bits, as such being able to further reduce the computational requirements. Finally we discuss and show potential benefits of applying dithered backprop in a distributed training setting, where both communication as well as compute efficiency may increase simultaneously with the number of participant nodes.