 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised representation learning from 12-lead ECG data
Paper and Code
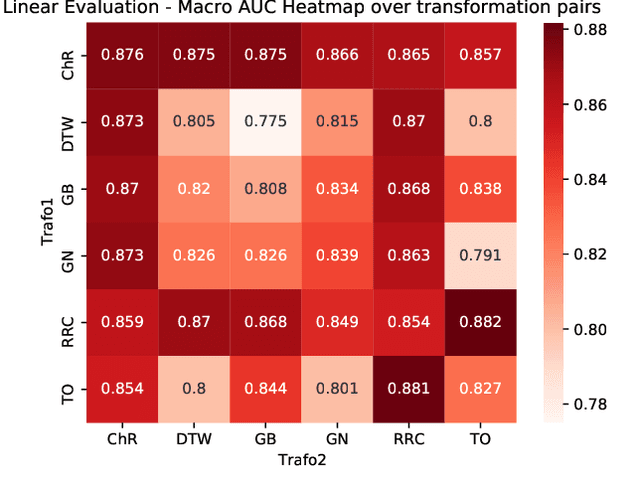

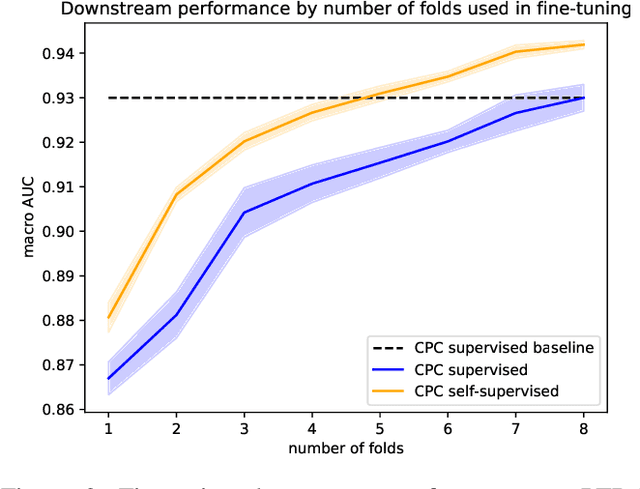
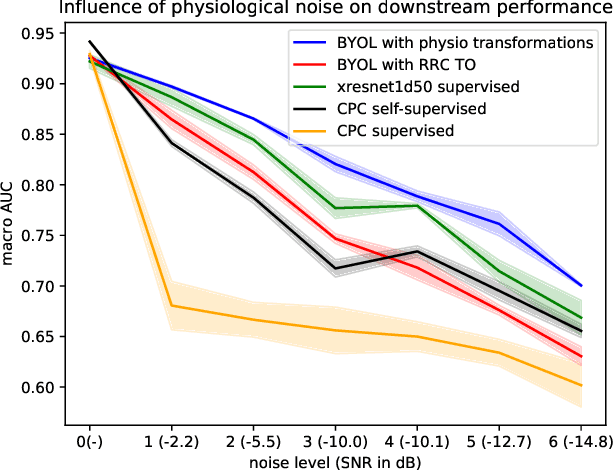
We put forward a comprehensive assessment of self-supervised representation learning from short segments of clinical 12-lead electrocardiography (ECG) data. To this end, we explore adaptations of state-of-the-art self-supervised learning algorithms from computer vision (SimCLR, BYOL, SwAV) and speech (CPC). In a first step, we learn contrastive representations and evaluate their quality based on linear evaluation performance on a downstream classification task. For the best-performing method, CPC, we find linear evaluation performances only 0.8% below supervised performance. In a second step, we analyze the impact of self-supervised pretraining on finetuned ECG classifiers as compared to purely supervised performance and find improvements in downstream performance of more than 1%, label efficiency, as well as an increased robustness against physiological noise. All experiments are carried out exclusively on publicly available datasets, the to-date largest collection used for self-supervised representation learning from ECG data, to foster reproducible research in the field of ECG representation learning.