 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Promise of Premise: Harnessing Question Premises in Visual Question Answering
Aug 17, 2017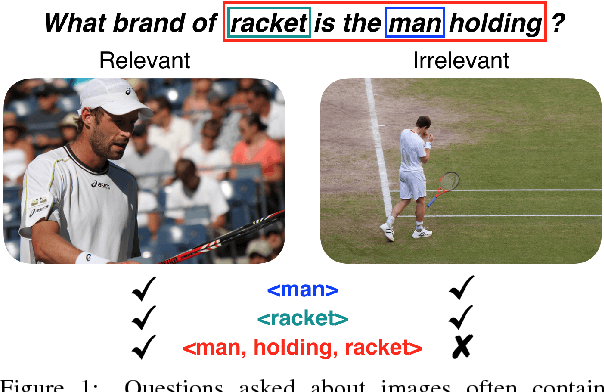
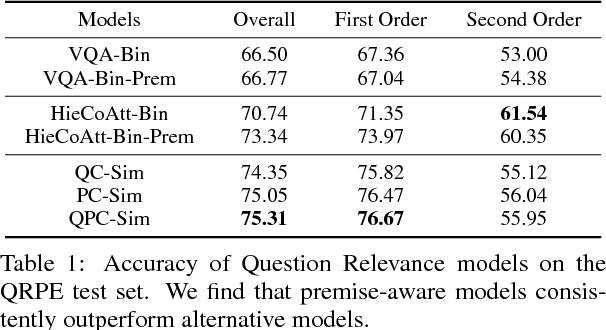


In this paper, we make a simple observation that questions about images often contain premises - objects and relationships implied by the question - and that reasoning about premises can help Visual Question Answering (VQA) models respond more intelligently to irrelevant or previously unseen questions. When presented with a question that is irrelevant to an image, state-of-the-art VQA models will still answer purely based on learned language biases, resulting in non-sensical or even misleading answers. We note that a visual question is irrelevant to an image if at least one of its premises is false (i.e. not depicted in the image). We leverage this observation to construct a dataset for Question Relevance Prediction and Explanation (QRPE) by searching for false premises. We train novel question relevance detection models and show that models that reason about premises consistently outperform models that do not. We also find that forcing standard VQA models to reason about premises during training can lead to improvements on tasks requiring compositional reasoning.
CloudCV: Large Scale Distributed Computer Vision as a Cloud Service
Feb 13, 2017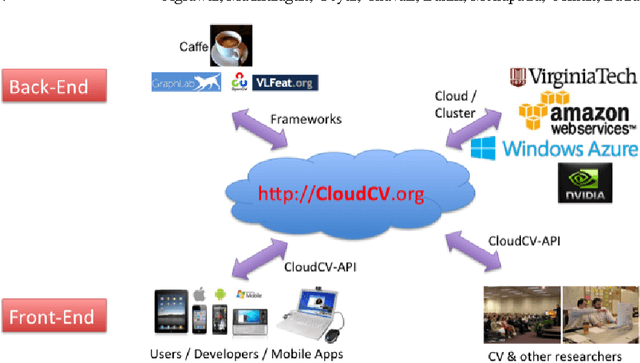
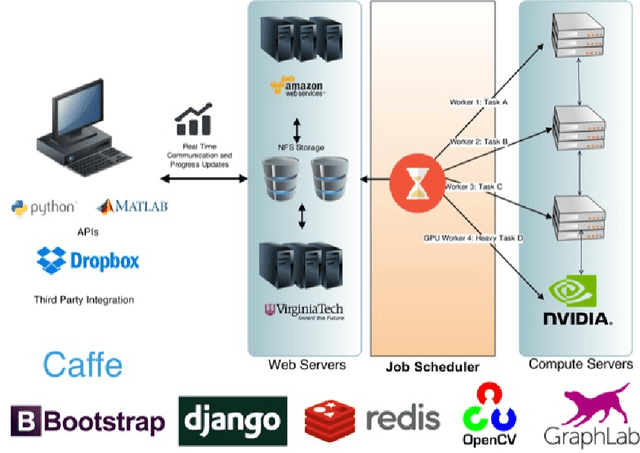
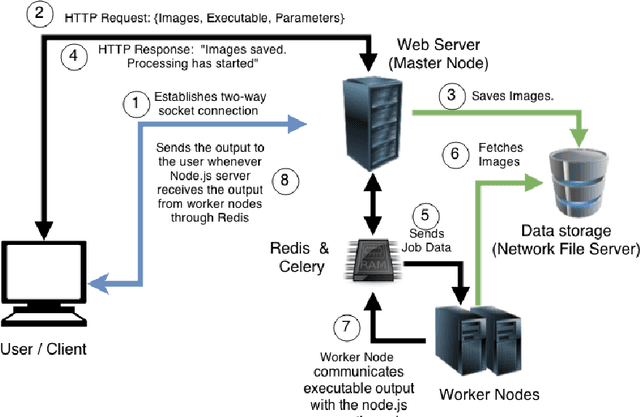
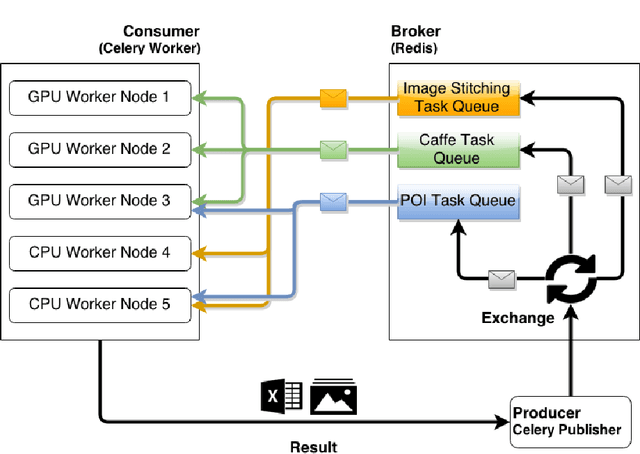
We are witnessing a proliferation of massive visual data. Unfortunately scaling existing computer vision algorithms to large datasets leaves researchers repeatedly solving the same algorithmic, logistical, and infrastructural problems. Our goal is to democratize computer vision; one should not have to be a computer vision, big data and distributed computing expert to have access to state-of-the-art distributed computer vision algorithms. We present CloudCV, a comprehensive system to provide access to state-of-the-art distributed computer vision algorithms as a cloud service through a Web Interface and APIs.
Towards Transparent AI Systems: Interpreting Visual Question Answering Models
Sep 09, 2016


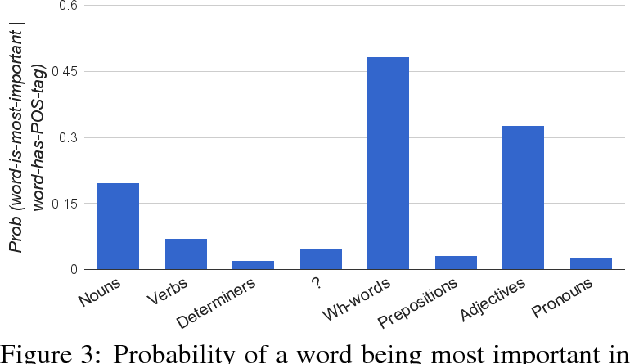
Deep neural networks have shown striking progress and obtained state-of-the-art results in many AI research fields in the recent years. However, it is often unsatisfying to not know why they predict what they do. In this paper, we address the problem of interpreting Visual Question Answering (VQA) models. Specifically, we are interested in finding what part of the input (pixels in images or words in questions) the VQA model focuses on while answering the question. To tackle this problem, we use two visualization techniques -- guided backpropagation and occlusion -- to find important words in the question and important regions in the image. We then present qualitative and quantitative analyses of these importance maps. We found that even without explicit attention mechanisms, VQA models may sometimes be implicitly attending to relevant regions in the image, and often to appropriate words in the question.