 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Recurrent Neural Network Explanations
Paper and Code

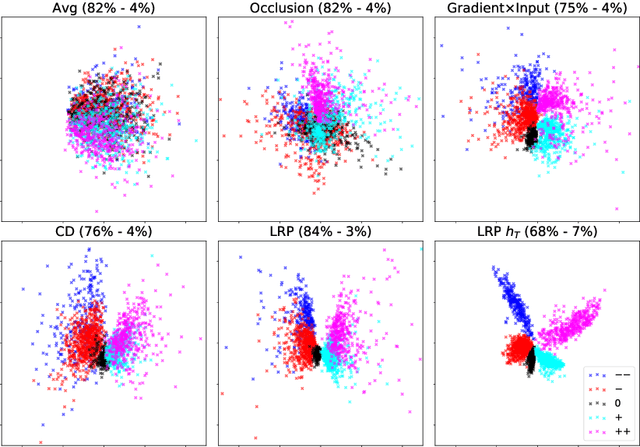
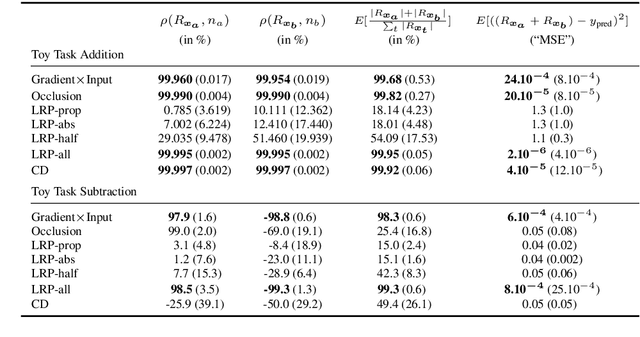

Recently, several methods have been proposed to explain the predictions of recurrent neural networks (RNNs), in particular of LSTMs. The goal of these methods is to understand the network's decisions by assigning to each input variable, e.g., a word, a relevance indicating to which extent it contributed to a particular prediction. In previous works, some of these methods were not yet compared to one another, or were evaluated only qualitatively. We close this gap by systematically and quantitatively comparing these methods in different settings, namely (1) a toy arithmetic task which we use as a sanity check, (2) a five-class sentiment prediction of movie reviews, and besides (3) we explore the usefulness of word relevances to build sentence-level representations. Lastly, using the method that performed best in our experiments, we show how specific linguistic phenomena such as the negation in sentiment analysis reflect in terms of relevance patterns, and how the relevance visualization can help to understand the misclassification of individual samples.