 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting Industrial Aging Processes with Machine Learning Methods
Feb 05, 2020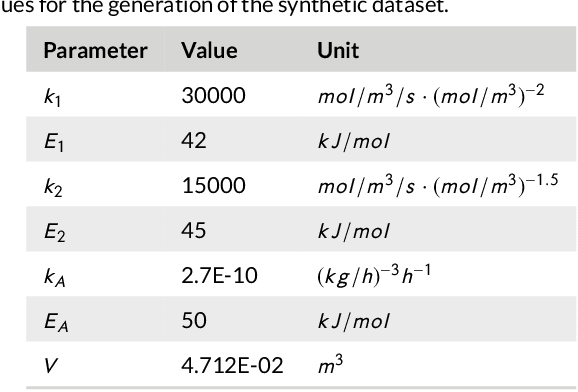
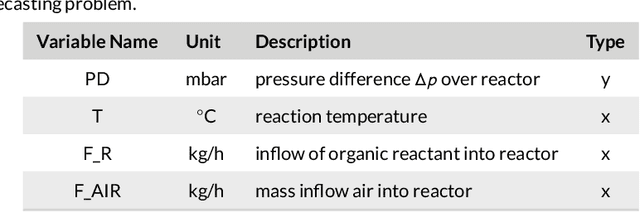


By accurately predicting industrial aging processes (IAPs), it is possible to schedule maintenance events further in advance, thereby ensuring a cost-efficient and reliable operation of the plant. So far, these degradation processes were usually described by mechanistic models or simple empirical prediction models. In this paper, we evaluate a wider range of data-driven models for this task, comparing some traditional stateless models (linear and kernel ridge regression, feed-forward neural networks) to more complex recurrent neural networks (echo state networks and LSTMs). To examine how much historical data is needed to train each of the models, we first examine their performance on a synthetic dataset with known dynamics. Next, the models are tested on real-world data from a large scale chemical plant. Our results show that LSTMs produce near perfect predictions when trained on a large enough dataset, while linear models may generalize better given small datasets with changing conditions.
The autofeat Python Library for Automatic Feature Engineering and Selection
Jan 22, 2019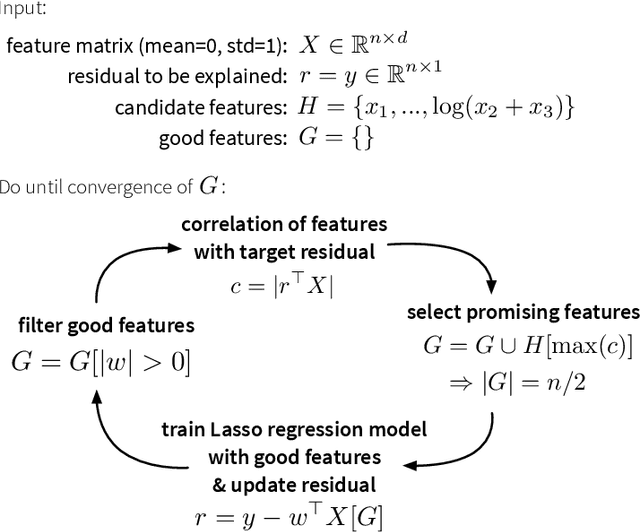



This paper describes the autofeat Python library, which provides a scikit-learn style linear regression model with automatic feature engineering and selection capabilities. Complex non-linear machine learning models such as neural networks are in practice often difficult to train and even harder to explain to non-statisticians, who require transparent analysis results as a basis for important business decisions. While linear models are efficient and intuitive, they generally provide lower prediction accuracies. Our library provides a multi-step feature engineering and selection process, where first a large pool of non-linear features is generated, from which then a small and robust set of meaningful features is selected, which improve the prediction accuracy of a linear model while retaining its interpretability.
Automating the search for a patent's prior art with a full text similarity search
Jan 10, 2019
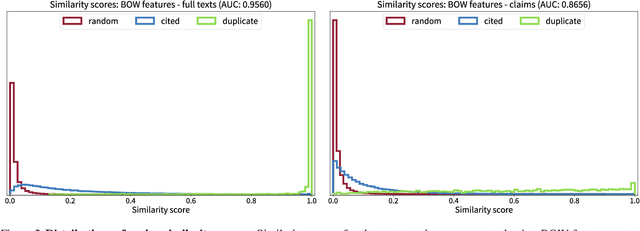
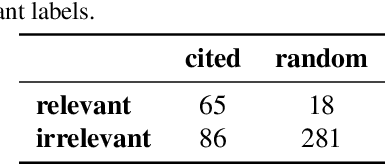
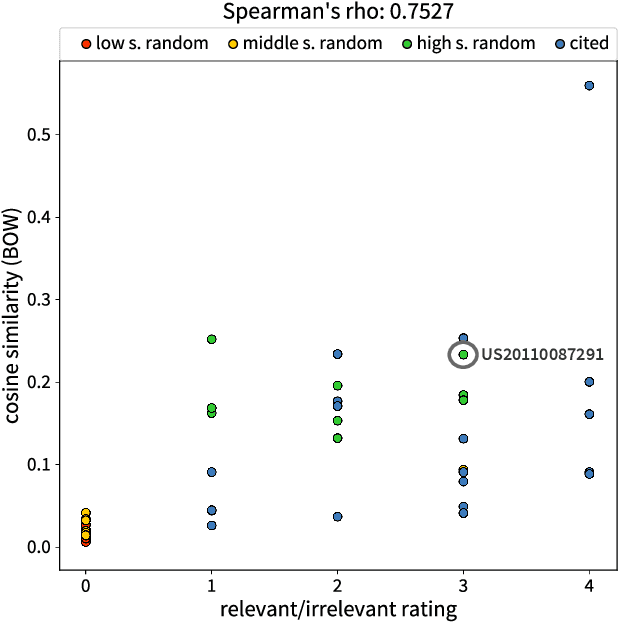
More than ever, technical inventions are the symbol of our society's advance. Patents guarantee their creators protection against infringement. For an invention being patentable, its novelty and inventiveness have to be assessed. Therefore, a search for published work that describes similar inventions to a given patent application needs to be performed. Currently, this so-called search for prior art is executed with semi-automatically composed keyword queries, which is not only time consuming, but also prone to errors. In particular, errors may systematically arise by the fact that different keywords for the same technical concepts may exist across disciplines. In this paper, a novel approach is proposed, where the full text of a given patent application is compared to existing patents using machine learning and natural language processing techniques to automatically detect inventions that are similar to the one described in the submitted document. Various state-of-the-art approaches for feature extraction and document comparison are evaluated. In addition to that, the quality of the current search process is assessed based on ratings of a domain expert. The evaluation results show that our automated approach, besides accelerating the search process, also improves the search results for prior art with respect to their quality.
Discovering topics in text datasets by visualizing relevant words
Jul 18, 2017

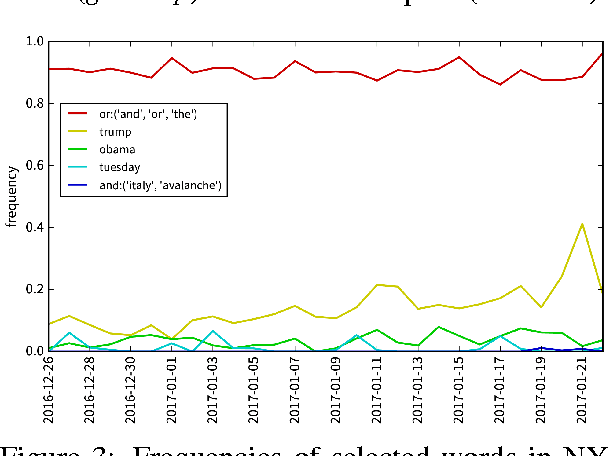

When dealing with large collections of documents, it is imperative to quickly get an overview of the texts' contents. In this paper we show how this can be achieved by using a clustering algorithm to identify topics in the dataset and then selecting and visualizing relevant words, which distinguish a group of documents from the rest of the texts, to summarize the contents of the documents belonging to each topic. We demonstrate our approach by discovering trending topics in a collection of New York Times article snippets.
Exploring text datasets by visualizing relevant words
Jul 17, 2017
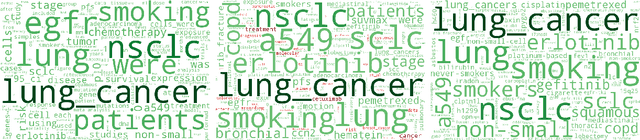
When working with a new dataset, it is important to first explore and familiarize oneself with it, before applying any advanced machine learning algorithms. However, to the best of our knowledge, no tools exist that quickly and reliably give insight into the contents of a selection of documents with respect to what distinguishes them from other documents belonging to different categories. In this paper we propose to extract `relevant words' from a collection of texts, which summarize the contents of documents belonging to a certain class (or discovered cluster in the case of unlabeled datasets), and visualize them in word clouds to allow for a survey of salient features at a glance. We compare three methods for extracting relevant words and demonstrate the usefulness of the resulting word clouds by providing an overview of the classes contained in a dataset of scientific publications as well as by discovering trending topics from recent New York Times article snippets.
Context encoders as a simple but powerful extension of word2vec
Jun 08, 2017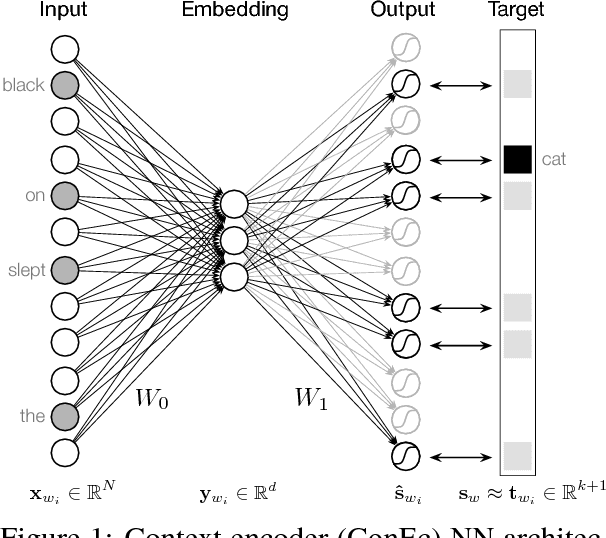

With a simple architecture and the ability to learn meaningful word embeddings efficiently from texts containing billions of words, word2vec remains one of the most popular neural language models used today. However, as only a single embedding is learned for every word in the vocabulary, the model fails to optimally represent words with multiple meanings. Additionally, it is not possible to create embeddings for new (out-of-vocabulary) words on the spot. Based on an intuitive interpretation of the continuous bag-of-words (CBOW) word2vec model's negative sampling training objective in terms of predicting context based similarities, we motivate an extension of the model we call context encoders (ConEc). By multiplying the matrix of trained word2vec embeddings with a word's average context vector, out-of-vocabulary (OOV) embeddings and representations for a word with multiple meanings can be created based on the word's local contexts. The benefits of this approach are illustrated by using these word embeddings as features in the CoNLL 2003 named entity recognition (NER) task.
Learning similarity preserving representations with neural similarity encoders
Feb 06, 2017

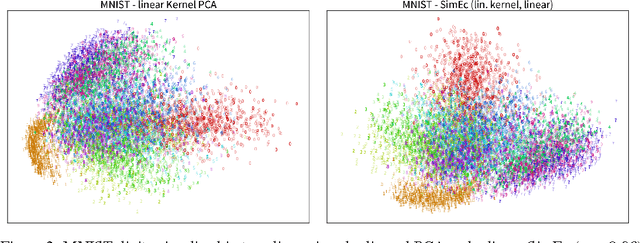
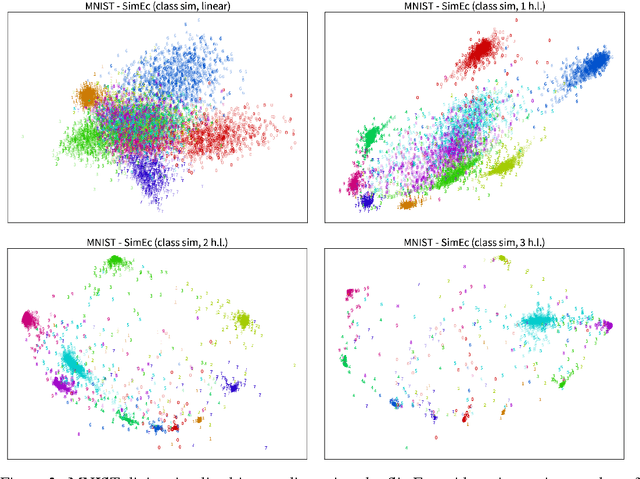
Many dimensionality reduction or manifold learning algorithms optimize for retaining the pairwise similarities, distances, or local neighborhoods of data points. Spectral methods like Kernel PCA (kPCA) or isomap achieve this by computing the singular value decomposition (SVD) of some similarity matrix to obtain a low dimensional representation of the original data. However, this is computationally expensive if a lot of training examples are available and, additionally, representations for new (out-of-sample) data points can only be created when the similarities to the original training examples can be computed. We introduce similarity encoders (SimEc), which learn similarity preserving representations by using a feed-forward neural network to map data into an embedding space where the original similarities can be approximated linearly. The model optimizes the same objective as kPCA but in the process it learns a linear or non-linear embedding function (in the form of the tuned neural network), with which the representations of novel data points can be computed - even if the original pairwise similarities of the training set were generated by an unknown process such as human ratings. By creating embeddings for both image and text datasets, we demonstrate that SimEc can, on the one hand, reach the same solution as spectral methods, and, on the other hand, obtain meaningful embeddings from similarities based on human labels.
"What is Relevant in a Text Document?": An Interpretable Machine Learning Approach
Dec 23, 2016


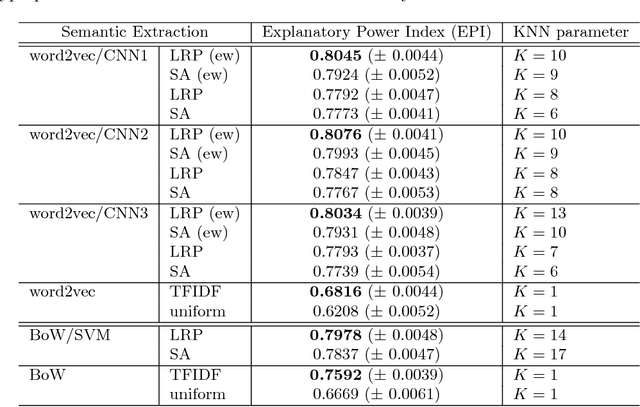
Text documents can be described by a number of abstract concepts such as semantic category, writing style, or sentiment. Machine learning (ML) models have been trained to automatically map documents to these abstract concepts, allowing to annotate very large text collections, more than could be processed by a human in a lifetime. Besides predicting the text's category very accurately, it is also highly desirable to understand how and why the categorization process takes place. In this paper, we demonstrate that such understanding can be achieved by tracing the classification decision back to individual words using layer-wise relevance propagation (LRP), a recently developed technique for explaining predictions of complex non-linear classifiers. We train two word-based ML models, a convolutional neural network (CNN) and a bag-of-words SVM classifier, on a topic categorization task and adapt the LRP method to decompose the predictions of these models onto words. Resulting scores indicate how much individual words contribute to the overall classification decision. This enables one to distill relevant information from text documents without an explicit semantic information extraction step. We further use the word-wise relevance scores for generating novel vector-based document representations which capture semantic information. Based on these document vectors, we introduce a measure of model explanatory power and show that, although the SVM and CNN models perform similarly in terms of classification accuracy, the latter exhibits a higher level of explainability which makes it more comprehensible for humans and potentially more useful for other applications.
Explaining Predictions of Non-Linear Classifiers in NLP
Jun 23, 2016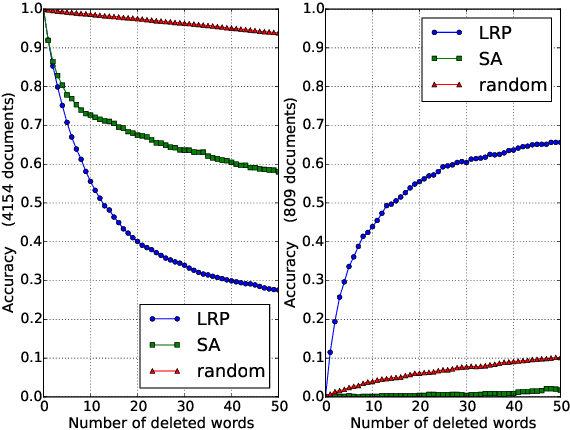

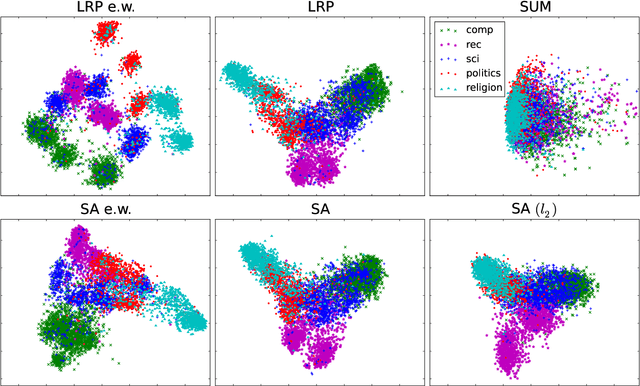
Layer-wise relevance propagation (LRP) is a recently proposed technique for explaining predictions of complex non-linear classifiers in terms of input variables. In this paper, we apply LRP for the first time to natural language processing (NLP). More precisely, we use it to explain the predictions of a convolutional neural network (CNN) trained on a topic categorization task. Our analysis highlights which words are relevant for a specific prediction of the CNN. We compare our technique to standard sensitivity analysis, both qualitatively and quantitatively, using a "word deleting" perturbation experiment, a PCA analysis, and various visualizations. All experiments validate the suitability of LRP for explaining the CNN predictions, which is also in line with results reported in recent image classification studies.