 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving 3D deep learning segmentation with biophysically motivated cell synthesis
Aug 29, 2024Biomedical research increasingly relies on 3D cell culture models and AI-based analysis can potentially facilitate a detailed and accurate feature extraction on a single-cell level. However, this requires for a precise segmentation of 3D cell datasets, which in turn demands high-quality ground truth for training. Manual annotation, the gold standard for ground truth data, is too time-consuming and thus not feasible for the generation of large 3D training datasets. To address this, we present a novel framework for generating 3D training data, which integrates biophysical modeling for realistic cell shape and alignment. Our approach allows the in silico generation of coherent membrane and nuclei signals, that enable the training of segmentation models utilizing both channels for improved performance. Furthermore, we present a new GAN training scheme that generates not only image data but also matching labels. Quantitative evaluation shows superior performance of biophysical motivated synthetic training data, even outperforming manual annotation and pretrained models. This underscores the potential of incorporating biophysical modeling for enhancing synthetic training data quality.
Forecasting Industrial Aging Processes with Machine Learning Methods
Feb 05, 2020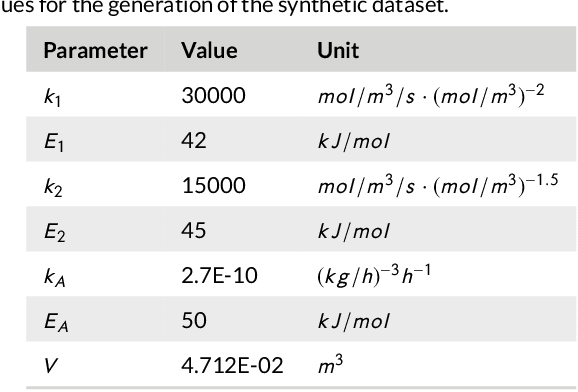
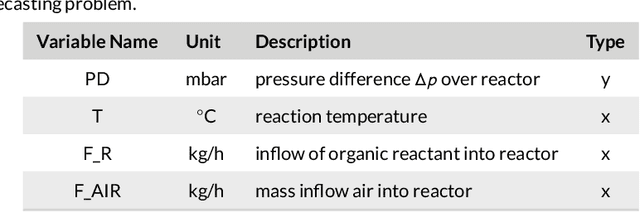


By accurately predicting industrial aging processes (IAPs), it is possible to schedule maintenance events further in advance, thereby ensuring a cost-efficient and reliable operation of the plant. So far, these degradation processes were usually described by mechanistic models or simple empirical prediction models. In this paper, we evaluate a wider range of data-driven models for this task, comparing some traditional stateless models (linear and kernel ridge regression, feed-forward neural networks) to more complex recurrent neural networks (echo state networks and LSTMs). To examine how much historical data is needed to train each of the models, we first examine their performance on a synthetic dataset with known dynamics. Next, the models are tested on real-world data from a large scale chemical plant. Our results show that LSTMs produce near perfect predictions when trained on a large enough dataset, while linear models may generalize better given small datasets with changing conditions.