 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext encoders as a simple but powerful extension of word2vec
Paper and Code
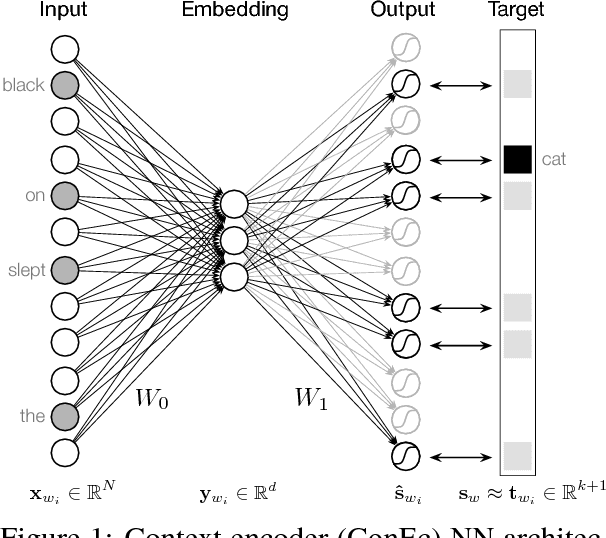

With a simple architecture and the ability to learn meaningful word embeddings efficiently from texts containing billions of words, word2vec remains one of the most popular neural language models used today. However, as only a single embedding is learned for every word in the vocabulary, the model fails to optimally represent words with multiple meanings. Additionally, it is not possible to create embeddings for new (out-of-vocabulary) words on the spot. Based on an intuitive interpretation of the continuous bag-of-words (CBOW) word2vec model's negative sampling training objective in terms of predicting context based similarities, we motivate an extension of the model we call context encoders (ConEc). By multiplying the matrix of trained word2vec embeddings with a word's average context vector, out-of-vocabulary (OOV) embeddings and representations for a word with multiple meanings can be created based on the word's local contexts. The benefits of this approach are illustrated by using these word embeddings as features in the CoNLL 2003 named entity recognition (NER) task.