 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Giraffes in a Dirt Field: Using Game Play to Investigate Situation Modelling in Large Multimodal Models
Jun 20, 2024



While the situation has improved for text-only models, it again seems to be the case currently that multimodal (text and image) models develop faster than ways to evaluate them. In this paper, we bring a recently developed evaluation paradigm from text models to multimodal models, namely evaluation through the goal-oriented game (self) play, complementing reference-based and preference-based evaluation. Specifically, we define games that challenge a model's capability to represent a situation from visual information and align such representations through dialogue. We find that the largest closed models perform rather well on the games that we define, while even the best open-weight models struggle with them. On further analysis, we find that the exceptional deep captioning capabilities of the largest models drive some of the performance. There is still room to grow for both kinds of models, ensuring the continued relevance of the benchmark.
clembench-2024: A Challenging, Dynamic, Complementary, Multilingual Benchmark and Underlying Flexible Framework for LLMs as Multi-Action Agents
May 31, 2024



It has been established in recent work that Large Language Models (LLMs) can be prompted to "self-play" conversational games that probe certain capabilities (general instruction following, strategic goal orientation, language understanding abilities), where the resulting interactive game play can be automatically scored. In this paper, we take one of the proposed frameworks for setting up such game-play environments, and further test its usefulness as an evaluation instrument, along a number of dimensions: We show that it can easily keep up with new developments while avoiding data contamination, we show that the tests implemented within it are not yet saturated (human performance is substantially higher than that of even the best models), and we show that it lends itself to investigating additional questions, such as the impact of the prompting language on performance. We believe that the approach forms a good basis for making decisions on model choice for building applied interactive systems, and perhaps ultimately setting up a closed-loop development environment of system and simulated evaluator.
Neural Conversation Models and How to Rein Them in: A Survey of Failures and Fixes
Aug 11, 2023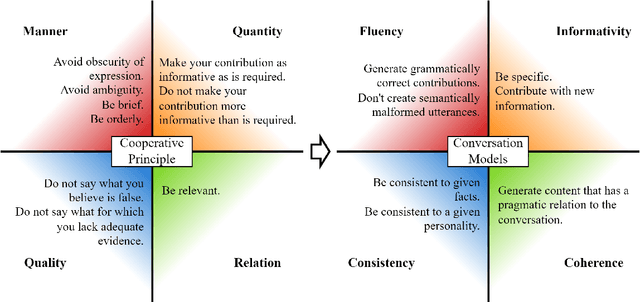
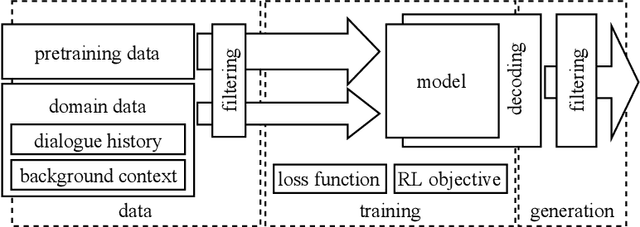
Recent conditional language models are able to continue any kind of text source in an often seemingly fluent way. This fact encouraged research in the area of open-domain conversational systems that are based on powerful language models and aim to imitate an interlocutor by generating appropriate contributions to a written dialogue. From a linguistic perspective, however, the complexity of contributing to a conversation is high. In this survey, we interpret Grice's maxims of cooperative conversation from the perspective of this specific research area and systematize the literature under the aspect of what makes a contribution appropriate: A neural conversation model has to be fluent, informative, consistent, coherent, and follow social norms. In order to ensure these qualities, recent approaches try to tame the underlying language models at various intervention points, such as data, training regime or decoding. Sorted by these categories and intervention points, we discuss promising attempts and suggest novel ways for future research.
Is Incoherence Surprising? Targeted Evaluation of Coherence Prediction from Language Models
May 07, 2021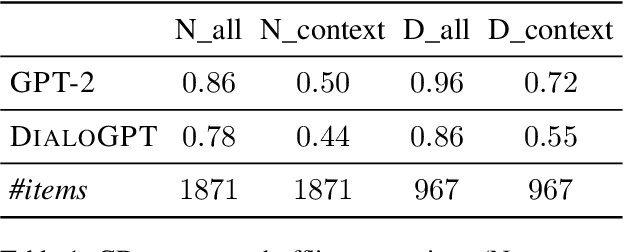
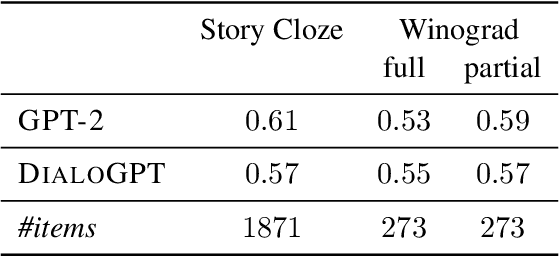
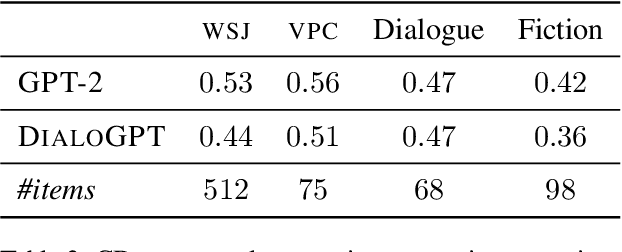
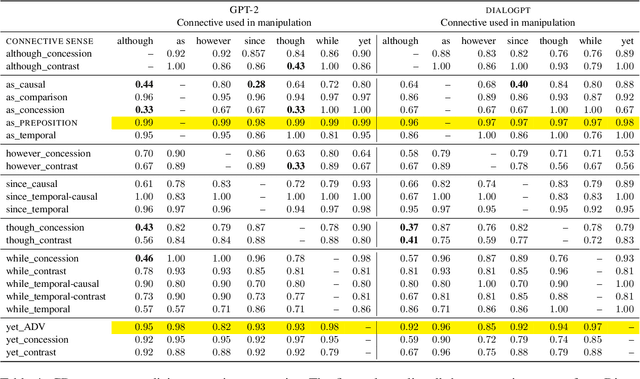
Coherent discourse is distinguished from a mere collection of utterances by the satisfaction of a diverse set of constraints, for example choice of expression, logical relation between denoted events, and implicit compatibility with world-knowledge. Do neural language models encode such constraints? We design an extendable set of test suites addressing different aspects of discourse and dialogue coherence. Unlike most previous coherence evaluation studies, we address specific linguistic devices beyond sentence order perturbations, allowing for a more fine-grained analysis of what constitutes coherence and what neural models trained on a language modelling objective do encode. Extending the targeted evaluation paradigm for neural language models (Marvin and Linzen, 2018) to phenomena beyond syntax, we show that this paradigm is equally suited to evaluate linguistic qualities that contribute to the notion of coherence.