 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlant in Cupboard, Orange on Table, Book on Shelf. Benchmarking Practical Reasoning and Situation Modelling in a Text-Simulated Situated Environment
Feb 17, 2025



Large language models (LLMs) have risen to prominence as 'chatbots' for users to interact via natural language. However, their abilities to capture common-sense knowledge make them seem promising as language-based planners of situated or embodied action as well. We have implemented a simple text-based environment -- similar to others that have before been used for reinforcement-learning of agents -- that simulates, very abstractly, a household setting. We use this environment and the detailed error-tracking capabilities we implemented for targeted benchmarking of LLMs on the problem of practical reasoning: Going from goals and observations to actions. Our findings show that environmental complexity and game restrictions hamper performance, and concise action planning is demanding for current LLMs.
How Many Parameters Does it Take to Change a Light Bulb? Evaluating Performance in Self-Play of Conversational Games as a Function of Model Characteristics
Jun 20, 2024
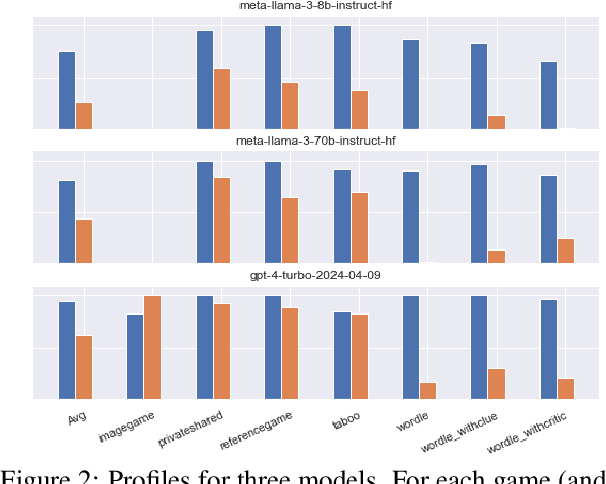


What makes a good Large Language Model (LLM)? That it performs well on the relevant benchmarks -- which hopefully measure, with some validity, the presence of capabilities that are also challenged in real application. But what makes the model perform well? What gives a model its abilities? We take a recently introduced type of benchmark that is meant to challenge capabilities in a goal-directed, agentive context through self-play of conversational games, and analyse how performance develops as a function of model characteristics like number of parameters, or type of training. We find that while there is a clear relationship between number of parameters and performance, there is still a wide spread of performance points within a given size bracket, which is to be accounted for by training parameters such as fine-tuning data quality and method. From a more practical angle, we also find a certain degree of unpredictability about performance across access methods, possible due to unexposed sampling parameters, and a, very welcome, performance stability against at least moderate weight quantisation during inference.