 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics Informed Generative AI Enabling Labour Free Segmentation For Microscopy Analysis
Feb 02, 2026Semantic segmentation of microscopy images is a critical task for high-throughput materials characterisation, yet its automation is severely constrained by the prohibitive cost, subjectivity, and scarcity of expert-annotated data. While physics-based simulations offer a scalable alternative to manual labelling, models trained on such data historically fail to generalise due to a significant domain gap, lacking the complex textures, noise patterns, and imaging artefacts inherent to experimental data. This paper introduces a novel framework for labour-free segmentation that successfully bridges this simulation-to-reality gap. Our pipeline leverages phase-field simulations to generate an abundant source of microstructural morphologies with perfect, intrinsically-derived ground-truth masks. We then employ a Cycle-Consistent Generative Adversarial Network (CycleGAN) for unpaired image-to-image translation, transforming the clean simulations into a large-scale dataset of high-fidelity, realistic SEM images. A U-Net model, trained exclusively on this synthetic data, demonstrated remarkable generalisation when deployed on unseen experimental images, achieving a mean Boundary F1-Score of 0.90 and an Intersection over Union (IOU) of 0.88. Comprehensive validation using t-SNE feature-space projection and Shannon entropy analysis confirms that our synthetic images are statistically and featurally indistinguishable from the real data manifold. By completely decoupling model training from manual annotation, our generative framework transforms a data-scarce problem into one of data abundance, providing a robust and fully automated solution to accelerate materials discovery and analysis.
Moral Lenses, Political Coordinates: Towards Ideological Positioning of Morally Conditioned LLMs
Jan 13, 2026While recent research has systematically documented political orientation in large language models (LLMs), existing evaluations rely primarily on direct probing or demographic persona engineering to surface ideological biases. In social psychology, however, political ideology is also understood as a downstream consequence of fundamental moral intuitions. In this work, we investigate the causal relationship between moral values and political positioning by treating moral orientation as a controllable condition. Rather than simply assigning a demographic persona, we condition models to endorse or reject specific moral values and evaluate the resulting shifts on their political orientations, using the Political Compass Test. By treating moral values as lenses, we observe how moral conditioning actively steers model trajectories across economic and social dimensions. Our findings show that such conditioning induces pronounced, value-specific shifts in models' political coordinates. We further notice that these effects are systematically modulated by role framing and model scale, and are robust across alternative assessment instruments instantiating the same moral value. This highlights that effective alignment requires anchoring political assessments within the context of broader social values including morality, paving the way for more socially grounded alignment techniques.
Probabilistic Aggregation and Targeted Embedding Optimization for Collective Moral Reasoning in Large Language Models
Jun 18, 2025Large Language Models (LLMs) have shown impressive moral reasoning abilities. Yet they often diverge when confronted with complex, multi-factor moral dilemmas. To address these discrepancies, we propose a framework that synthesizes multiple LLMs' moral judgments into a collectively formulated moral judgment, realigning models that deviate significantly from this consensus. Our aggregation mechanism fuses continuous moral acceptability scores (beyond binary labels) into a collective probability, weighting contributions by model reliability. For misaligned models, a targeted embedding-optimization procedure fine-tunes token embeddings for moral philosophical theories, minimizing JS divergence to the consensus while preserving semantic integrity. Experiments on a large-scale social moral dilemma dataset show our approach builds robust consensus and improves individual model fidelity. These findings highlight the value of data-driven moral alignment across multiple models and its potential for safer, more consistent AI systems.
P-TA: Using Proximal Policy Optimization to Enhance Tabular Data Augmentation via Large Language Models
Jun 17, 2024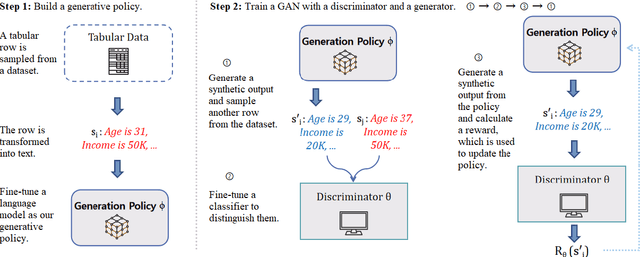



A multitude of industries depend on accurate and reasonable tabular data augmentation for their business processes. Contemporary methodologies in generating tabular data revolve around utilizing Generative Adversarial Networks (GAN) or fine-tuning Large Language Models (LLM). However, GAN-based approaches are documented to produce samples with common-sense errors attributed to the absence of external knowledge. On the other hand, LLM-based methods exhibit a limited capacity to capture the disparities between synthesized and actual data distribution due to the absence of feedback from a discriminator during training. Furthermore, the decoding of LLM-based generation introduces gradient breakpoints, impeding the backpropagation of loss from a discriminator, thereby complicating the integration of these two approaches. To solve this challenge, we propose using proximal policy optimization (PPO) to apply GANs, guiding LLMs to enhance the probability distribution of tabular features. This approach enables the utilization of LLMs as generators for GANs in synthesizing tabular data. Our experiments demonstrate that PPO leads to an approximately 4\% improvement in the accuracy of models trained on synthetically generated data over state-of-the-art across three real-world datasets.