 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Uncertainty Sets: Leveraging Optimal Transport to Extend Conformal Predictive Distribution to Multivariate Settings
Nov 19, 2025Conformal prediction (CP) constructs uncertainty sets for model outputs with finite-sample coverage guarantees. A candidate output is included in the prediction set if its non-conformity score is not considered extreme relative to the scores observed on a set of calibration examples. However, this procedure is only straightforward when scores are scalar-valued, which has limited CP to real-valued scores or ad-hoc reductions to one dimension. The problem of ordering vectors has been studied via optimal transport (OT), which provides a principled method for defining vector-ranks and multivariate quantile regions, though typically with only asymptotic coverage guarantees. We restore finite-sample, distribution-free coverage by conformalizing the vector-valued OT quantile region. Here, a candidate's rank is defined via a transport map computed for the calibration scores augmented with that candidate's score. This defines a continuum of OT problems for which we prove that the resulting optimal assignment is piecewise-constant across a fixed polyhedral partition of the score space. This allows us to characterize the entire prediction set tractably, and provides the machinery to address a deeper limitation of prediction sets: that they only indicate which outcomes are plausible, but not their relative likelihood. In one dimension, conformal predictive distributions (CPDs) fill this gap by producing a predictive distribution with finite-sample calibration. Extending CPDs beyond one dimension remained an open problem. We construct, to our knowledge, the first multivariate CPDs with finite-sample calibration, i.e., they define a valid multivariate distribution where any derived uncertainty region automatically has guaranteed coverage. We present both conservative and exact randomized versions, the latter resulting in a multivariate generalization of the classical Dempster-Hill procedure.
Trained on Tokens, Calibrated on Concepts: The Emergence of Semantic Calibration in LLMs
Nov 06, 2025Large Language Models (LLMs) often lack meaningful confidence estimates for their outputs. While base LLMs are known to exhibit next-token calibration, it remains unclear whether they can assess confidence in the actual meaning of their responses beyond the token level. We find that, when using a certain sampling-based notion of semantic calibration, base LLMs are remarkably well-calibrated: they can meaningfully assess confidence in open-domain question-answering tasks, despite not being explicitly trained to do so. Our main theoretical contribution establishes a mechanism for why semantic calibration emerges as a byproduct of next-token prediction, leveraging a recent connection between calibration and local loss optimality. The theory relies on a general definition of "B-calibration," which is a notion of calibration parameterized by a choice of equivalence classes (semantic or otherwise). This theoretical mechanism leads to a testable prediction: base LLMs will be semantically calibrated when they can easily predict their own distribution over semantic answer classes before generating a response. We state three implications of this prediction, which we validate through experiments: (1) Base LLMs are semantically calibrated across question-answering tasks, (2) RL instruction-tuning systematically breaks this calibration, and (3) chain-of-thought reasoning breaks calibration. To our knowledge, our work provides the first principled explanation of when and why semantic calibration emerges in LLMs.
The Geometries of Truth Are Orthogonal Across Tasks
Jun 10, 2025Large Language Models (LLMs) have demonstrated impressive generalization capabilities across various tasks, but their claim to practical relevance is still mired by concerns on their reliability. Recent works have proposed examining the activations produced by an LLM at inference time to assess whether its answer to a question is correct. Some works claim that a "geometry of truth" can be learned from examples, in the sense that the activations that generate correct answers can be distinguished from those leading to mistakes with a linear classifier. In this work, we underline a limitation of these approaches: we observe that these "geometries of truth" are intrinsically task-dependent and fail to transfer across tasks. More precisely, we show that linear classifiers trained across distinct tasks share little similarity and, when trained with sparsity-enforcing regularizers, have almost disjoint supports. We show that more sophisticated approaches (e.g., using mixtures of probes and tasks) fail to overcome this limitation, likely because activation vectors commonly used to classify answers form clearly separated clusters when examined across tasks.
Multivariate Conformal Prediction using Optimal Transport
Feb 05, 2025



Conformal prediction (CP) quantifies the uncertainty of machine learning models by constructing sets of plausible outputs. These sets are constructed by leveraging a so-called conformity score, a quantity computed using the input point of interest, a prediction model, and past observations. CP sets are then obtained by evaluating the conformity score of all possible outputs, and selecting them according to the rank of their scores. Due to this ranking step, most CP approaches rely on a score functions that are univariate. The challenge in extending these scores to multivariate spaces lies in the fact that no canonical order for vectors exists. To address this, we leverage a natural extension of multivariate score ranking based on optimal transport (OT). Our method, OTCP, offers a principled framework for constructing conformal prediction sets in multidimensional settings, preserving distribution-free coverage guarantees with finite data samples. We demonstrate tangible gains in a benchmark dataset of multivariate regression problems and address computational \& statistical trade-offs that arise when estimating conformity scores through OT maps.
Sparse Repellency for Shielded Generation in Text-to-image Diffusion Models
Oct 10, 2024
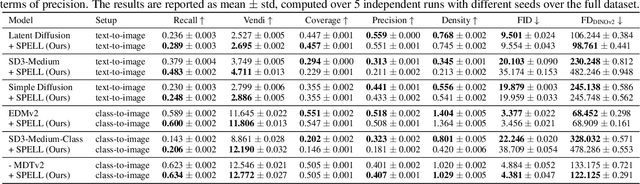
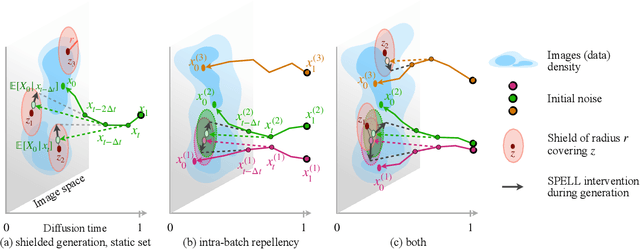
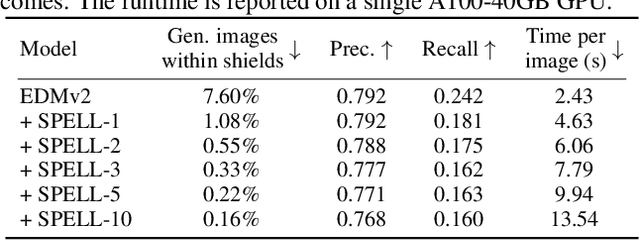
The increased adoption of diffusion models in text-to-image generation has triggered concerns on their reliability. Such models are now closely scrutinized under the lens of various metrics, notably calibration, fairness, or compute efficiency. We focus in this work on two issues that arise when deploying these models: a lack of diversity when prompting images, and a tendency to recreate images from the training set. To solve both problems, we propose a method that coaxes the sampled trajectories of pretrained diffusion models to land on images that fall outside of a reference set. We achieve this by adding repellency terms to the diffusion SDE throughout the generation trajectory, which are triggered whenever the path is expected to land too closely to an image in the shielded reference set. Our method is sparse in the sense that these repellency terms are zero and inactive most of the time, and even more so towards the end of the generation trajectory. Our method, named SPELL for sparse repellency, can be used either with a static reference set that contains protected images, or dynamically, by updating the set at each timestep with the expected images concurrently generated within a batch. We show that adding SPELL to popular diffusion models improves their diversity while impacting their FID only marginally, and performs comparatively better than other recent training-free diversity methods. We also demonstrate how SPELL can ensure a shielded generation away from a very large set of protected images by considering all 1.2M images from ImageNet as the protected set.
From Conformal Predictions to Confidence Regions
May 28, 2024Conformal prediction methodologies have significantly advanced the quantification of uncertainties in predictive models. Yet, the construction of confidence regions for model parameters presents a notable challenge, often necessitating stringent assumptions regarding data distribution or merely providing asymptotic guarantees. We introduce a novel approach termed CCR, which employs a combination of conformal prediction intervals for the model outputs to establish confidence regions for model parameters. We present coverage guarantees under minimal assumptions on noise and that is valid in finite sample regime. Our approach is applicable to both split conformal predictions and black-box methodologies including full or cross-conformal approaches. In the specific case of linear models, the derived confidence region manifests as the feasible set of a Mixed-Integer Linear Program (MILP), facilitating the deduction of confidence intervals for individual parameters and enabling robust optimization. We empirically compare CCR to recent advancements in challenging settings such as with heteroskedastic and non-Gaussian noise.
Conformal Prediction via Regression-as-Classification
Apr 12, 2024Conformal prediction (CP) for regression can be challenging, especially when the output distribution is heteroscedastic, multimodal, or skewed. Some of the issues can be addressed by estimating a distribution over the output, but in reality, such approaches can be sensitive to estimation error and yield unstable intervals.~Here, we circumvent the challenges by converting regression to a classification problem and then use CP for classification to obtain CP sets for regression.~To preserve the ordering of the continuous-output space, we design a new loss function and make necessary modifications to the CP classification techniques.~Empirical results on many benchmarks shows that this simple approach gives surprisingly good results on many practical problems.
* International Conference of Learning Representations 2024
Careful with that Scalpel: Improving Gradient Surgery with an EMA
Feb 05, 2024



Beyond minimizing a single training loss, many deep learning estimation pipelines rely on an auxiliary objective to quantify and encourage desirable properties of the model (e.g. performance on another dataset, robustness, agreement with a prior). Although the simplest approach to incorporating an auxiliary loss is to sum it with the training loss as a regularizer, recent works have shown that one can improve performance by blending the gradients beyond a simple sum; this is known as gradient surgery. We cast the problem as a constrained minimization problem where the auxiliary objective is minimized among the set of minimizers of the training loss. To solve this bilevel problem, we follow a parameter update direction that combines the training loss gradient and the orthogonal projection of the auxiliary gradient to the training gradient. In a setting where gradients come from mini-batches, we explain how, using a moving average of the training loss gradients, we can carefully maintain this critical orthogonality property. We demonstrate that our method, Bloop, can lead to much better performances on NLP and vision experiments than other gradient surgery methods without EMA.
Finite Sample Confidence Regions for Linear Regression Parameters Using Arbitrary Predictors
Jan 27, 2024We explore a novel methodology for constructing confidence regions for parameters of linear models, using predictions from any arbitrary predictor. Our framework requires minimal assumptions on the noise and can be extended to functions deviating from strict linearity up to some adjustable threshold, thereby accommodating a comprehensive and pragmatically relevant set of functions. The derived confidence regions can be cast as constraints within a Mixed Integer Linear Programming framework, enabling optimisation of linear objectives. This representation enables robust optimization and the extraction of confidence intervals for specific parameter coordinates. Unlike previous methods, the confidence region can be empty, which can be used for hypothesis testing. Finally, we validate the empirical applicability of our method on synthetic data.
Revisiting Non-separable Binary Classification and its Applications in Anomaly Detection
Dec 03, 2023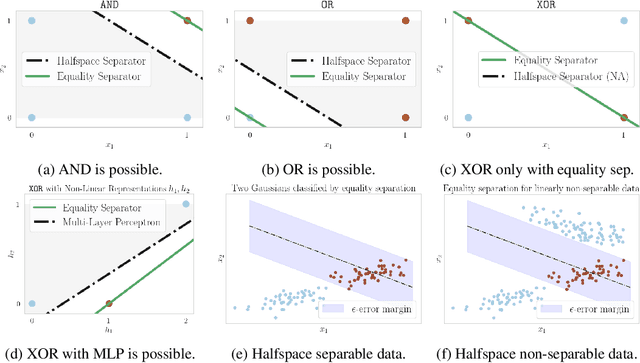

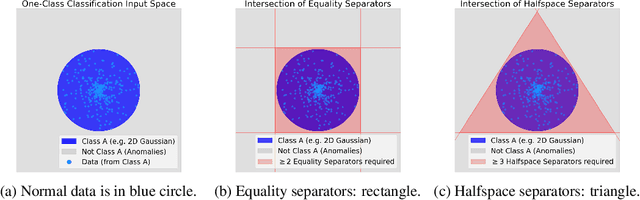
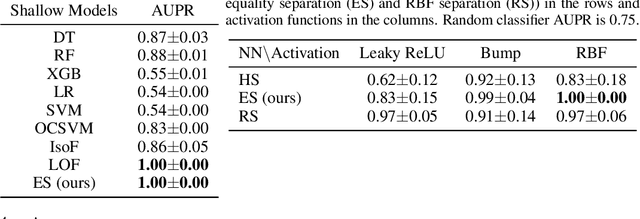
The inability to linearly classify XOR has motivated much of deep learning. We revisit this age-old problem and show that linear classification of XOR is indeed possible. Instead of separating data between halfspaces, we propose a slightly different paradigm, equality separation, that adapts the SVM objective to distinguish data within or outside the margin. Our classifier can then be integrated into neural network pipelines with a smooth approximation. From its properties, we intuit that equality separation is suitable for anomaly detection. To formalize this notion, we introduce closing numbers, a quantitative measure on the capacity for classifiers to form closed decision regions for anomaly detection. Springboarding from this theoretical connection between binary classification and anomaly detection, we test our hypothesis on supervised anomaly detection experiments, showing that equality separation can detect both seen and unseen anomalies.