 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharing Network Parameters for Crosslingual Named Entity Recognition
Paper and Code
Jul 01, 2016


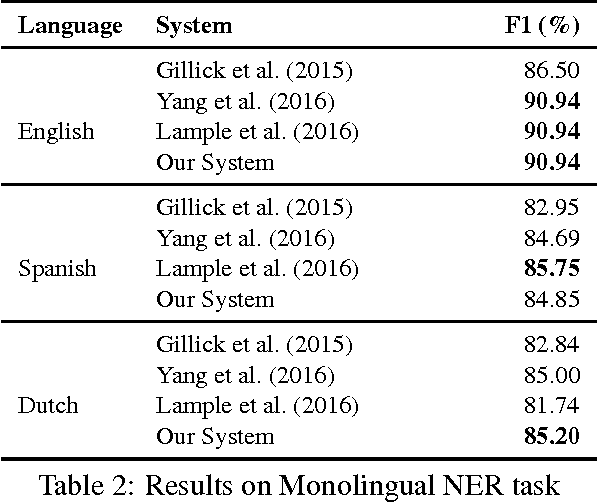
Most state of the art approaches for Named Entity Recognition rely on hand crafted features and annotated corpora. Recently Neural network based models have been proposed which do not require handcrafted features but still require annotated corpora. However, such annotated corpora may not be available for many languages. In this paper, we propose a neural network based model which allows sharing the decoder as well as word and character level parameters between two languages thereby allowing a resource fortunate language to aid a resource deprived language. Specifically, we focus on the case when limited annotated corpora is available in one language ($L_1$) and abundant annotated corpora is available in another language ($L_2$). Sharing the network architecture and parameters between $L_1$ and $L_2$ leads to improved performance in $L_1$. Further, our approach does not require any hand crafted features but instead directly learns meaningful feature representations from the training data itself. We experiment with 4 language pairs and show that indeed in a resource constrained setup (lesser annotated corpora), a model jointly trained with data from another language performs better than a model trained only on the limited corpora in one language.