 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenHands: Making Sign Language Recognition Accessible with Pose-based Pretrained Models across Languages
Paper and Code
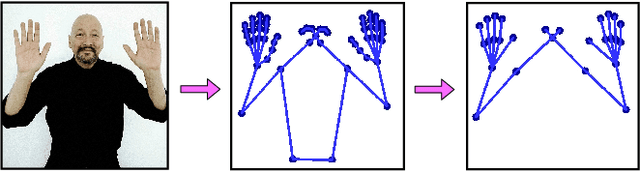
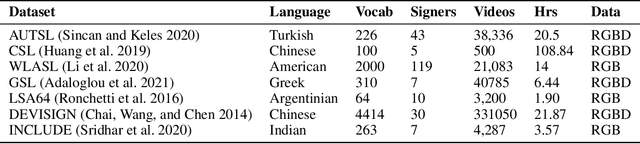
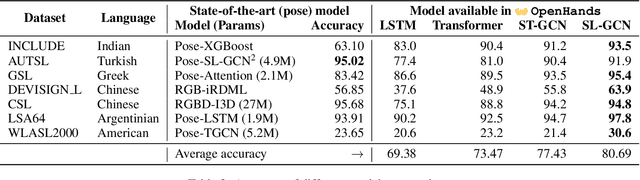
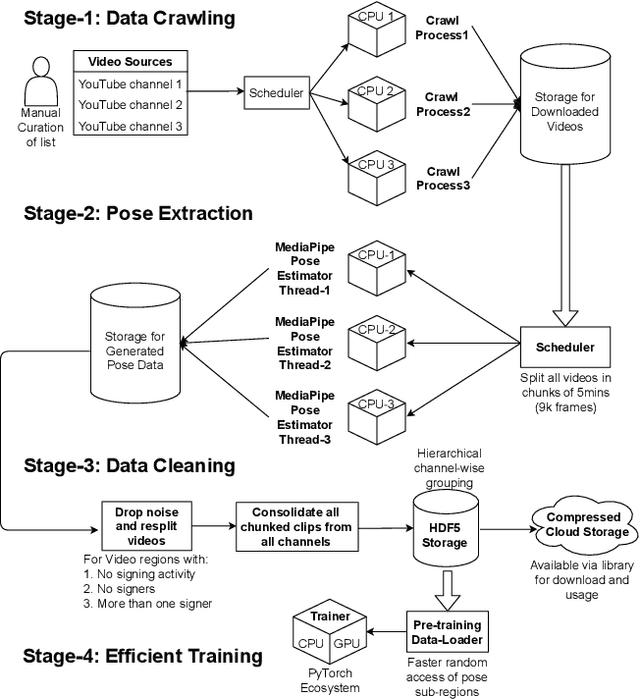
AI technologies for Natural Languages have made tremendous progress recently. However, commensurate progress has not been made on Sign Languages, in particular, in recognizing signs as individual words or as complete sentences. We introduce OpenHands, a library where we take four key ideas from the NLP community for low-resource languages and apply them to sign languages for word-level recognition. First, we propose using pose extracted through pretrained models as the standard modality of data to reduce training time and enable efficient inference, and we release standardized pose datasets for 6 different sign languages - American, Argentinian, Chinese, Greek, Indian, and Turkish. Second, we train and release checkpoints of 4 pose-based isolated sign language recognition models across all 6 languages, providing baselines and ready checkpoints for deployment. Third, to address the lack of labelled data, we propose self-supervised pretraining on unlabelled data. We curate and release the largest pose-based pretraining dataset on Indian Sign Language (Indian-SL). Fourth, we compare different pretraining strategies and for the first time establish that pretraining is effective for sign language recognition by demonstrating (a) improved fine-tuning performance especially in low-resource settings, and (b) high crosslingual transfer from Indian-SL to few other sign languages. We open-source all models and datasets in OpenHands with a hope that it makes research in sign languages more accessible, available here at https://github.com/AI4Bharat/OpenHands .