 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Building Large Scale Multimodal Domain-Aware Conversation Systems
Paper and Code
Jan 31, 2018


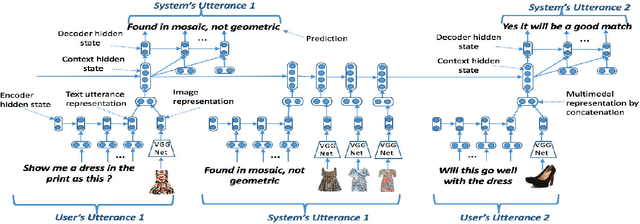
While multimodal conversation agents are gaining importance in several domains such as retail, travel etc., deep learning research in this area has been limited primarily due to the lack of availability of large-scale, open chatlogs. To overcome this bottleneck, in this paper we introduce the task of multimodal, domain-aware conversations, and propose the MMD benchmark dataset. This dataset was gathered by working in close coordination with large number of domain experts in the retail domain. These experts suggested various conversations flows and dialog states which are typically seen in multimodal conversations in the fashion domain. Keeping these flows and states in mind, we created a dataset consisting of over 150K conversation sessions between shoppers and sales agents, with the help of in-house annotators using a semi-automated manually intense iterative process. With this dataset, we propose 5 new sub-tasks for multimodal conversations along with their evaluation methodology. We also propose two multimodal neural models in the encode-attend-decode paradigm and demonstrate their performance on two of the sub-tasks, namely text response generation and best image response selection. These experiments serve to establish baseline performance and open new research directions for each of these sub-tasks. Further, for each of the sub-tasks, we present a `per-state evaluation' of 9 most significant dialog states, which would enable more focused research into understanding the challenges and complexities involved in each of these states.