 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising-based UNMT is more robust to word-order divergence than MASS-based UNMT
Mar 02, 2023



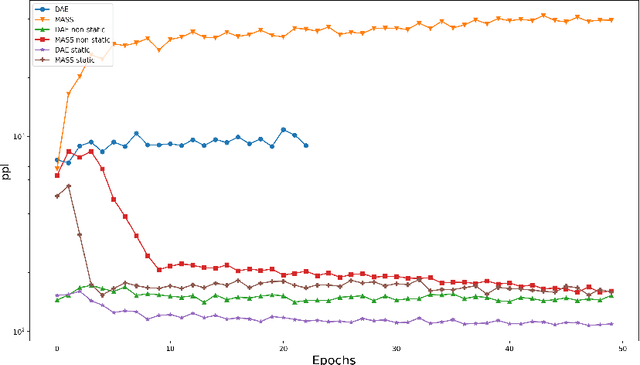
We aim to investigate whether UNMT approaches with self-supervised pre-training are robust to word-order divergence between language pairs. We achieve this by comparing two models pre-trained with the same self-supervised pre-training objective. The first model is trained on language pairs with different word-orders, and the second model is trained on the same language pairs with source language re-ordered to match the word-order of the target language. Ideally, UNMT approaches which are robust to word-order divergence should exhibit no visible performance difference between the two configurations. In this paper, we investigate two such self-supervised pre-training based UNMT approaches, namely Masked Sequence-to-Sequence Pre-Training, (MASS) (which does not have shuffling noise) and Denoising AutoEncoder (DAE), (which has shuffling noise). We experiment with five English$\rightarrow$Indic language pairs, i.e., en-hi, en-bn, en-gu, en-kn, and en-ta) where word-order of the source language is SVO (Subject-Verb-Object), and the word-order of the target languages is SOV (Subject-Object-Verb). We observed that for these language pairs, DAE-based UNMT approach consistently outperforms MASS in terms of translation accuracies. Moreover, bridging the word-order gap using reordering improves the translation accuracy of MASS-based UNMT models, while it cannot improve the translation accuracy of DAE-based UNMT models. This observation indicates that DAE-based UNMT is more robust to word-order divergence than MASS-based UNMT. Word-shuffling noise in DAE approach could be the possible reason for the approach being robust to word-order divergence.
Crosslingual Embeddings are Essential in UNMT for Distant Languages: An English to IndoAryan Case Study
Jun 09, 2021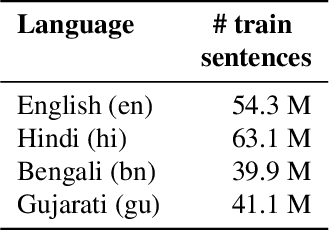
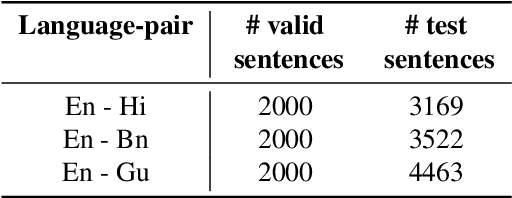
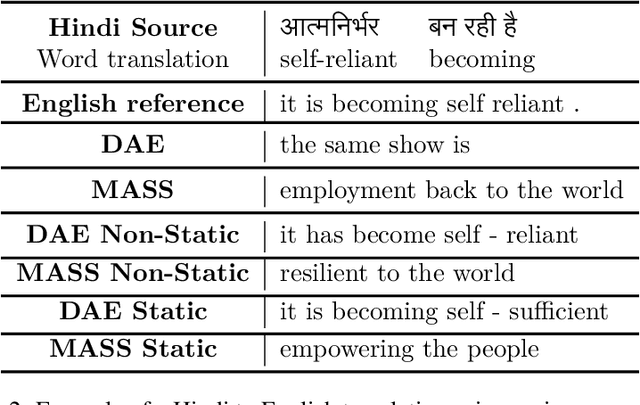
Recent advances in Unsupervised Neural Machine Translation (UNMT) have minimized the gap between supervised and unsupervised machine translation performance for closely related language pairs. However, the situation is very different for distant language pairs. Lack of lexical overlap and low syntactic similarities such as between English and Indo-Aryan languages leads to poor translation quality in existing UNMT systems. In this paper, we show that initializing the embedding layer of UNMT models with cross-lingual embeddings shows significant improvements in BLEU score over existing approaches with embeddings randomly initialized. Further, static embeddings (freezing the embedding layer weights) lead to better gains compared to updating the embedding layer weights during training (non-static). We experimented using Masked Sequence to Sequence (MASS) and Denoising Autoencoder (DAE) UNMT approaches for three distant language pairs. The proposed cross-lingual embedding initialization yields BLEU score improvement of as much as ten times over the baseline for English-Hindi, English-Bengali, and English-Gujarati. Our analysis shows the importance of cross-lingual embedding, comparisons between approaches, and the scope of improvements in these systems.
Ordering Matters: Word Ordering Aware Unsupervised NMT
Oct 30, 2019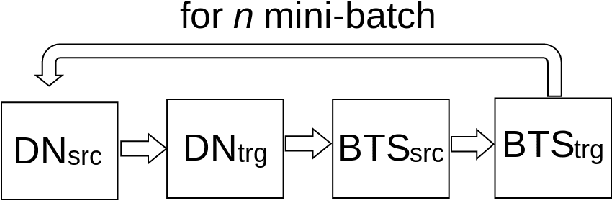
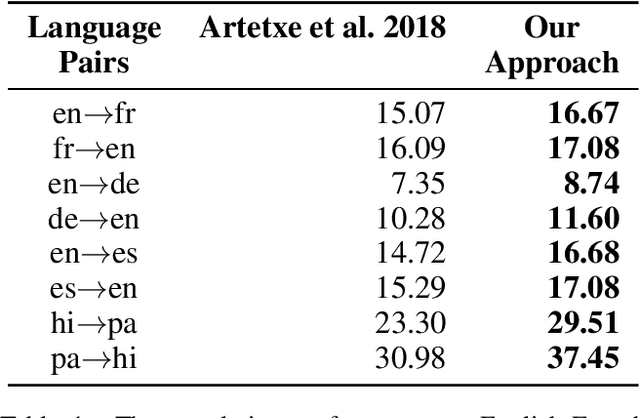
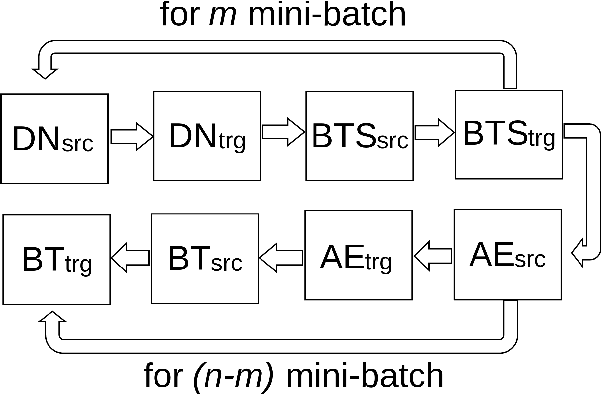
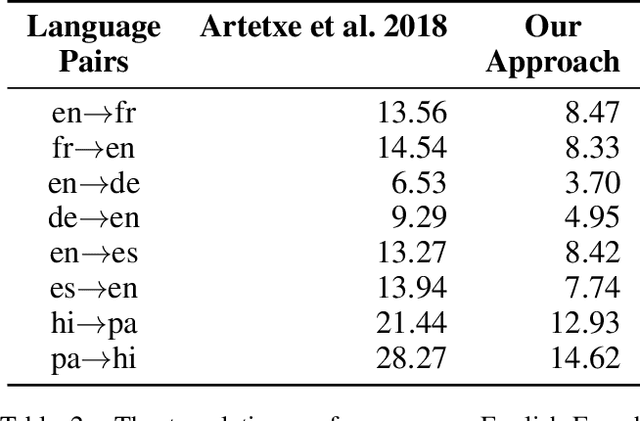
Denoising-based Unsupervised Neural Machine Translation (U-NMT) models typically employ denoising strategy at the encoder module to prevent the model from memorizing the input source sentence. Specifically, given an input sentence of length n, the model applies n/2 random swaps between consecutive words and trains the denoising-based U-NMT model. Though effective, applying denoising strategy on every sentence in the training data leads to uncertainty in the model thereby, limiting the benefits from the denoising-based U-NMT model. In this paper, we propose a simple fine-tuning strategy where we fine-tune the trained denoising-based U-NMT system without the denoising strategy. The input sentences are presented as is i.e., without any shuffling noise added. We observe significant improvements in translation performance on many language pairs from our fine-tuning strategy. Our analysis reveals that our proposed models lead to increase in higher n-gram BLEU score compared to the denoising U-NMT models.