 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrdering Matters: Word Ordering Aware Unsupervised NMT
Paper and Code
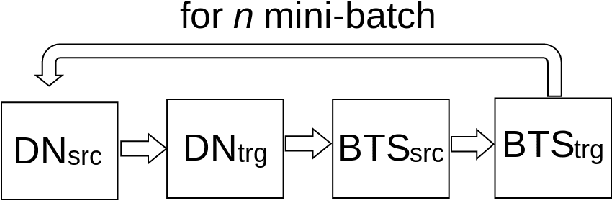
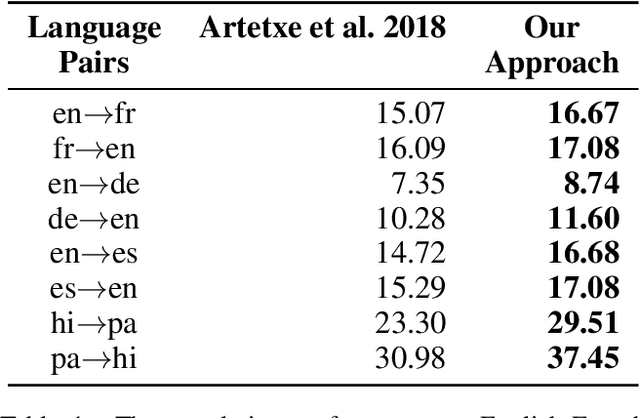
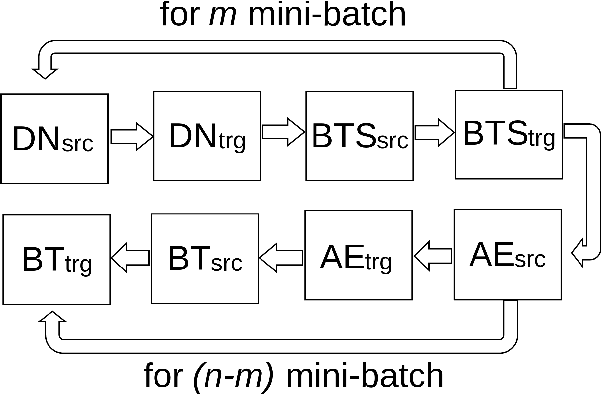
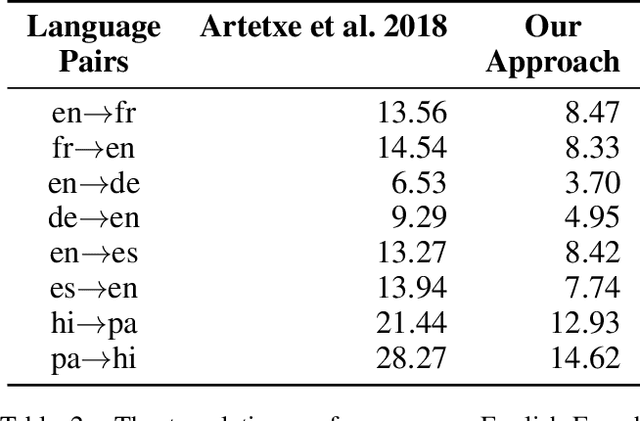
Denoising-based Unsupervised Neural Machine Translation (U-NMT) models typically employ denoising strategy at the encoder module to prevent the model from memorizing the input source sentence. Specifically, given an input sentence of length n, the model applies n/2 random swaps between consecutive words and trains the denoising-based U-NMT model. Though effective, applying denoising strategy on every sentence in the training data leads to uncertainty in the model thereby, limiting the benefits from the denoising-based U-NMT model. In this paper, we propose a simple fine-tuning strategy where we fine-tune the trained denoising-based U-NMT system without the denoising strategy. The input sentences are presented as is i.e., without any shuffling noise added. We observe significant improvements in translation performance on many language pairs from our fine-tuning strategy. Our analysis reveals that our proposed models lead to increase in higher n-gram BLEU score compared to the denoising U-NMT models.