 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Light-Weight Answer Text Retrieval in Dialogue Systems
May 31, 2022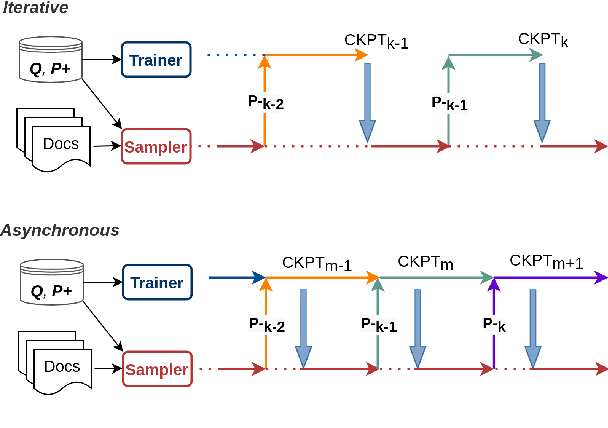
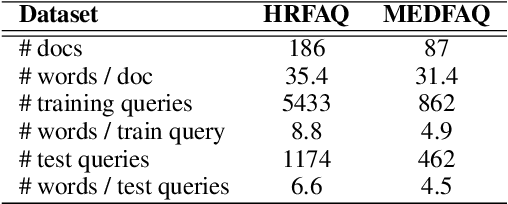
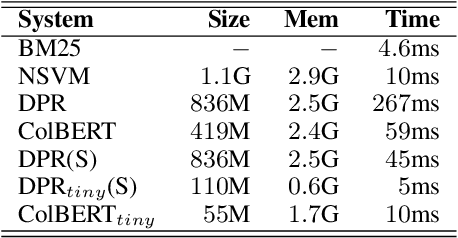
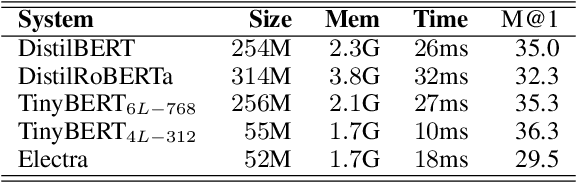
Dialogue systems can benefit from being able to search through a corpus of text to find information relevant to user requests, especially when encountering a request for which no manually curated response is available. The state-of-the-art technology for neural dense retrieval or re-ranking involves deep learning models with hundreds of millions of parameters. However, it is difficult and expensive to get such models to operate at an industrial scale, especially for cloud services that often need to support a big number of individually customized dialogue systems, each with its own text corpus. We report our work on enabling advanced neural dense retrieval systems to operate effectively at scale on relatively inexpensive hardware. We compare with leading alternative industrial solutions and show that we can provide a solution that is effective, fast, and cost-efficient.
Ensembling Strategies for Answering Natural Questions
Nov 06, 2019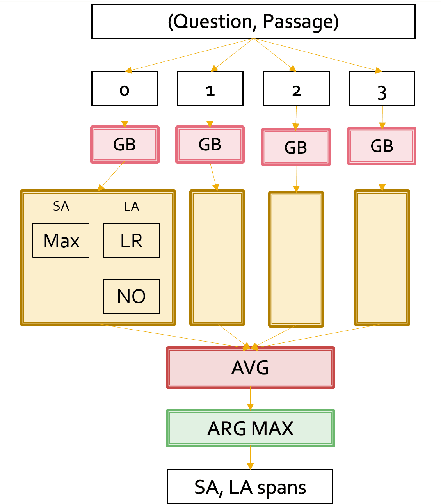

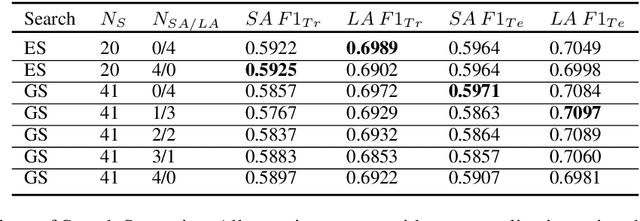
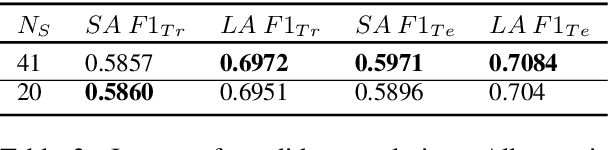
Many of the top question answering systems today utilize ensembling to improve their performance on tasks such as the Stanford Question Answering Dataset (SQuAD) and Natural Questions (NQ) challenges. Unfortunately most of these systems do not publish their ensembling strategies used in their leaderboard submissions. In this work, we investigate a number of ensembling techniques and demonstrate a strategy which improves our F1 score for short answers on the dev set for NQ by 2.3 F1 points over our single model (which outperforms the previous SOTA by 1.9 F1 points).
CFO: A Framework for Building Production NLP Systems
Aug 30, 2019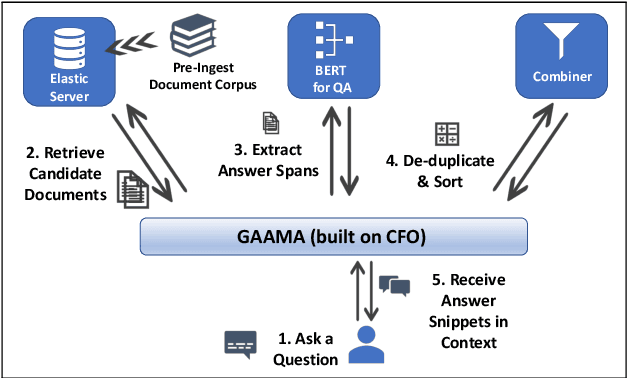
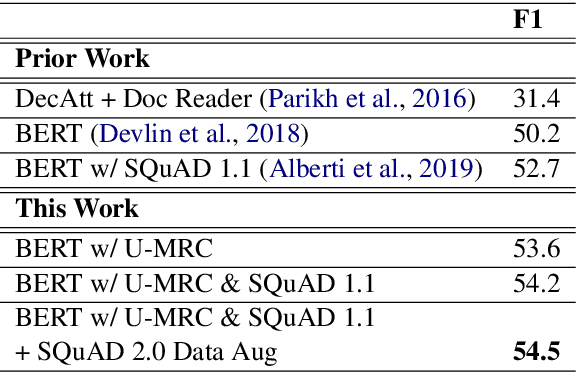
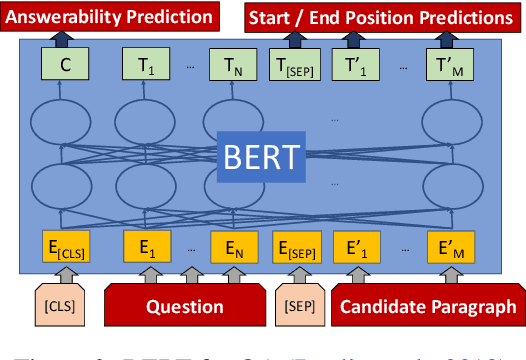

This paper introduces a novel orchestration framework, called CFO (COMPUTATION FLOW ORCHESTRATOR), for building, experimenting with, and deploying interactive NLP (Natural Language Processing) and IR (Information Retrieval) systems to production environments. We then demonstrate a question answering system built using this framework which incorporates state-of-the-art BERT based MRC (Machine Reading Comprehension) with IR components to enable end-to-end answer retrieval. Results from the demo system are shown to be high quality in both academic and industry domain specific settings. Finally, we discuss best practices when (pre-)training BERT based MRC models for production systems.