Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsembling Strategies for Answering Natural Questions
Paper and Code
Nov 06, 2019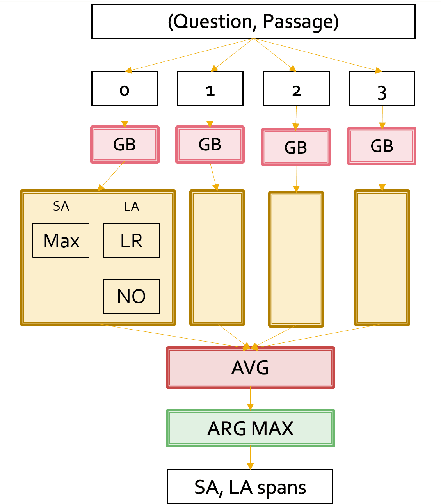

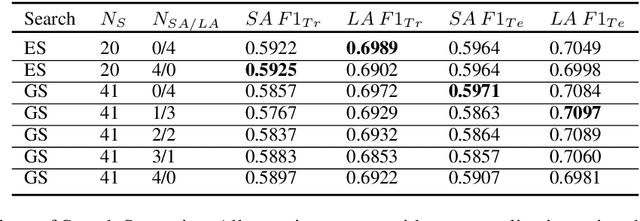
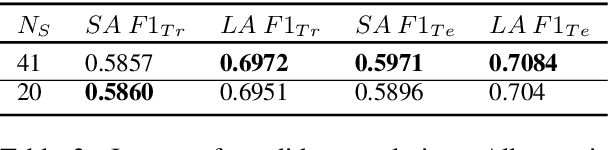
Many of the top question answering systems today utilize ensembling to improve their performance on tasks such as the Stanford Question Answering Dataset (SQuAD) and Natural Questions (NQ) challenges. Unfortunately most of these systems do not publish their ensembling strategies used in their leaderboard submissions. In this work, we investigate a number of ensembling techniques and demonstrate a strategy which improves our F1 score for short answers on the dev set for NQ by 2.3 F1 points over our single model (which outperforms the previous SOTA by 1.9 F1 points).
* arXiv admin note: text overlap with arXiv:1909.05286
View paper on