 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDN-Based False Data Detection With Its Mitigation and Machine Learning Robustness for In-Vehicle Networks
Jun 06, 2025As the development of autonomous and connected vehicles advances, the complexity of modern vehicles increases, with numerous Electronic Control Units (ECUs) integrated into the system. In an in-vehicle network, these ECUs communicate with one another using an standard protocol called Controller Area Network (CAN). Securing communication among ECUs plays a vital role in maintaining the safety and security of the vehicle. This paper proposes a robust SDN-based False Data Detection and Mitigation System (FDDMS) for in-vehicle networks. Leveraging the unique capabilities of Software-Defined Networking (SDN), FDDMS is designed to monitor and detect false data injection attacks in real-time. Specifically, we focus on brake-related ECUs within an SDN-enabled in-vehicle network. First, we decode raw CAN data to create an attack model that illustrates how false data can be injected into the system. Then, FDDMS, incorporating a Long Short Term Memory (LSTM)-based detection model, is used to identify false data injection attacks. We further propose an effective variant of DeepFool attack to evaluate the model's robustness. To countermeasure the impacts of four adversarial attacks including Fast gradient descent method, Basic iterative method, DeepFool, and the DeepFool variant, we further enhance a re-training technique method with a threshold based selection strategy. Finally, a mitigation scheme is implemented to redirect attack traffic by dynamically updating flow rules through SDN. Our experimental results show that the proposed FDDMS is robust against adversarial attacks and effectively detects and mitigates false data injection attacks in real-time.
Securing Traffic Sign Recognition Systems in Autonomous Vehicles
Jun 06, 2025Deep Neural Networks (DNNs) are widely used for traffic sign recognition because they can automatically extract high-level features from images. These DNNs are trained on large-scale datasets obtained from unknown sources. Therefore, it is important to ensure that the models remain secure and are not compromised or poisoned during training. In this paper, we investigate the robustness of DNNs trained for traffic sign recognition. First, we perform the error-minimizing attacks on DNNs used for traffic sign recognition by adding imperceptible perturbations on training data. Then, we propose a data augmentation-based training method to mitigate the error-minimizing attacks. The proposed training method utilizes nonlinear transformations to disrupt the perturbations and improve the model robustness. We experiment with two well-known traffic sign datasets to demonstrate the severity of the attack and the effectiveness of our mitigation scheme. The error-minimizing attacks reduce the prediction accuracy of the DNNs from 99.90% to 10.6%. However, our mitigation scheme successfully restores the prediction accuracy to 96.05%. Moreover, our approach outperforms adversarial training in mitigating the error-minimizing attacks. Furthermore, we propose a detection model capable of identifying poisoned data even when the perturbations are imperceptible to human inspection. Our detection model achieves a success rate of over 99% in identifying the attack. This research highlights the need to employ advanced training methods for DNNs in traffic sign recognition systems to mitigate the effects of data poisoning attacks.
Exploring Feature Importance and Explainability Towards Enhanced ML-Based DoS Detection in AI Systems
Nov 04, 2024Denial of Service (DoS) attacks pose a significant threat in the realm of AI systems security, causing substantial financial losses and downtime. However, AI systems' high computational demands, dynamic behavior, and data variability make monitoring and detecting DoS attacks challenging. Nowadays, statistical and machine learning (ML)-based DoS classification and detection approaches utilize a broad range of feature selection mechanisms to select a feature subset from networking traffic datasets. Feature selection is critical in enhancing the overall model performance and attack detection accuracy while reducing the training time. In this paper, we investigate the importance of feature selection in improving ML-based detection of DoS attacks. Specifically, we explore feature contribution to the overall components in DoS traffic datasets by utilizing statistical analysis and feature engineering approaches. Our experimental findings demonstrate the usefulness of the thorough statistical analysis of DoS traffic and feature engineering in understanding the behavior of the attack and identifying the best feature selection for ML-based DoS classification and detection.
Nonlinear Transformations Against Unlearnable Datasets
Jun 05, 2024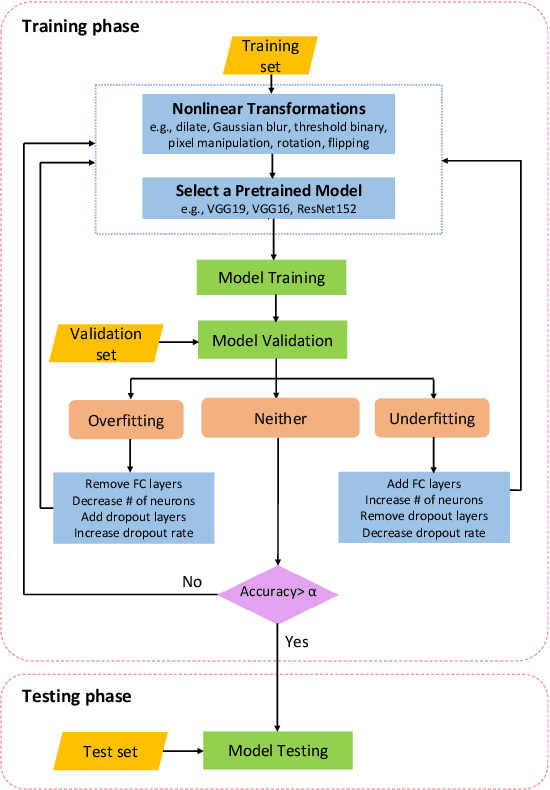

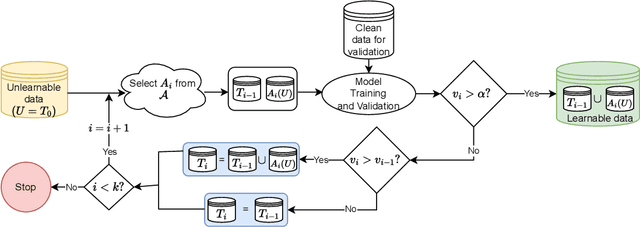

Automated scraping stands out as a common method for collecting data in deep learning models without the authorization of data owners. Recent studies have begun to tackle the privacy concerns associated with this data collection method. Notable approaches include Deepconfuse, error-minimizing, error-maximizing (also known as adversarial poisoning), Neural Tangent Generalization Attack, synthetic, autoregressive, One-Pixel Shortcut, Self-Ensemble Protection, Entangled Features, Robust Error-Minimizing, Hypocritical, and TensorClog. The data generated by those approaches, called "unlearnable" examples, are prevented "learning" by deep learning models. In this research, we investigate and devise an effective nonlinear transformation framework and conduct extensive experiments to demonstrate that a deep neural network can effectively learn from the data/examples traditionally considered unlearnable produced by the above twelve approaches. The resulting approach improves the ability to break unlearnable data compared to the linear separable technique recently proposed by researchers. Specifically, our extensive experiments show that the improvement ranges from 0.34% to 249.59% for the unlearnable CIFAR10 datasets generated by those twelve data protection approaches, except for One-Pixel Shortcut. Moreover, the proposed framework achieves over 100% improvement of test accuracy for Autoregressive and REM approaches compared to the linear separable technique. Our findings suggest that these approaches are inadequate in preventing unauthorized uses of data in machine learning models. There is an urgent need to develop more robust protection mechanisms that effectively thwart an attacker from accessing data without proper authorization from the owners.
Redefining DDoS Attack Detection Using A Dual-Space Prototypical Network-Based Approach
Jun 04, 2024Distributed Denial of Service (DDoS) attacks pose an increasingly substantial cybersecurity threat to organizations across the globe. In this paper, we introduce a new deep learning-based technique for detecting DDoS attacks, a paramount cybersecurity challenge with evolving complexity and scale. Specifically, we propose a new dual-space prototypical network that leverages a unique dual-space loss function to enhance detection accuracy for various attack patterns through geometric and angular similarity measures. This approach capitalizes on the strengths of representation learning within the latent space (a lower-dimensional representation of data that captures complex patterns for machine learning analysis), improving the model's adaptability and sensitivity towards varying DDoS attack vectors. Our comprehensive evaluation spans multiple training environments, including offline training, simulated online training, and prototypical network scenarios, to validate the model's robustness under diverse data abundance and scarcity conditions. The Multilayer Perceptron (MLP) with Attention, trained with our dual-space prototypical design over a reduced training set, achieves an average accuracy of 94.85% and an F1-Score of 94.71% across our tests, showcasing its effectiveness in dynamic and constrained real-world scenarios.
Advancing DDoS Attack Detection: A Synergistic Approach Using Deep Residual Neural Networks and Synthetic Oversampling
Jan 06, 2024Distributed Denial of Service (DDoS) attacks pose a significant threat to the stability and reliability of online systems. Effective and early detection of such attacks is pivotal for safeguarding the integrity of networks. In this work, we introduce an enhanced approach for DDoS attack detection by leveraging the capabilities of Deep Residual Neural Networks (ResNets) coupled with synthetic oversampling techniques. Because of the inherent class imbalance in many cyber-security datasets, conventional methods often struggle with false negatives, misclassifying subtle DDoS patterns as benign. By applying the Synthetic Minority Over-sampling Technique (SMOTE) to the CICIDS dataset, we balance the representation of benign and malicious data points, enabling the model to better discern intricate patterns indicative of an attack. Our deep residual network, tailored for this specific task, further refines the detection process. Experimental results on a real-world dataset demonstrate that our approach achieves an accuracy of 99.98%, significantly outperforming traditional methods. This work underscores the potential of combining advanced data augmentation techniques with deep learning models to bolster cyber-security defenses.
Blockchain-Based Security Architecture for Unmanned Aerial Vehicles in B5G/6G Services and Beyond: A Comprehensive Approach
Dec 12, 2023



Unmanned Aerial Vehicles (UAVs), previously favored by enthusiasts, have evolved into indispensable tools for effectively managing disasters and responding to emergencies. For example, one of their most critical applications is to provide seamless wireless communication services in remote rural areas. Thus, it is substantial to identify and consider the different security challenges in the research and development associated with advanced UAV-based B5G/6G architectures. Following this requirement, the present study thoroughly examines the security considerations about UAVs in relation to the architectural framework of the 5G/6G system, the technologies that facilitate its operation, and the concerns surrounding privacy. It exhibits security integration at all the protocol stack layers and analyzes the existing mechanisms to secure UAV-based B5G/6G communications and its energy and power optimization factors. Last, this article also summarizes modern technological trends for establishing security and protecting UAV-based systems, along with the open challenges and strategies for future research work.
A Decentralized Cooperative Navigation Approach for Visual Homing Networks
Oct 02, 2023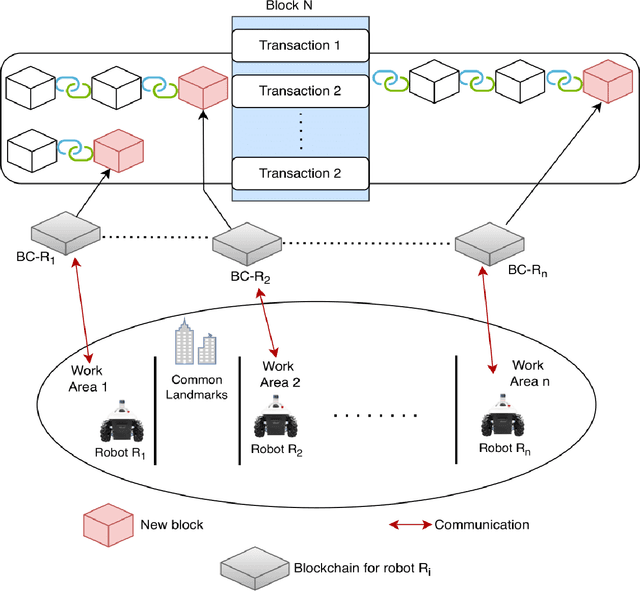

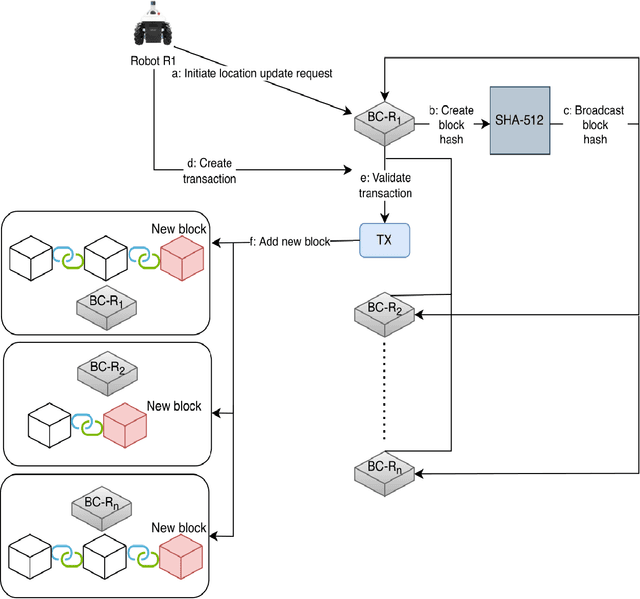
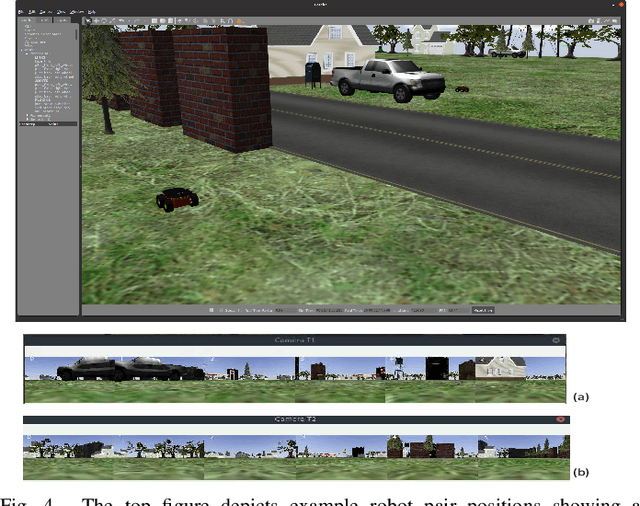
Visual homing is a lightweight approach to visual navigation. Given the stored information of an initial 'home' location, the navigation task back to this location is achieved from any other location by comparing the stored home information to the current image and extracting a motion vector. A challenge that constrains the applicability of visual homing is that the home location must be within the robot's field of view to initiate the homing process. Thus, we propose a blockchain approach to visual navigation for a heterogeneous robot team over a wide area of visual navigation. Because it does not require map data structures, the approach is useful for robot platforms with a small computational footprint, and because it leverages current visual information, it supports a resilient and adaptive path selection. Further, we present a lightweight Proof-of-Work (PoW) mechanism for reaching consensus in the untrustworthy visual homing network.
Improving Machine Learning Robustness via Adversarial Training
Sep 22, 2023As Machine Learning (ML) is increasingly used in solving various tasks in real-world applications, it is crucial to ensure that ML algorithms are robust to any potential worst-case noises, adversarial attacks, and highly unusual situations when they are designed. Studying ML robustness will significantly help in the design of ML algorithms. In this paper, we investigate ML robustness using adversarial training in centralized and decentralized environments, where ML training and testing are conducted in one or multiple computers. In the centralized environment, we achieve a test accuracy of 65.41% and 83.0% when classifying adversarial examples generated by Fast Gradient Sign Method and DeepFool, respectively. Comparing to existing studies, these results demonstrate an improvement of 18.41% for FGSM and 47% for DeepFool. In the decentralized environment, we study Federated learning (FL) robustness by using adversarial training with independent and identically distributed (IID) and non-IID data, respectively, where CIFAR-10 is used in this research. In the IID data case, our experimental results demonstrate that we can achieve such a robust accuracy that it is comparable to the one obtained in the centralized environment. Moreover, in the non-IID data case, the natural accuracy drops from 66.23% to 57.82%, and the robust accuracy decreases by 25% and 23.4% in C&W and Projected Gradient Descent (PGD) attacks, compared to the IID data case, respectively. We further propose an IID data-sharing approach, which allows for increasing the natural accuracy to 85.04% and the robust accuracy from 57% to 72% in C&W attacks and from 59% to 67% in PGD attacks.
ML Attack Models: Adversarial Attacks and Data Poisoning Attacks
Dec 06, 2021
Many state-of-the-art ML models have outperformed humans in various tasks such as image classification. With such outstanding performance, ML models are widely used today. However, the existence of adversarial attacks and data poisoning attacks really questions the robustness of ML models. For instance, Engstrom et al. demonstrated that state-of-the-art image classifiers could be easily fooled by a small rotation on an arbitrary image. As ML systems are being increasingly integrated into safety and security-sensitive applications, adversarial attacks and data poisoning attacks pose a considerable threat. This chapter focuses on the two broad and important areas of ML security: adversarial attacks and data poisoning attacks.