 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonlinear Transformations Against Unlearnable Datasets
Paper and Code
Jun 05, 2024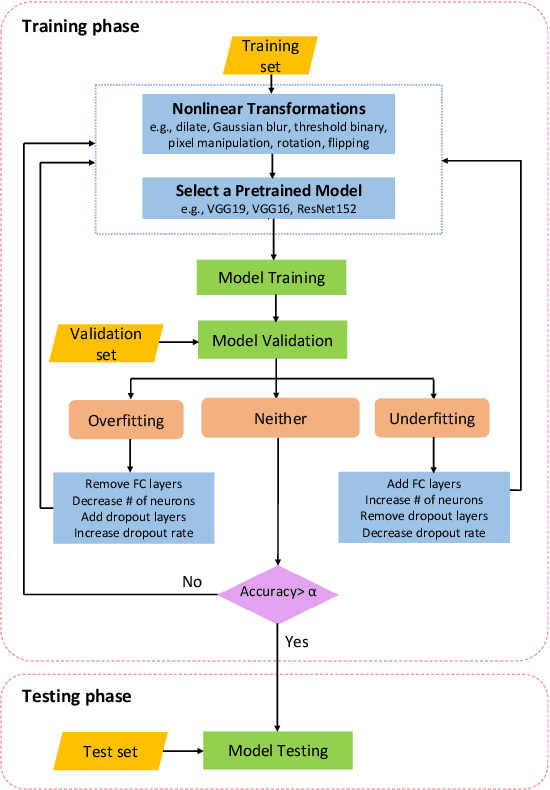

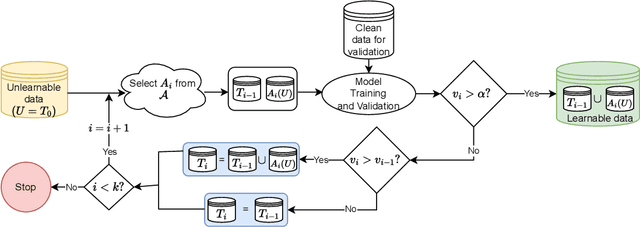

Automated scraping stands out as a common method for collecting data in deep learning models without the authorization of data owners. Recent studies have begun to tackle the privacy concerns associated with this data collection method. Notable approaches include Deepconfuse, error-minimizing, error-maximizing (also known as adversarial poisoning), Neural Tangent Generalization Attack, synthetic, autoregressive, One-Pixel Shortcut, Self-Ensemble Protection, Entangled Features, Robust Error-Minimizing, Hypocritical, and TensorClog. The data generated by those approaches, called "unlearnable" examples, are prevented "learning" by deep learning models. In this research, we investigate and devise an effective nonlinear transformation framework and conduct extensive experiments to demonstrate that a deep neural network can effectively learn from the data/examples traditionally considered unlearnable produced by the above twelve approaches. The resulting approach improves the ability to break unlearnable data compared to the linear separable technique recently proposed by researchers. Specifically, our extensive experiments show that the improvement ranges from 0.34% to 249.59% for the unlearnable CIFAR10 datasets generated by those twelve data protection approaches, except for One-Pixel Shortcut. Moreover, the proposed framework achieves over 100% improvement of test accuracy for Autoregressive and REM approaches compared to the linear separable technique. Our findings suggest that these approaches are inadequate in preventing unauthorized uses of data in machine learning models. There is an urgent need to develop more robust protection mechanisms that effectively thwart an attacker from accessing data without proper authorization from the owners.