 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuardEval: A Multi-Perspective Benchmark for Evaluating Safety, Fairness, and Robustness in LLM Moderators
Dec 22, 2025As large language models (LLMs) become deeply embedded in daily life, the urgent need for safer moderation systems, distinguishing between naive from harmful requests while upholding appropriate censorship boundaries, has never been greater. While existing LLMs can detect harmful or unsafe content, they often struggle with nuanced cases such as implicit offensiveness, subtle gender and racial biases, and jailbreak prompts, due to the subjective and context-dependent nature of these issues. Furthermore, their heavy reliance on training data can reinforce societal biases, resulting in inconsistent and ethically problematic outputs. To address these challenges, we introduce GuardEval, a unified multi-perspective benchmark dataset designed for both training and evaluation, containing 106 fine-grained categories spanning human emotions, offensive and hateful language, gender and racial bias, and broader safety concerns. We also present GemmaGuard (GGuard), a QLoRA fine-tuned version of Gemma3-12B trained on GuardEval, to assess content moderation with fine-grained labels. Our evaluation shows that GGuard achieves a macro F1 score of 0.832, substantially outperforming leading moderation models, including OpenAI Moderator (0.64) and Llama Guard (0.61). We show that multi-perspective, human-centered safety benchmarks are critical for reducing biased and inconsistent moderation decisions. GuardEval and GGuard together demonstrate that diverse, representative data materially improve safety, fairness, and robustness on complex, borderline cases.
Towards Safer AI Moderation: Evaluating LLM Moderators Through a Unified Benchmark Dataset and Advocating a Human-First Approach
Aug 09, 2025As AI systems become more integrated into daily life, the need for safer and more reliable moderation has never been greater. Large Language Models (LLMs) have demonstrated remarkable capabilities, surpassing earlier models in complexity and performance. Their evaluation across diverse tasks has consistently showcased their potential, enabling the development of adaptive and personalized agents. However, despite these advancements, LLMs remain prone to errors, particularly in areas requiring nuanced moral reasoning. They struggle with detecting implicit hate, offensive language, and gender biases due to the subjective and context-dependent nature of these issues. Moreover, their reliance on training data can inadvertently reinforce societal biases, leading to inconsistencies and ethical concerns in their outputs. To explore the limitations of LLMs in this role, we developed an experimental framework based on state-of-the-art (SOTA) models to assess human emotions and offensive behaviors. The framework introduces a unified benchmark dataset encompassing 49 distinct categories spanning the wide spectrum of human emotions, offensive and hateful text, and gender and racial biases. Furthermore, we introduced SafePhi, a QLoRA fine-tuned version of Phi-4, adapting diverse ethical contexts and outperforming benchmark moderators by achieving a Macro F1 score of 0.89, where OpenAI Moderator and Llama Guard score 0.77 and 0.74, respectively. This research also highlights the critical domains where LLM moderators consistently underperformed, pressing the need to incorporate more heterogeneous and representative data with human-in-the-loop, for better model robustness and explainability.
Advancing DDoS Attack Detection: A Synergistic Approach Using Deep Residual Neural Networks and Synthetic Oversampling
Jan 06, 2024Distributed Denial of Service (DDoS) attacks pose a significant threat to the stability and reliability of online systems. Effective and early detection of such attacks is pivotal for safeguarding the integrity of networks. In this work, we introduce an enhanced approach for DDoS attack detection by leveraging the capabilities of Deep Residual Neural Networks (ResNets) coupled with synthetic oversampling techniques. Because of the inherent class imbalance in many cyber-security datasets, conventional methods often struggle with false negatives, misclassifying subtle DDoS patterns as benign. By applying the Synthetic Minority Over-sampling Technique (SMOTE) to the CICIDS dataset, we balance the representation of benign and malicious data points, enabling the model to better discern intricate patterns indicative of an attack. Our deep residual network, tailored for this specific task, further refines the detection process. Experimental results on a real-world dataset demonstrate that our approach achieves an accuracy of 99.98%, significantly outperforming traditional methods. This work underscores the potential of combining advanced data augmentation techniques with deep learning models to bolster cyber-security defenses.
i6mA-CNN: a convolution based computational approach towards identification of DNA N6-methyladenine sites in rice genome
Aug 11, 2020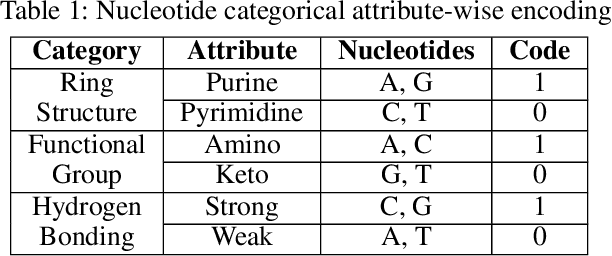
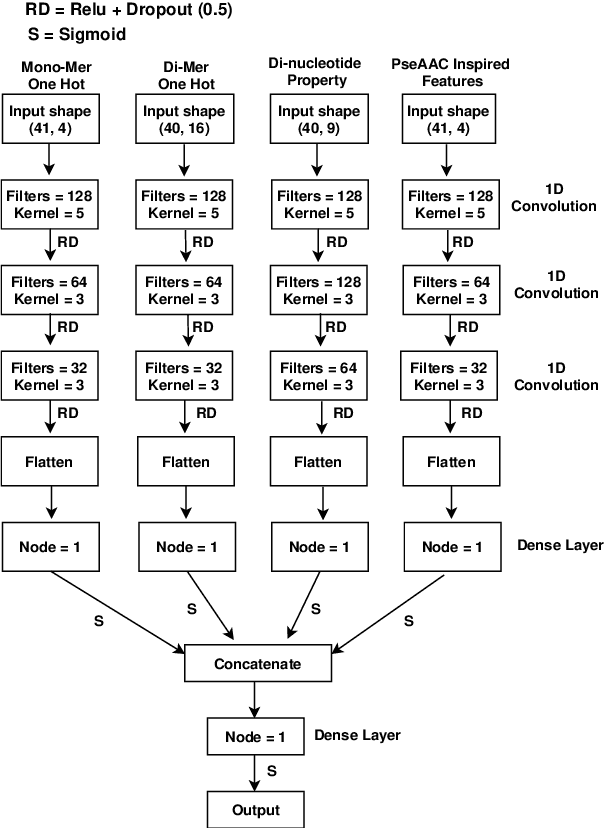
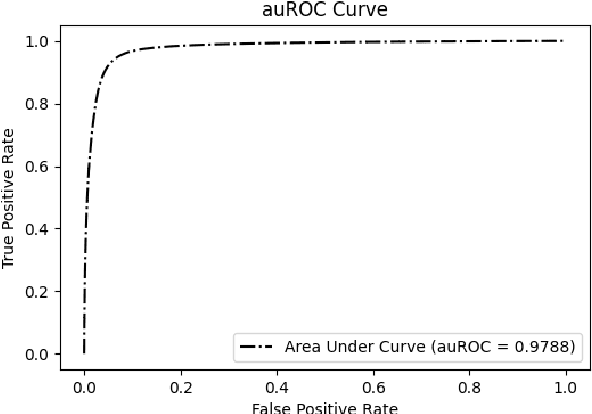
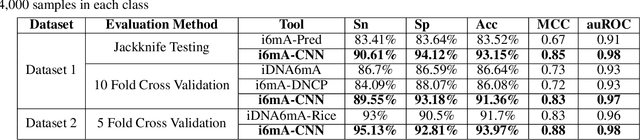
DNA N6-methylation (6mA) in Adenine nucleotide is a post replication modification and is responsible for many biological functions. Experimental methods for genome wide 6mA site detection is an expensive and manual labour intensive process. Automated and accurate computational methods can help to identify 6mA sites in long genomes saving significant time and money. Our study develops a convolutional neural network based tool i6mA-CNN capable of identifying 6mA sites in the rice genome. Our model coordinates among multiple types of features such as PseAAC inspired customized feature vector, multiple one hot representations and dinucleotide physicochemical properties. It achieves area under the receiver operating characteristic curve of 0.98 with an overall accuracy of 0.94 using 5 fold cross validation on benchmark dataset. Finally, we evaluate our model on two other plant genome 6mA site identification datasets besides rice. Results suggest that our proposed tool is able to generalize its ability of 6mA site identification on plant genomes irrespective of plant species. Web tool for this research can be found at: https://cutt.ly/Co6KuWG. Supplementary data (benchmark dataset, independent test dataset, comparison purpose dataset, trained model, physicochemical property values, attention mechanism details for motif finding) are available at https://cutt.ly/PpDdeDH.
iPromoter-BnCNN: a Novel Branched CNN Based Predictor for Identifying and Classifying Sigma Promoters
Jan 10, 2020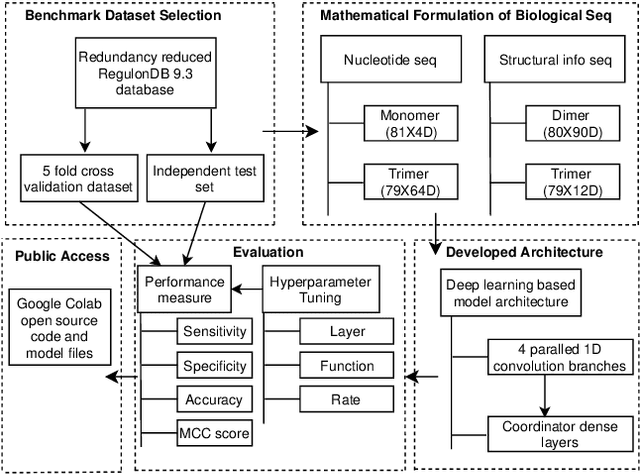
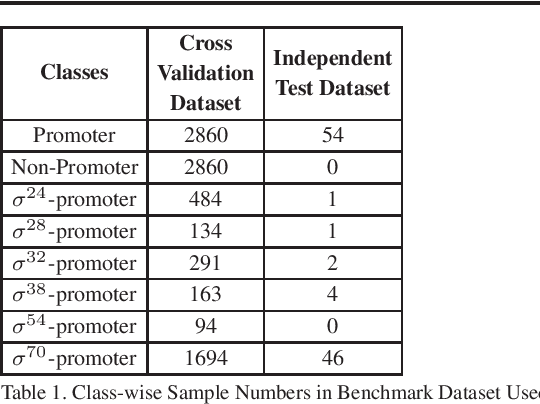
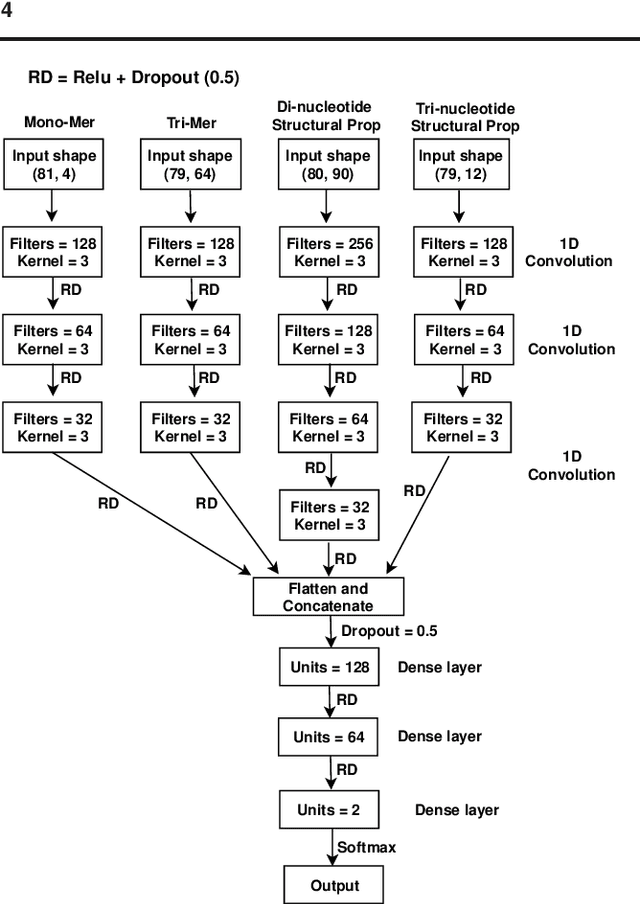
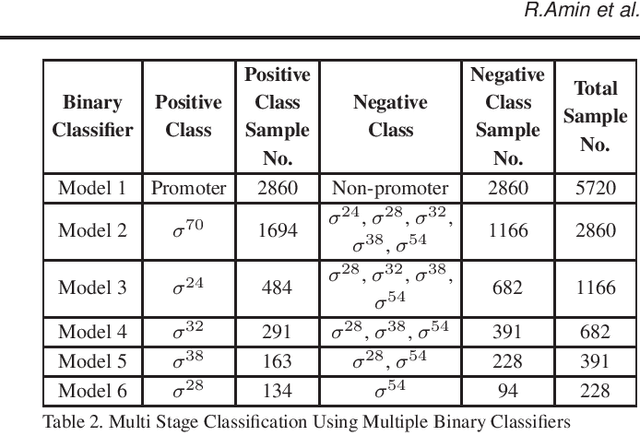
Promoter is a short region of DNA which is responsible for initiating transcription of specific genes. Development of computational tools for automatic identification of promoters is in high demand. According to the difference of functions, promoters can be of different types. Promoters may have both intra and inter class variation and similarity in terms of consensus sequences. Accurate classification of various types of sigma promoters still remains a challenge. We present iPromoter-BnCNN for identification and accurate classification of six types of promoters - sigma24, sigma28, sigma32, sigma38, sigma54, sigma70. It is a Convolutional Neural Network (CNN) based classifier which combines local features related to monomer nucleotide sequence, trimer nucleotide sequence, dimer structural properties and trimer structural properties through the use of parallel branching. We conducted experiments on a benchmark dataset and compared with two state-of-the-art tools to show our supremacy on 5-fold cross-validation. Moreover, we tested our classifier on an independent test dataset. Our proposed tool iPromoter-BnCNN along with the source code is freely available at https://cutt.ly/te6XISV.
A Hybrid Approach Towards Two Stage Bengali Question Classification Utilizing Smart Data Balancing Technique
Dec 08, 2019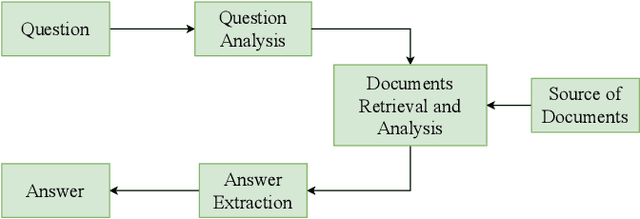
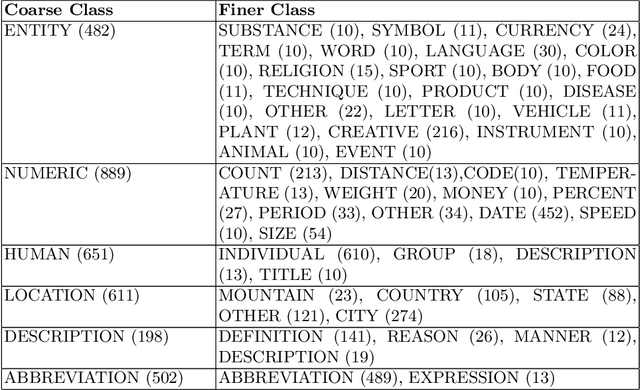
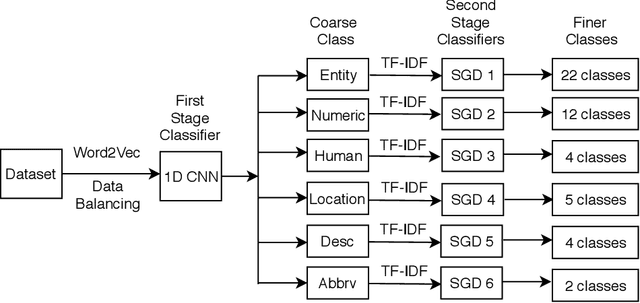

Question classification (QC) is the primary step of the Question Answering (QA) system. Question Classification (QC) system classifies the questions in particular classes so that Question Answering (QA) System can provide correct answers for the questions. Our system categorizes the factoid type questions asked in natural language after extracting features of the questions. We present a two stage QC system for Bengali. It utilizes one dimensional convolutional neural network for classifying questions into coarse classes in the first stage. Word2vec representation of existing words of the question corpus have been constructed and used for assisting 1D CNN. A smart data balancing technique has been employed for giving data hungry convolutional neural network the advantage of a greater number of effective samples to learn from. For each coarse class, a separate Stochastic Gradient Descent (SGD) based classifier has been used in order to differentiate among the finer classes within that coarse class. TF-IDF representation of each word has been used as feature for the SGD classifiers implemented as part of second stage classification. Experiments show the effectiveness of our proposed method for Bengali question classification.