 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Error Dataset Generation Mimicking Bengali Writing Pattern
Mar 07, 2020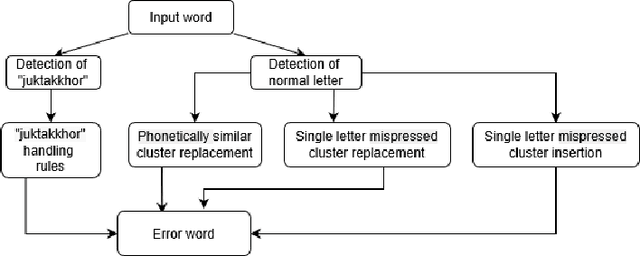

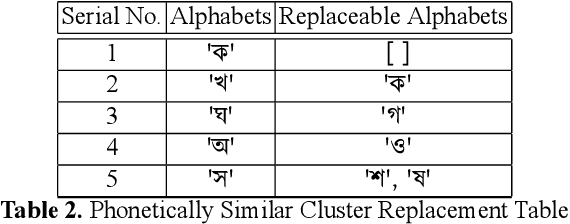
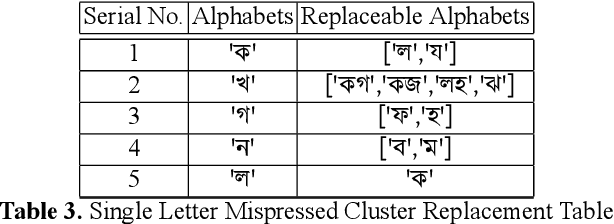
While writing Bengali using English keyboard, users often make spelling mistakes. The accuracy of any Bengali spell checker or paragraph correction module largely depends on the kind of error dataset it is based on. Manual generation of such error dataset is a cumbersome process. In this research, We present an algorithm for automatic misspelled Bengali word generation from correct word through analyzing Bengali writing pattern using QWERTY layout English keyboard. As part of our analysis, we have formed a list of most commonly used Bengali words, phonetically similar replaceable clusters, frequently mispressed replaceable clusters, frequently mispressed insertion prone clusters and some rules for Juktakkhar (constant letter clusters) handling while generating errors.
iPromoter-BnCNN: a Novel Branched CNN Based Predictor for Identifying and Classifying Sigma Promoters
Jan 10, 2020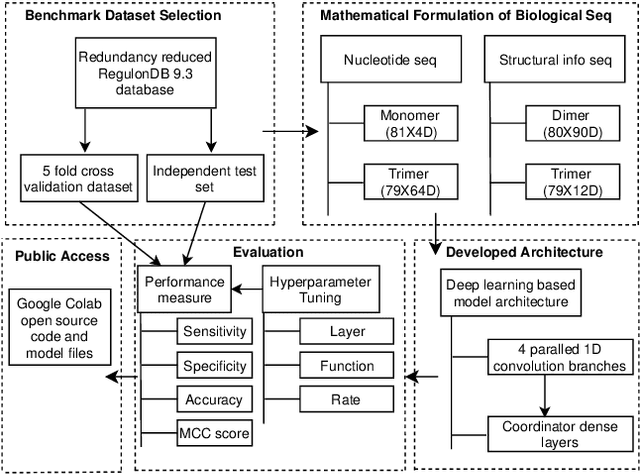
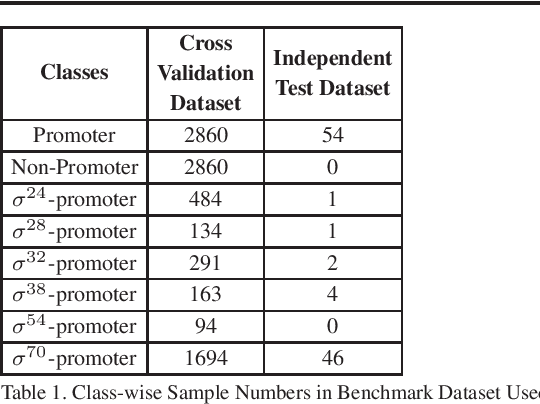
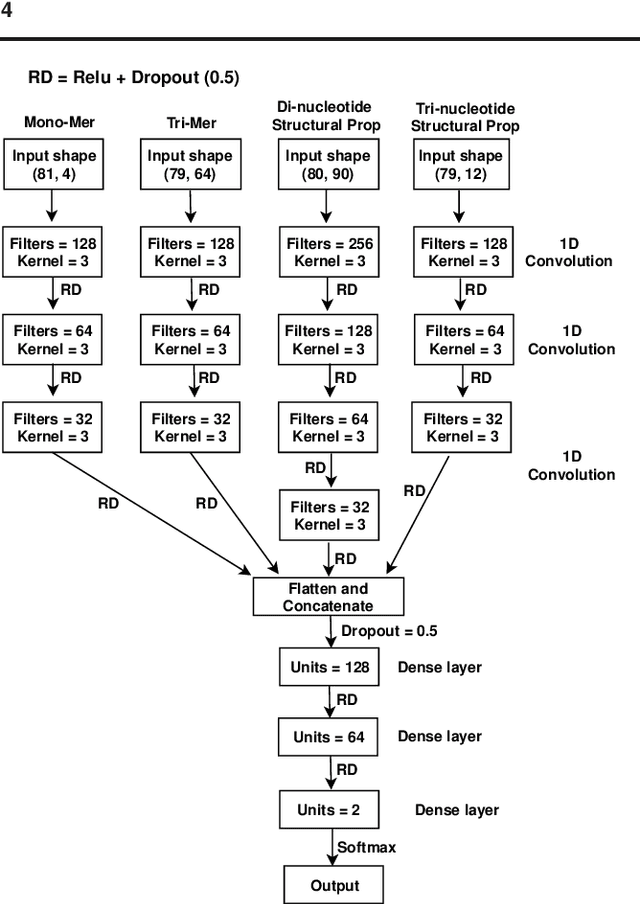
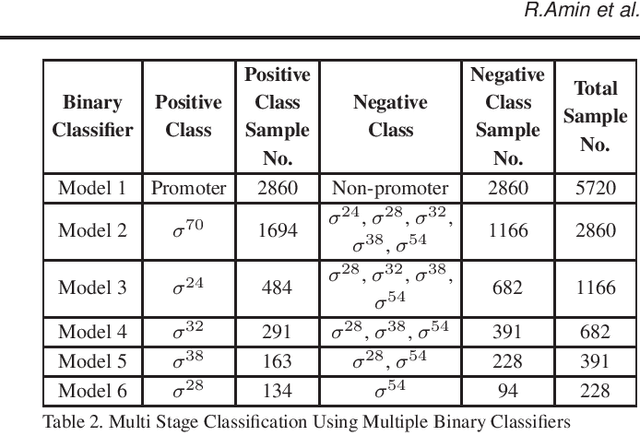
Promoter is a short region of DNA which is responsible for initiating transcription of specific genes. Development of computational tools for automatic identification of promoters is in high demand. According to the difference of functions, promoters can be of different types. Promoters may have both intra and inter class variation and similarity in terms of consensus sequences. Accurate classification of various types of sigma promoters still remains a challenge. We present iPromoter-BnCNN for identification and accurate classification of six types of promoters - sigma24, sigma28, sigma32, sigma38, sigma54, sigma70. It is a Convolutional Neural Network (CNN) based classifier which combines local features related to monomer nucleotide sequence, trimer nucleotide sequence, dimer structural properties and trimer structural properties through the use of parallel branching. We conducted experiments on a benchmark dataset and compared with two state-of-the-art tools to show our supremacy on 5-fold cross-validation. Moreover, we tested our classifier on an independent test dataset. Our proposed tool iPromoter-BnCNN along with the source code is freely available at https://cutt.ly/te6XISV.
A Hybrid Approach Towards Two Stage Bengali Question Classification Utilizing Smart Data Balancing Technique
Dec 08, 2019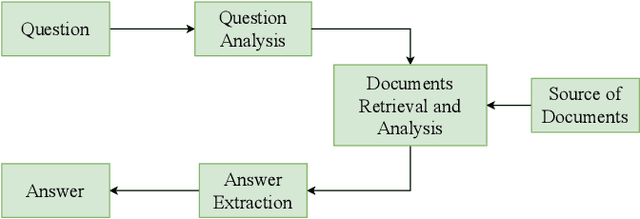
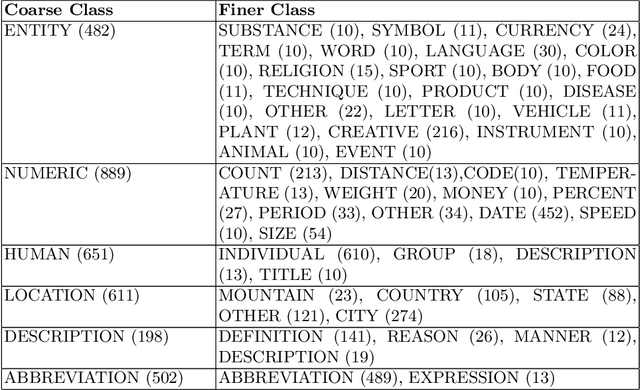
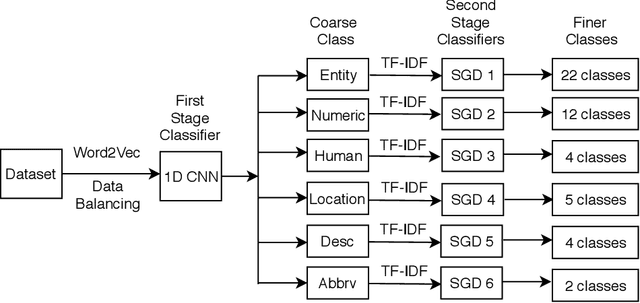

Question classification (QC) is the primary step of the Question Answering (QA) system. Question Classification (QC) system classifies the questions in particular classes so that Question Answering (QA) System can provide correct answers for the questions. Our system categorizes the factoid type questions asked in natural language after extracting features of the questions. We present a two stage QC system for Bengali. It utilizes one dimensional convolutional neural network for classifying questions into coarse classes in the first stage. Word2vec representation of existing words of the question corpus have been constructed and used for assisting 1D CNN. A smart data balancing technique has been employed for giving data hungry convolutional neural network the advantage of a greater number of effective samples to learn from. For each coarse class, a separate Stochastic Gradient Descent (SGD) based classifier has been used in order to differentiate among the finer classes within that coarse class. TF-IDF representation of each word has been used as feature for the SGD classifiers implemented as part of second stage classification. Experiments show the effectiveness of our proposed method for Bengali question classification.