 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Early Alzheimer Disease Detection with MRI Scans
Jan 17, 2025Alzheimer's Disease is a neurodegenerative condition characterized by dementia and impairment in neurological function. The study primarily focuses on the individuals above age 40, affecting their memory, behavior, and cognitive processes of the brain. Alzheimer's disease requires diagnosis by a detailed assessment of MRI scans and neuropsychological tests of the patients. This project compares existing deep learning models in the pursuit of enhancing the accuracy and efficiency of AD diagnosis, specifically focusing on the Convolutional Neural Network, Bayesian Convolutional Neural Network, and the U-net model with the Open Access Series of Imaging Studies brain MRI dataset. Besides, to ensure robustness and reliability in the model evaluations, we address the challenge of imbalance in data. We then perform rigorous evaluation to determine strengths and weaknesses for each model by considering sensitivity, specificity, and computational efficiency. This comparative analysis would shed light on the future role of AI in revolutionizing AD diagnostics but also paved ways for future innovation in medical imaging and the management of neurodegenerative diseases.
BSpell: A CNN-blended BERT Based Bengali Spell Checker
Aug 20, 2022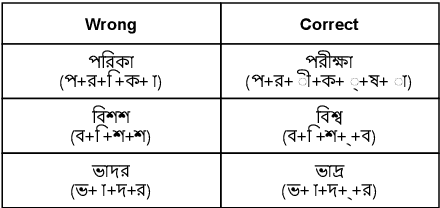
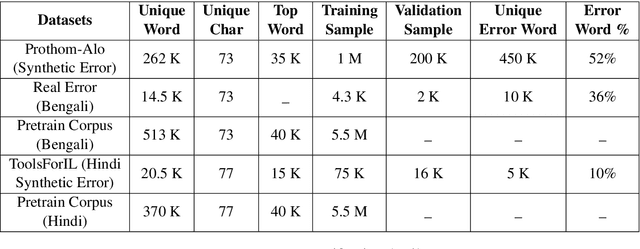

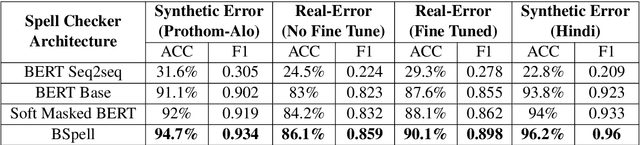
Bengali typing is mostly performed using English keyboard and can be highly erroneous due to the presence of compound and similarly pronounced letters. Spelling correction of a misspelled word requires understanding of word typing pattern as well as the context of the word usage. We propose a specialized BERT model, BSpell targeted towards word for word correction in sentence level. BSpell contains an end-to-end trainable CNN sub-model named SemanticNet along with specialized auxiliary loss. This allows BSpell to specialize in highly inflected Bengali vocabulary in the presence of spelling errors. We further propose hybrid pretraining scheme for BSpell combining word level and character level masking. Utilizing this pretraining scheme, BSpell achieves 91.5% accuracy on real life Bengali spelling correction validation set. Detailed comparison on two Bengali and one Hindi spelling correction dataset shows the superiority of proposed BSpell over existing spell checkers.
Paradigm Shift in Language Modeling: Revisiting CNN for Modeling Sanskrit Originated Bengali and Hindi Language
Nov 05, 2021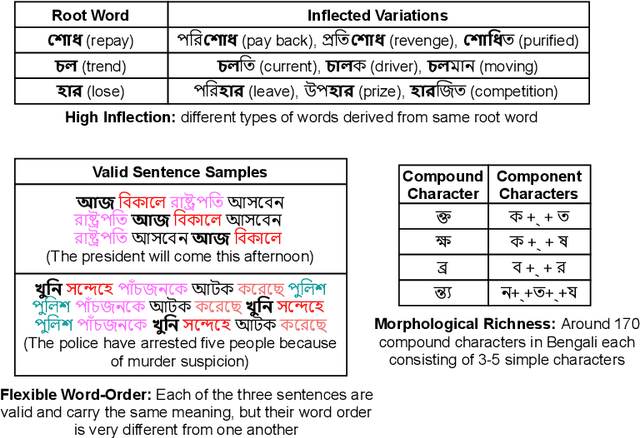
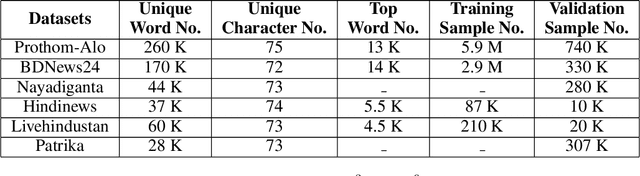
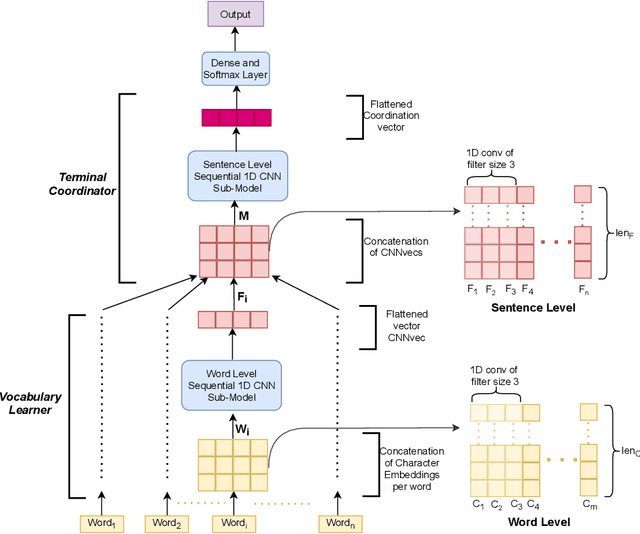
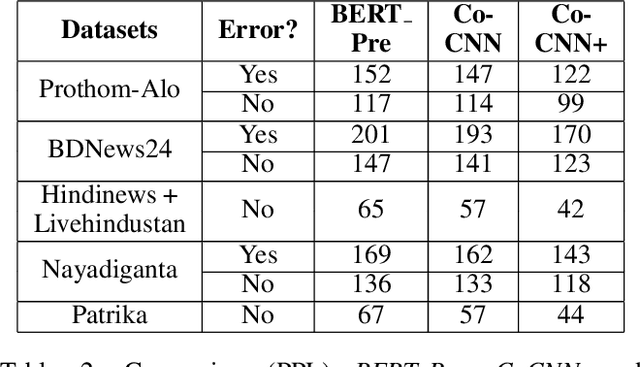
Though there has been a large body of recent works in language modeling (LM) for high resource languages such as English and Chinese, the area is still unexplored for low resource languages like Bengali and Hindi. We propose an end to end trainable memory efficient CNN architecture named CoCNN to handle specific characteristics such as high inflection, morphological richness, flexible word order and phonetical spelling errors of Bengali and Hindi. In particular, we introduce two learnable convolutional sub-models at word and at sentence level that are end to end trainable. We show that state-of-the-art (SOTA) Transformer models including pretrained BERT do not necessarily yield the best performance for Bengali and Hindi. CoCNN outperforms pretrained BERT with 16X less parameters, and it achieves much better performance than SOTA LSTM models on multiple real-world datasets. This is the first study on the effectiveness of different architectures drawn from three deep learning paradigms - Convolution, Recurrent, and Transformer neural nets for modeling two widely used languages, Bengali and Hindi.
Synthetic Error Dataset Generation Mimicking Bengali Writing Pattern
Mar 07, 2020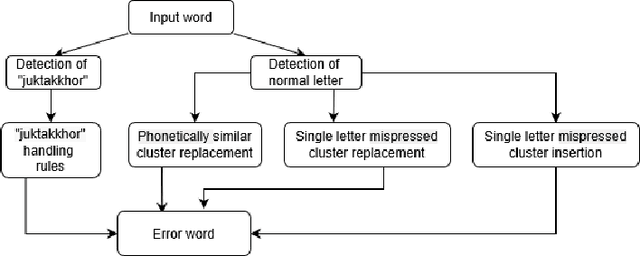

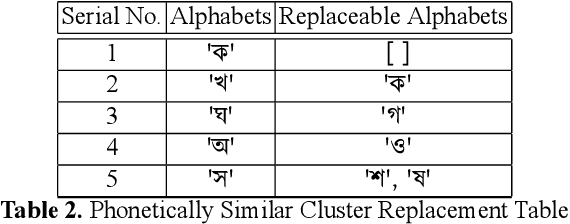
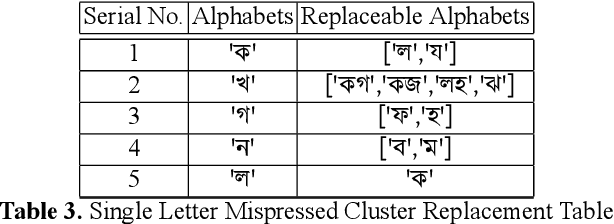
While writing Bengali using English keyboard, users often make spelling mistakes. The accuracy of any Bengali spell checker or paragraph correction module largely depends on the kind of error dataset it is based on. Manual generation of such error dataset is a cumbersome process. In this research, We present an algorithm for automatic misspelled Bengali word generation from correct word through analyzing Bengali writing pattern using QWERTY layout English keyboard. As part of our analysis, we have formed a list of most commonly used Bengali words, phonetically similar replaceable clusters, frequently mispressed replaceable clusters, frequently mispressed insertion prone clusters and some rules for Juktakkhar (constant letter clusters) handling while generating errors.