 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Code Representations Enable Data-Efficient Adaptation of Code Language Models
Paper and Code



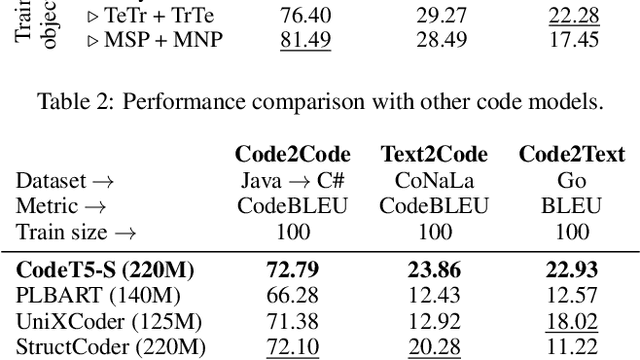
Current language models tailored for code tasks often adopt the pre-training-then-fine-tuning paradigm from natural language processing, modeling source code as plain text. This approach, however, overlooks the unambiguous structures inherent in programming languages. In this work, we explore data-efficient adaptation of pre-trained code models by further pre-training and fine-tuning them with program structures. Specifically, we represent programs as parse trees -- also known as concrete syntax trees (CSTs) -- and adapt pre-trained models on serialized CSTs. Although the models that we adapt have been pre-trained only on the surface form of programs, we find that a small amount of continual pre-training and fine-tuning on CSTs without changing the model architecture yields improvements over the baseline approach across various code tasks. The improvements are found to be particularly significant when there are limited training examples, demonstrating the effectiveness of integrating program structures with plain-text representation even when working with backbone models that have not been pre-trained with structures.