 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Application of Large Language Models to Coding Negotiation Transcripts
Jul 18, 2024
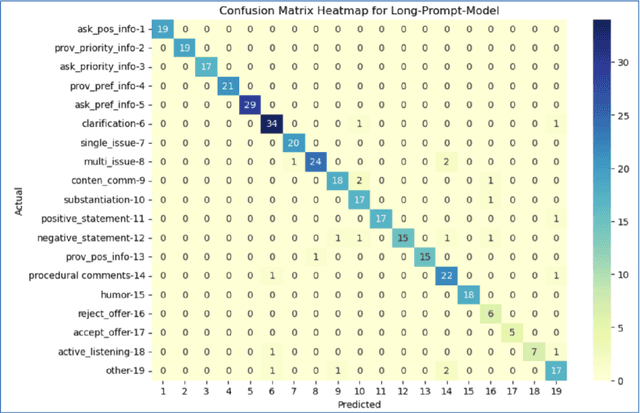
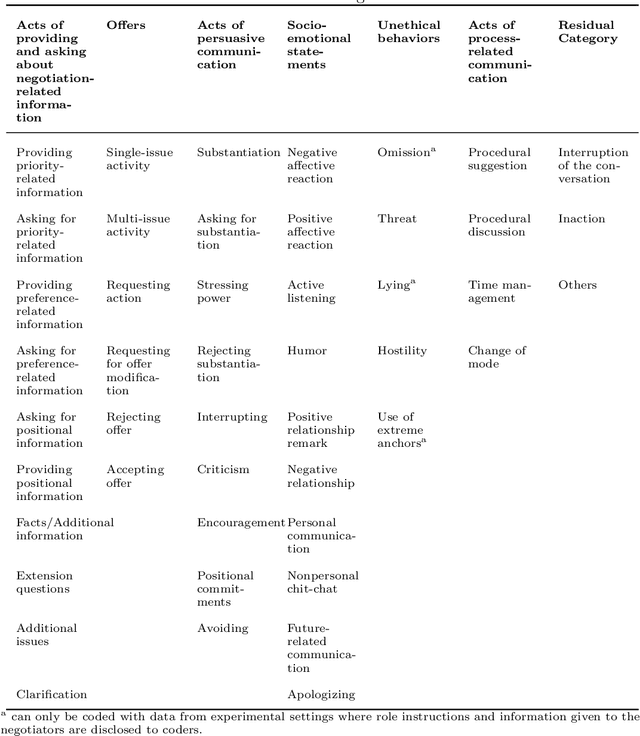
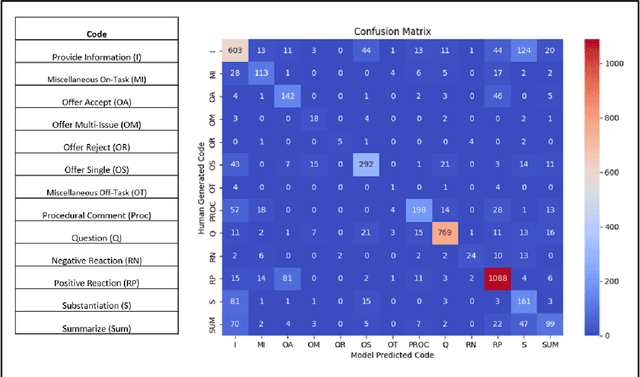
In recent years, Large Language Models (LLM) have demonstrated impressive capabilities in the field of natural language processing (NLP). This paper explores the application of LLMs in negotiation transcript analysis by the Vanderbilt AI Negotiation Lab. Starting in September 2022, we applied multiple strategies using LLMs from zero shot learning to fine tuning models to in-context learning). The final strategy we developed is explained, along with how to access and use the model. This study provides a sense of both the opportunities and roadblocks for the implementation of LLMs in real life applications and offers a model for how LLMs can be applied to coding in other fields.
Semantic Compression With Large Language Models
Apr 25, 2023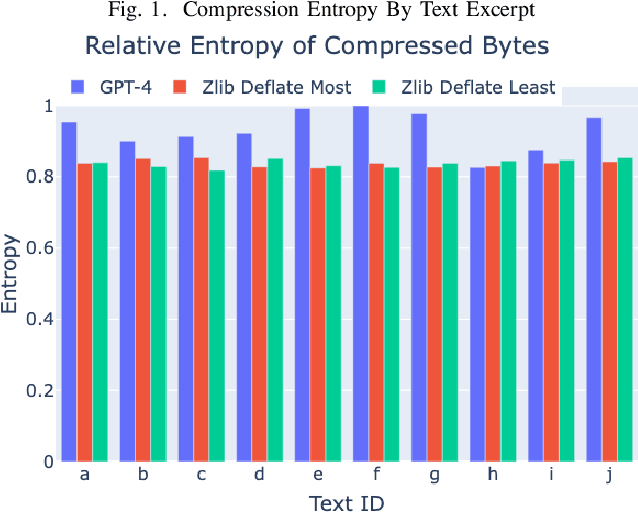
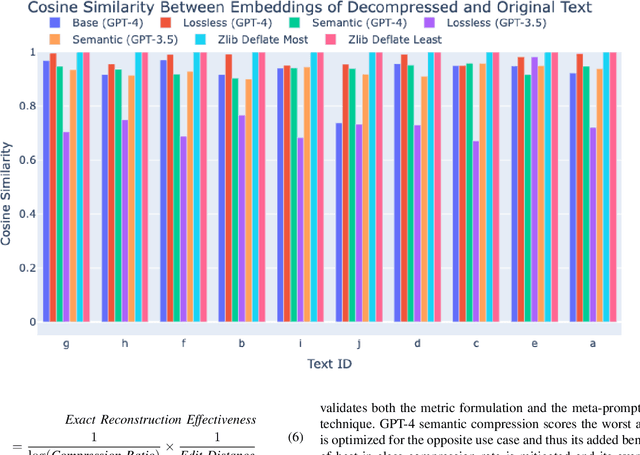
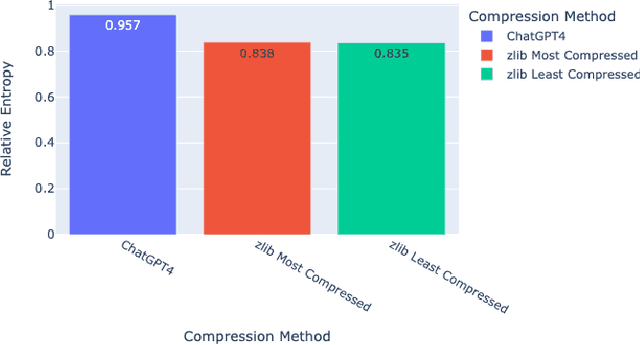
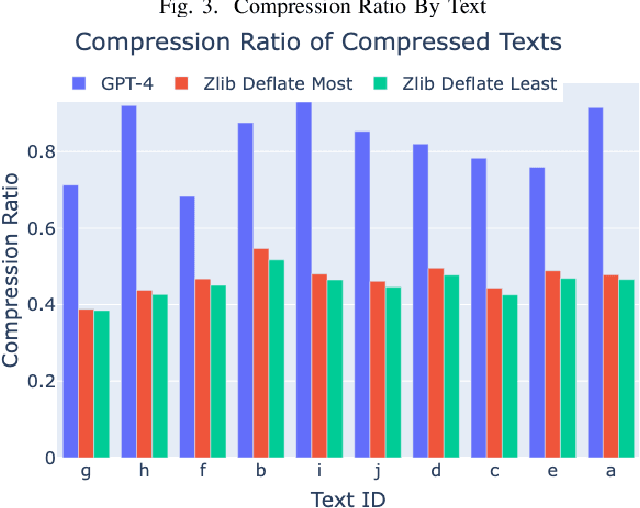
The rise of large language models (LLMs) is revolutionizing information retrieval, question answering, summarization, and code generation tasks. However, in addition to confidently presenting factually inaccurate information at times (known as "hallucinations"), LLMs are also inherently limited by the number of input and output tokens that can be processed at once, making them potentially less effective on tasks that require processing a large set or continuous stream of information. A common approach to reducing the size of data is through lossless or lossy compression. Yet, in some cases it may not be strictly necessary to perfectly recover every detail from the original data, as long as a requisite level of semantic precision or intent is conveyed. This paper presents three contributions to research on LLMs. First, we present the results from experiments exploring the viability of approximate compression using LLMs, focusing specifically on GPT-3.5 and GPT-4 via ChatGPT interfaces. Second, we investigate and quantify the capability of LLMs to compress text and code, as well as to recall and manipulate compressed representations of prompts. Third, we present two novel metrics -- Exact Reconstructive Effectiveness (ERE) and Semantic Reconstruction Effectiveness (SRE) -- that quantify the level of preserved intent between text compressed and decompressed by the LLMs we studied. Our initial results indicate that GPT-4 can effectively compress and reconstruct text while preserving the semantic essence of the original text, providing a path to leverage $\sim$5$\times$ more tokens than present limits allow.
ChatGPT Prompt Patterns for Improving Code Quality, Refactoring, Requirements Elicitation, and Software Design
Mar 11, 2023

This paper presents prompt design techniques for software engineering, in the form of patterns, to solve common problems when using large language models (LLMs), such as ChatGPT to automate common software engineering activities, such as ensuring code is decoupled from third-party libraries and simulating a web application API before it is implemented. This paper provides two contributions to research on using LLMs for software engineering. First, it provides a catalog of patterns for software engineering that classifies patterns according to the types of problems they solve. Second, it explores several prompt patterns that have been applied to improve requirements elicitation, rapid prototyping, code quality, refactoring, and system design.
A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT
Feb 21, 2023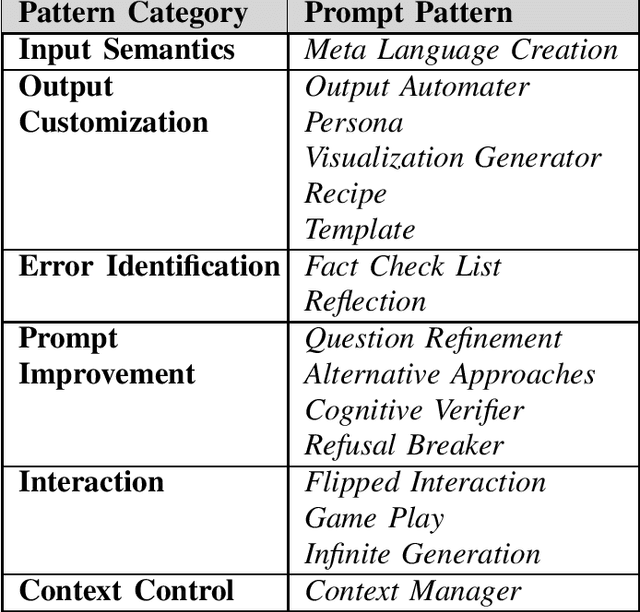
Prompt engineering is an increasingly important skill set needed to converse effectively with large language models (LLMs), such as ChatGPT. Prompts are instructions given to an LLM to enforce rules, automate processes, and ensure specific qualities (and quantities) of generated output. Prompts are also a form of programming that can customize the outputs and interactions with an LLM. This paper describes a catalog of prompt engineering techniques presented in pattern form that have been applied to solve common problems when conversing with LLMs. Prompt patterns are a knowledge transfer method analogous to software patterns since they provide reusable solutions to common problems faced in a particular context, i.e., output generation and interaction when working with LLMs. This paper provides the following contributions to research on prompt engineering that apply LLMs to automate software development tasks. First, it provides a framework for documenting patterns for structuring prompts to solve a range of problems so that they can be adapted to different domains. Second, it presents a catalog of patterns that have been applied successfully to improve the outputs of LLM conversations. Third, it explains how prompts can be built from multiple patterns and illustrates prompt patterns that benefit from combination with other prompt patterns.