 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOVID-19 India Dataset: Parsing Detailed COVID-19 Data in Daily Health Bulletins from States in India
Paper and Code
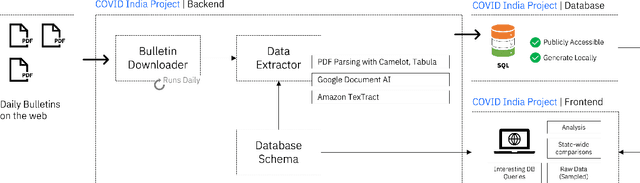
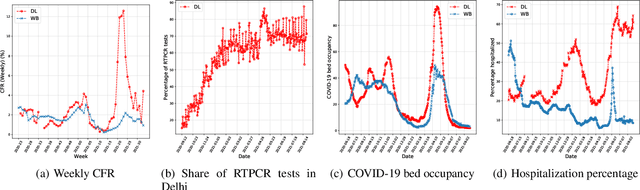
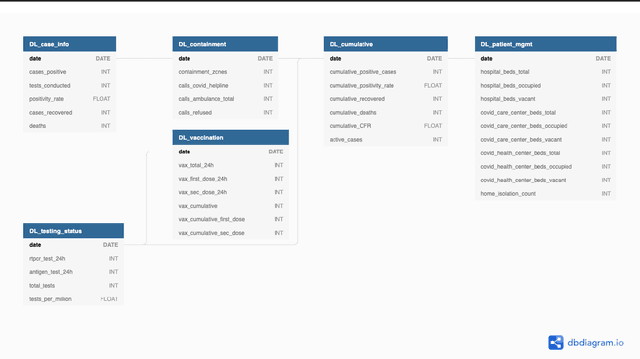
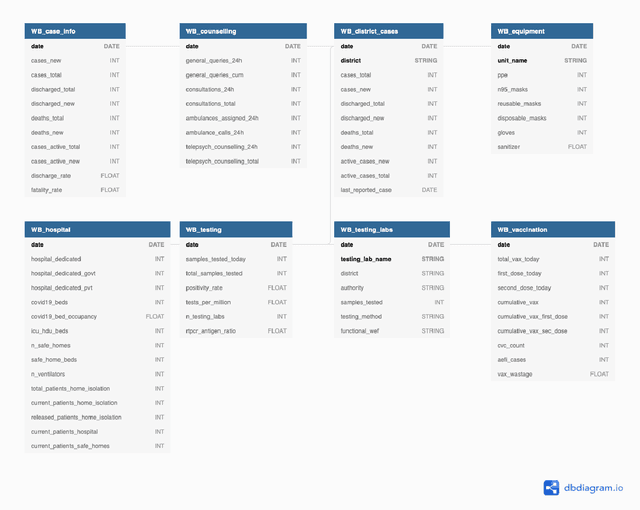
While India remains one of the hotspots of the COVID-19 pandemic, data about the pandemic from the country has proved to be largely inaccessible for use at scale. Much of the data exists in an unstructured form on the web, and limited aspects of such data are available through public APIs maintained manually through volunteer efforts. This has proved to be difficult both in terms of ease of access to detailed data as well as with regards to the maintenance of manual data-keeping over time. This paper reports on a recently launched project aimed at automating the extraction of such data from public health bulletins with the help of a combination of classical PDF parsers as well as state-of-the-art ML-based documents extraction APIs. In this paper, we will describe the automated data-extraction technique, the nature of the generated data, and exciting avenues of ongoing work.