 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-Aware Branching for Improved Mathematical Reasoning
Mar 27, 2025While Large Language Models (LLMs) are effectively aligned through extensive pre-training and fine-tuning, they still struggle with varying levels of uncertainty during token generation. In our investigation of mathematical reasoning, we observe that errors are more likely to arise at tokens exhibiting high entropy and variance of entropy in the model's output distribution. Based on the observation, we propose a novel approach that dynamically branches the generation process on demand instead of defaulting to the single most probable token. By exploring in parallel multiple branches stemming from high probability tokens of critical decision points, the model can discover diverse reasoning paths that might otherwise be missed. We further harness external feedback from larger models to rank and select the most coherent and accurate reasoning branch. Our experimental results on mathematical word problems and calculation questions show that this branching strategy boosts the reasoning capabilities of small LLMs up to 4.6% compared to conventional argmax decoding.
Can GPT models be Financial Analysts? An Evaluation of ChatGPT and GPT-4 on mock CFA Exams
Oct 12, 2023



Large Language Models (LLMs) have demonstrated remarkable performance on a wide range of Natural Language Processing (NLP) tasks, often matching or even beating state-of-the-art task-specific models. This study aims at assessing the financial reasoning capabilities of LLMs. We leverage mock exam questions of the Chartered Financial Analyst (CFA) Program to conduct a comprehensive evaluation of ChatGPT and GPT-4 in financial analysis, considering Zero-Shot (ZS), Chain-of-Thought (CoT), and Few-Shot (FS) scenarios. We present an in-depth analysis of the models' performance and limitations, and estimate whether they would have a chance at passing the CFA exams. Finally, we outline insights into potential strategies and improvements to enhance the applicability of LLMs in finance. In this perspective, we hope this work paves the way for future studies to continue enhancing LLMs for financial reasoning through rigorous evaluation.
MACQ: A Holistic View of Model Acquisition Techniques
Jun 14, 2022
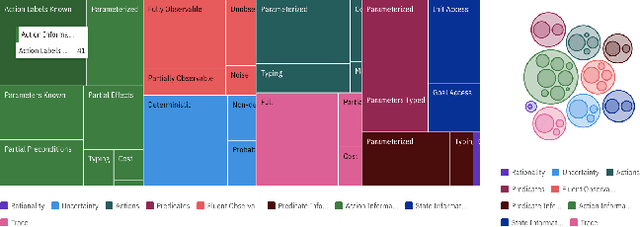
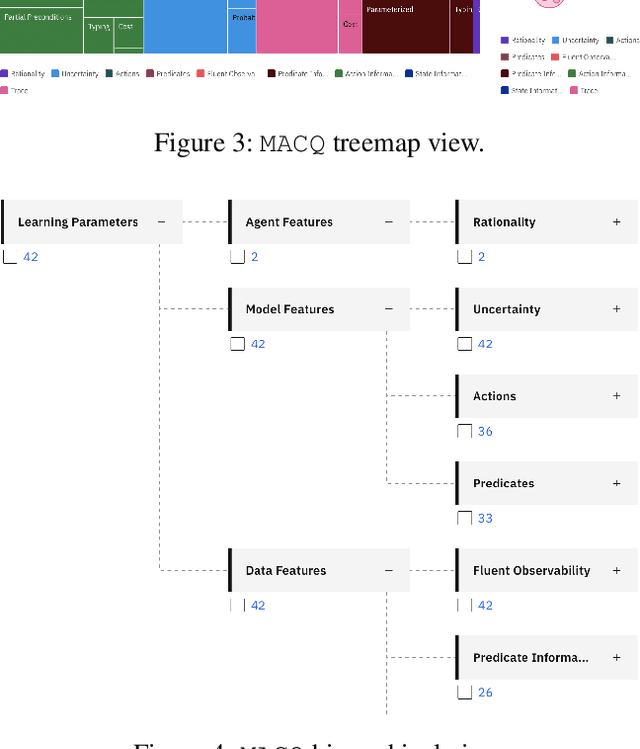
For over three decades, the planning community has explored countless methods for data-driven model acquisition. These range in sophistication (e.g., simple set operations to full-blown reformulations), methodology (e.g., logic-based vs. planing-based), and assumptions (e.g., fully vs. partially observable). With no fewer than 43 publications in the space, it can be overwhelming to understand what approach could or should be applied in a new setting. We present a holistic characterization of the action model acquisition space and further introduce a unifying framework for automated action model acquisition. We have re-implemented some of the landmark approaches in the area, and our characterization of all the techniques offers deep insight into the research opportunities that remain; i.e., those settings where no technique is capable of solving.