 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Context Long-Form Question Answering for Legal Domain
Feb 06, 2026Legal documents have complex document layouts involving multiple nested sections, lengthy footnotes and further use specialized linguistic devices like intricate syntax and domain-specific vocabulary to ensure precision and authority. These inherent characteristics of legal documents make question answering challenging, and particularly so when the answer to the question spans several pages (i.e. requires long-context) and is required to be comprehensive (i.e. a long-form answer). In this paper, we address the challenges of long-context question answering in context of long-form answers given the idiosyncrasies of legal documents. We propose a question answering system that can (a) deconstruct domain-specific vocabulary for better retrieval from source documents, (b) parse complex document layouts while isolating sections and footnotes and linking them appropriately, (c) generate comprehensive answers using precise domain-specific vocabulary. We also introduce a coverage metric that classifies the performance into recall-based coverage categories allowing human users to evaluate the recall with ease. We curate a QA dataset by leveraging the expertise of professionals from fields such as law and corporate tax. Through comprehensive experiments and ablation studies, we demonstrate the usability and merit of the proposed system.
AWARE, Beyond Sentence Boundaries: A Contextual Transformer Framework for Identifying Cultural Capital in STEM Narratives
Oct 06, 2025



Identifying cultural capital (CC) themes in student reflections can offer valuable insights that help foster equitable learning environments in classrooms. However, themes such as aspirational goals or family support are often woven into narratives, rather than appearing as direct keywords. This makes them difficult to detect for standard NLP models that process sentences in isolation. The core challenge stems from a lack of awareness, as standard models are pre-trained on general corpora, leaving them blind to the domain-specific language and narrative context inherent to the data. To address this, we introduce AWARE, a framework that systematically attempts to improve a transformer model's awareness for this nuanced task. AWARE has three core components: 1) Domain Awareness, adapting the model's vocabulary to the linguistic style of student reflections; 2) Context Awareness, generating sentence embeddings that are aware of the full essay context; and 3) Class Overlap Awareness, employing a multi-label strategy to recognize the coexistence of themes in a single sentence. Our results show that by making the model explicitly aware of the properties of the input, AWARE outperforms a strong baseline by 2.1 percentage points in Macro-F1 and shows considerable improvements across all themes. This work provides a robust and generalizable methodology for any text classification task in which meaning depends on the context of the narrative.
Planning for Attacker Entrapment in Adversarial Settings
Mar 01, 2023In this paper, we propose a planning framework to generate a defense strategy against an attacker who is working in an environment where a defender can operate without the attacker's knowledge. The objective of the defender is to covertly guide the attacker to a trap state from which the attacker cannot achieve their goal. Further, the defender is constrained to achieve its goal within K number of steps, where K is calculated as a pessimistic lower bound within which the attacker is unlikely to suspect a threat in the environment. Such a defense strategy is highly useful in real world systems like honeypots or honeynets, where an unsuspecting attacker interacts with a simulated production system while assuming it is the actual production system. Typically, the interaction between an attacker and a defender is captured using game theoretic frameworks. Our problem formulation allows us to capture it as a much simpler infinite horizon discounted MDP, in which the optimal policy for the MDP gives the defender's strategy against the actions of the attacker. Through empirical evaluation, we show the merits of our problem formulation.
Planning for Proactive Assistance in Environments with Partial Observability
May 02, 2021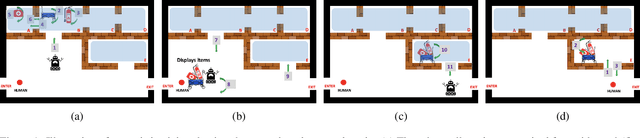
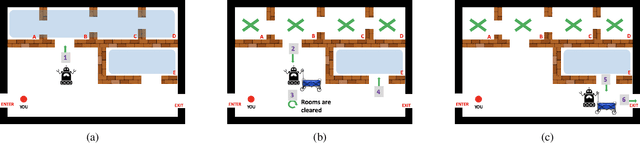
This paper addresses the problem of synthesizing the behavior of an AI agent that provides proactive task assistance to a human in settings like factory floors where they may coexist in a common environment. Unlike in the case of requested assistance, the human may not be expecting proactive assistance and hence it is crucial for the agent to ensure that the human is aware of how the assistance affects her task. This becomes harder when there is a possibility that the human may neither have full knowledge of the AI agent's capabilities nor have full observability of its activities. Therefore, our \textit{proactive assistant} is guided by the following three principles: \textbf{(1)} its activity decreases the human's cost towards her goal; \textbf{(2)} the human is able to recognize the potential reduction in her cost; \textbf{(3)} its activity optimizes the human's overall cost (time/resources) of achieving her goal. Through empirical evaluation and user studies, we demonstrate the usefulness of our approach.
A Unifying Bayesian Formulation of Measures of Interpretability in Human-AI
Apr 21, 2021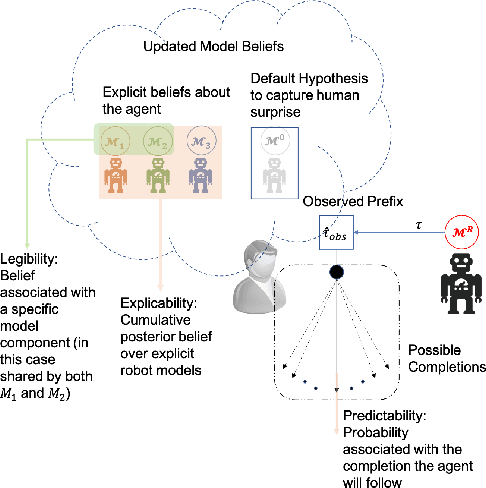
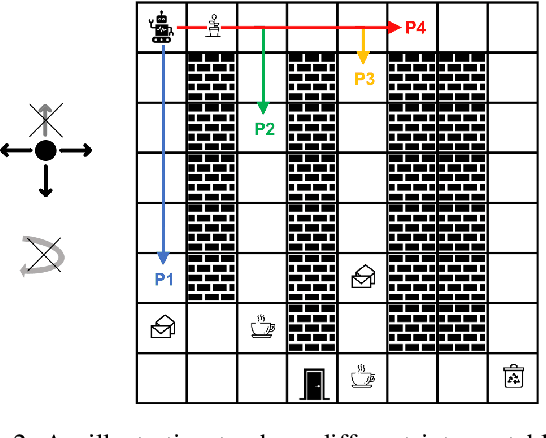
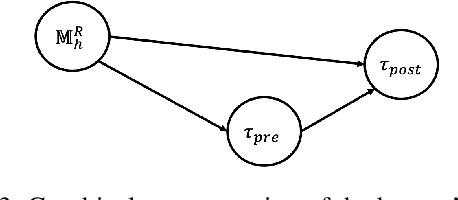
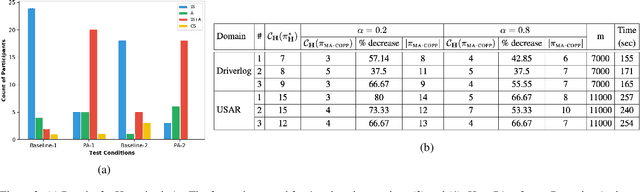
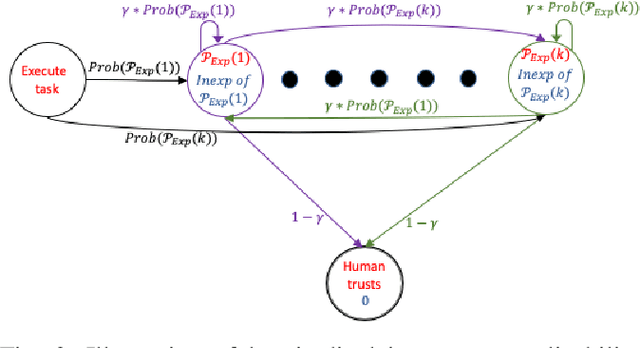
Existing approaches for generating human-aware agent behaviors have considered different measures of interpretability in isolation. Further, these measures have been studied under differing assumptions, thus precluding the possibility of designing a single framework that captures these measures under the same assumptions. In this paper, we present a unifying Bayesian framework that models a human observer's evolving beliefs about an agent and thereby define the problem of Generalized Human-Aware Planning. We will show that the definitions of interpretability measures like explicability, legibility and predictability from the prior literature fall out as special cases of our general framework. Through this framework, we also bring a previously ignored fact to light that the human-robot interactions are in effect open-world problems, particularly as a result of modeling the human's beliefs over the agent. Since the human may not only hold beliefs unknown to the agent but may also form new hypotheses about the agent when presented with novel or unexpected behaviors.
A Bayesian Account of Measures of Interpretability in Human-AI Interaction
Nov 22, 2020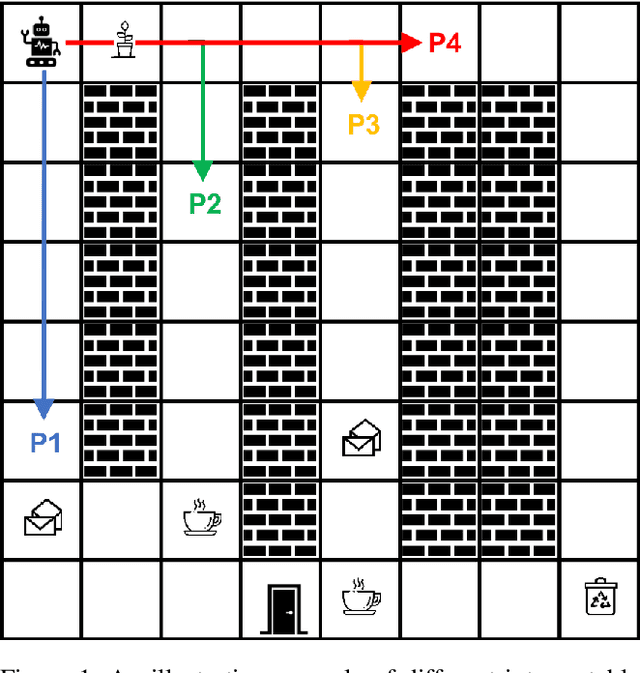
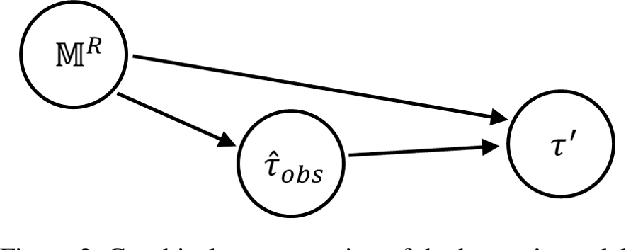
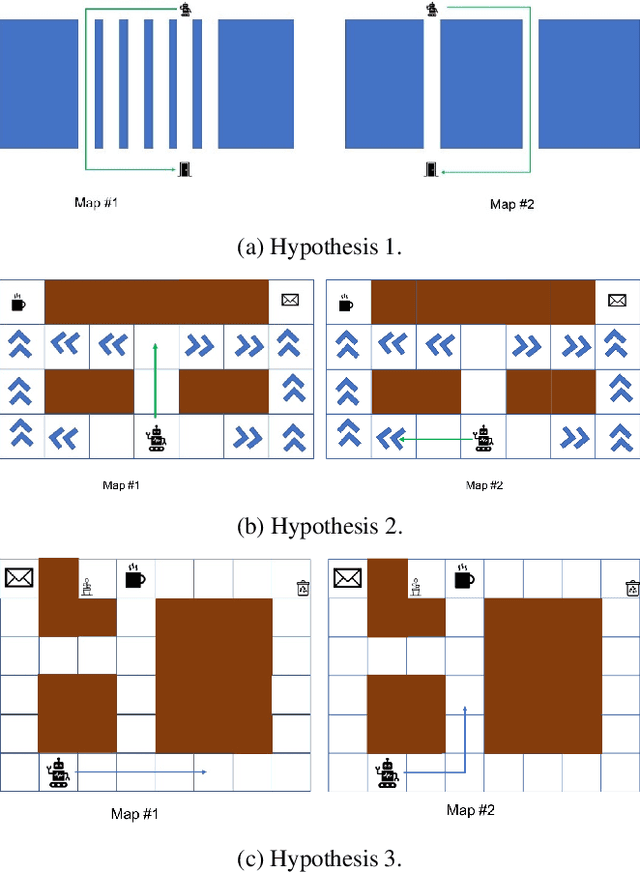
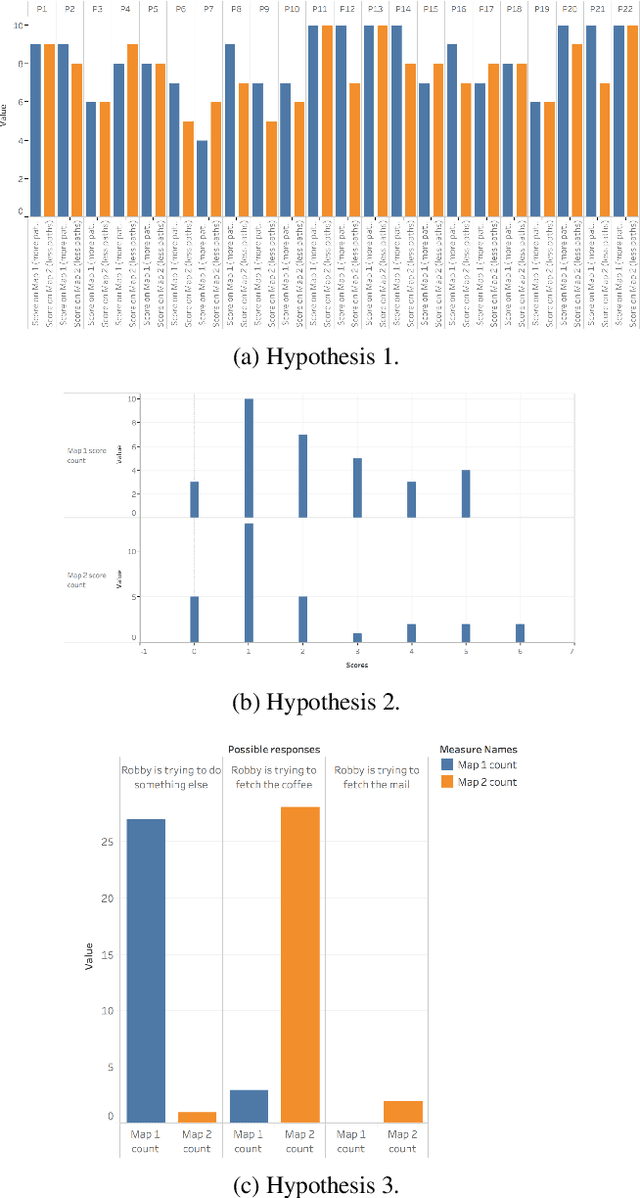
Existing approaches for the design of interpretable agent behavior consider different measures of interpretability in isolation. In this paper we posit that, in the design and deployment of human-aware agents in the real world, notions of interpretability are just some among many considerations; and the techniques developed in isolation lack two key properties to be useful when considered together: they need to be able to 1) deal with their mutually competing properties; and 2) an open world where the human is not just there to interpret behavior in one specific form. To this end, we consider three well-known instances of interpretable behavior studied in existing literature -- namely, explicability, legibility, and predictability -- and propose a revised model where all these behaviors can be meaningfully modeled together. We will highlight interesting consequences of this unified model and motivate, through results of a user study, why this revision is necessary.
Designing Environments Conducive to Interpretable Robot Behavior
Jul 02, 2020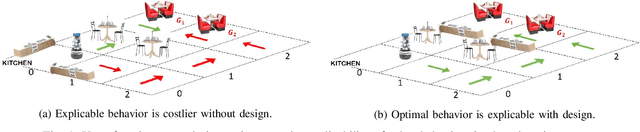
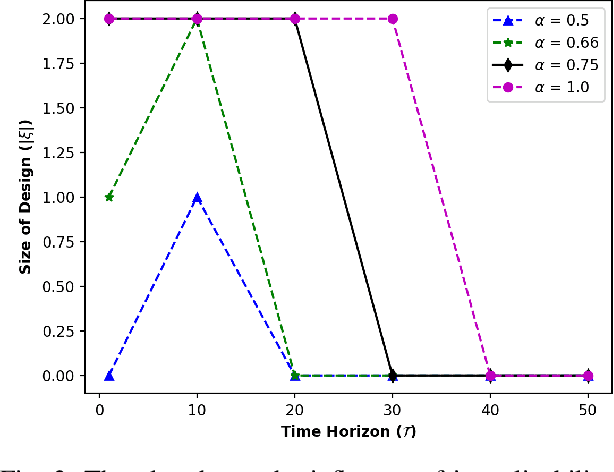
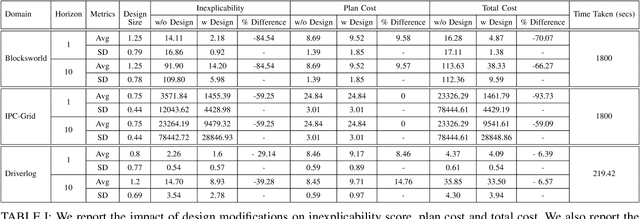
Designing robots capable of generating interpretable behavior is a prerequisite for achieving effective human-robot collaboration. This means that the robots need to be capable of generating behavior that aligns with human expectations and, when required, provide explanations to the humans in the loop. However, exhibiting such behavior in arbitrary environments could be quite expensive for robots, and in some cases, the robot may not even be able to exhibit the expected behavior. Given structured environments (like warehouses and restaurants), it may be possible to design the environment so as to boost the interpretability of the robot's behavior or to shape the human's expectations of the robot's behavior. In this paper, we investigate the opportunities and limitations of environment design as a tool to promote a type of interpretable behavior -- known in the literature as explicable behavior. We formulate a novel environment design framework that considers design over multiple tasks and over a time horizon. In addition, we explore the longitudinal aspect of explicable behavior and the trade-off that arises between the cost of design and the cost of generating explicable behavior over a time horizon.
Balancing Goal Obfuscation and Goal Legibility in Settings with Cooperative and Adversarial Observers
May 25, 2019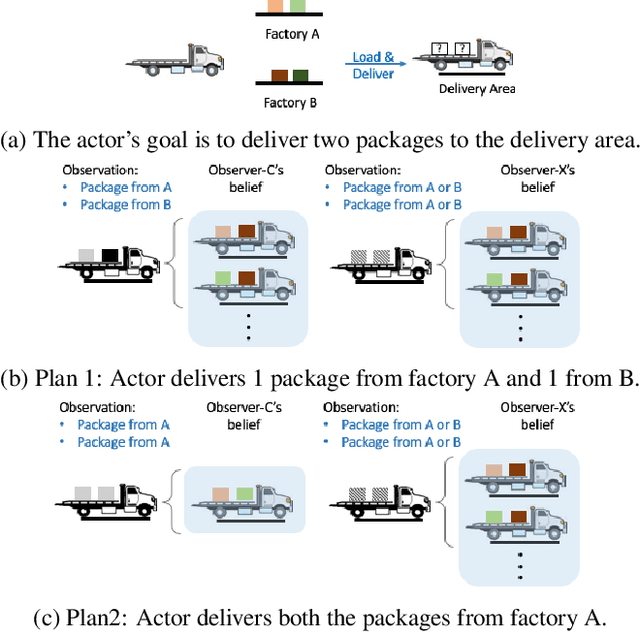
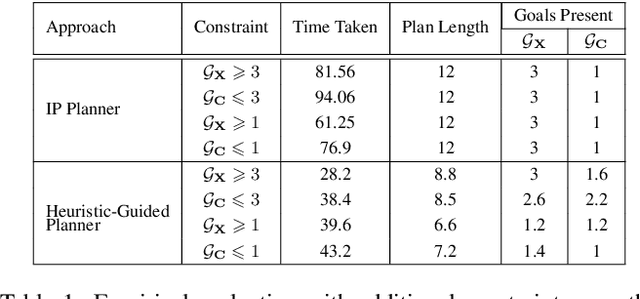
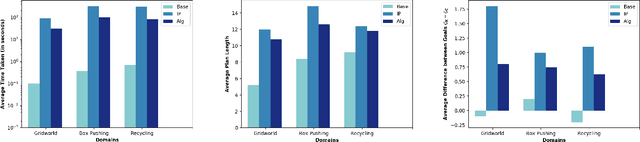
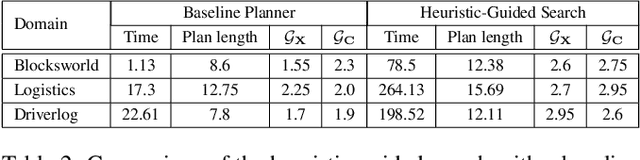
In order to be useful in the real world, AI agents need to plan and act in the presence of others, who may include adversarial and cooperative entities. In this paper, we consider the problem where an autonomous agent needs to act in a manner that clarifies its objectives to cooperative entities while preventing adversarial entities from inferring those objectives. We show that this problem is solvable when cooperative entities and adversarial entities use different types of sensors and/or prior knowledge. We develop two new solution approaches for computing such plans. One approach provides an optimal solution to the problem by using an IP solver to provide maximum obfuscation for adversarial entities while providing maximum legibility for cooperative entities in the environment, whereas the other approach provides a satisficing solution using heuristic-guided forward search to achieve preset levels of obfuscation and legibility for adversarial and cooperative entities respectively. We show the feasibility and utility of our algorithms through extensive empirical evaluation on problems derived from planning benchmarks.
Explicablility as Minimizing Distance from Expected Behavior
Mar 13, 2019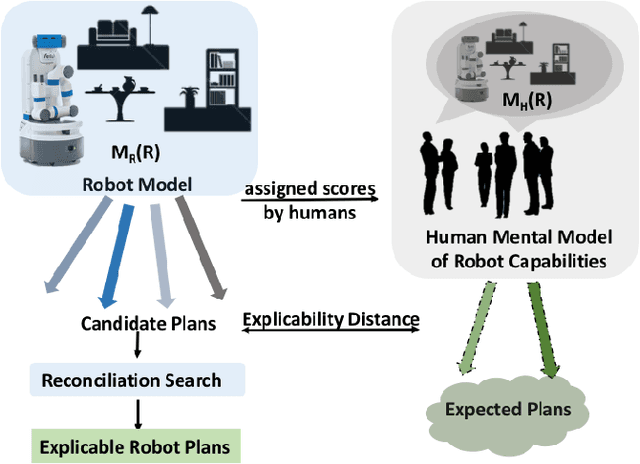
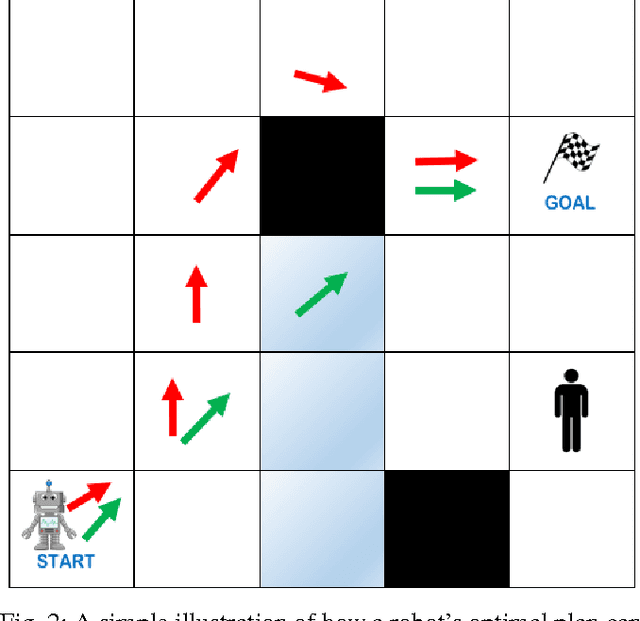
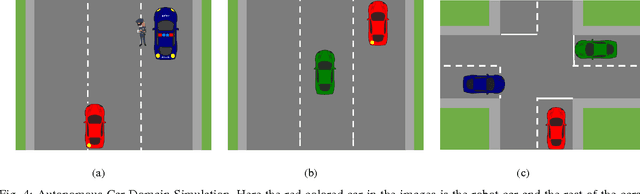
In order to have effective human-AI collaboration, it is necessary to address how the AI agent's behavior is being perceived by the humans-in-the-loop. When the agent's task plans are generated without such considerations, they may often demonstrate inexplicable behavior from the human's point of view. This problem may arise due to the human's partial or inaccurate understanding of the agent's planning model. This may have serious implications from increased cognitive load to more serious concerns of safety around a physical agent. In this paper, we address this issue by modeling plan explicability as a function of the distance between a plan that agent makes and the plan that human expects it to make. We learn a regression model for mapping the plan distances to explicability scores of plans and develop an anytime search algorithm that can use this model as a heuristic to come up with progressively explicable plans. We evaluate the effectiveness of our approach in a simulated autonomous car domain and a physical robot domain.
Explicability? Legibility? Predictability? Transparency? Privacy? Security? The Emerging Landscape of Interpretable Agent Behavior
Nov 23, 2018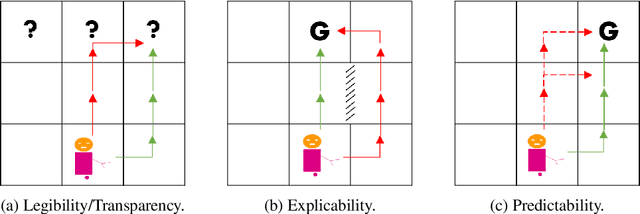
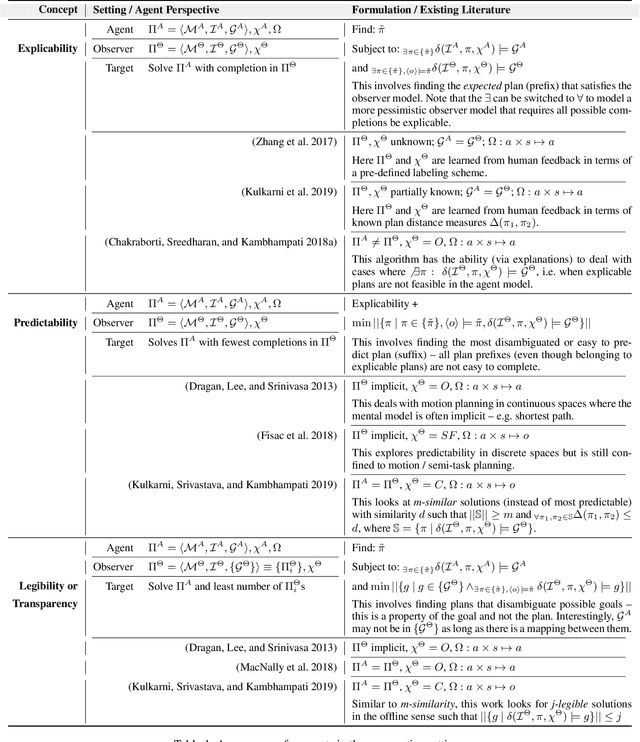
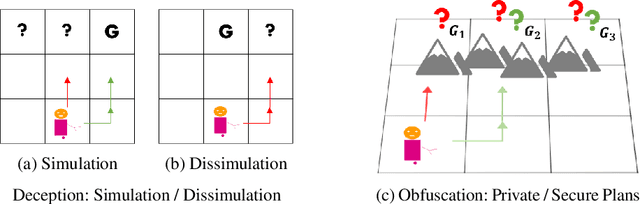
There has been significant interest of late in generating behavior of agents that is interpretable to the human (observer) in the loop. However, the work in this area has typically lacked coherence on the topic, with proposed solutions for "explicable", "legible", "predictable" and "transparent" planning with overlapping, and sometimes conflicting, semantics all aimed at some notion of understanding what intentions the observer will ascribe to an agent by observing its behavior. This is also true for the recent works on "security" and "privacy" of plans which are also trying to answer the same question, but from the opposite point of view -- i.e. when the agent is trying to hide instead of revealing its intentions. This paper attempts to provide a workable taxonomy of relevant concepts in this exciting and emerging field of inquiry.