 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMILO: Model-Agnostic Subset Selection Framework for Efficient Model Training and Tuning
Feb 05, 2023



Training deep networks and tuning hyperparameters on large datasets is computationally intensive. One of the primary research directions for efficient training is to reduce training costs by selecting well-generalizable subsets of training data. Compared to simple adaptive random subset selection baselines, existing intelligent subset selection approaches are not competitive due to the time-consuming subset selection step, which involves computing model-dependent gradients and feature embeddings and applies greedy maximization of submodular objectives. Our key insight is that removing the reliance on downstream model parameters enables subset selection as a pre-processing step and enables one to train multiple models at no additional cost. In this work, we propose MILO, a model-agnostic subset selection framework that decouples the subset selection from model training while enabling superior model convergence and performance by using an easy-to-hard curriculum. Our empirical results indicate that MILO can train models $3\times - 10 \times$ faster and tune hyperparameters $20\times - 75 \times$ faster than full-dataset training or tuning without compromising performance.
AUTOMATA: Gradient Based Data Subset Selection for Compute-Efficient Hyper-parameter Tuning
Mar 15, 2022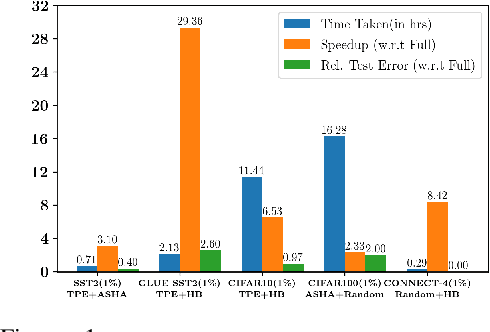
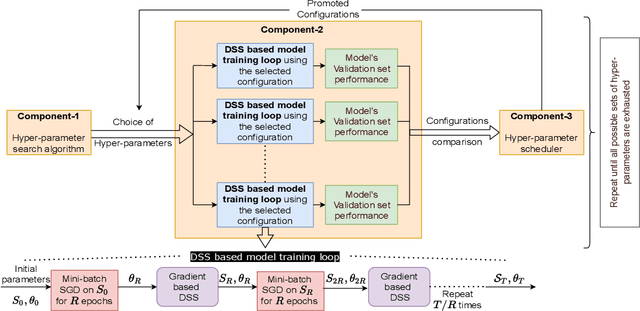

Deep neural networks have seen great success in recent years; however, training a deep model is often challenging as its performance heavily depends on the hyper-parameters used. In addition, finding the optimal hyper-parameter configuration, even with state-of-the-art (SOTA) hyper-parameter optimization (HPO) algorithms, can be time-consuming, requiring multiple training runs over the entire dataset for different possible sets of hyper-parameters. Our central insight is that using an informative subset of the dataset for model training runs involved in hyper-parameter optimization, allows us to find the optimal hyper-parameter configuration significantly faster. In this work, we propose AUTOMATA, a gradient-based subset selection framework for hyper-parameter tuning. We empirically evaluate the effectiveness of AUTOMATA in hyper-parameter tuning through several experiments on real-world datasets in the text, vision, and tabular domains. Our experiments show that using gradient-based data subsets for hyper-parameter tuning achieves significantly faster turnaround times and speedups of 3$\times$-30$\times$ while achieving comparable performance to the hyper-parameters found using the entire dataset.
Declarative Machine Learning - A Classification of Basic Properties and Types
May 19, 2016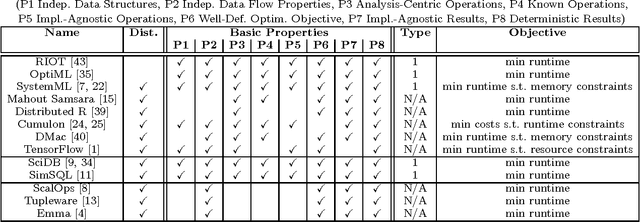

Declarative machine learning (ML) aims at the high-level specification of ML tasks or algorithms, and automatic generation of optimized execution plans from these specifications. The fundamental goal is to simplify the usage and/or development of ML algorithms, which is especially important in the context of large-scale computations. However, ML systems at different abstraction levels have emerged over time and accordingly there has been a controversy about the meaning of this general definition of declarative ML. Specification alternatives range from ML algorithms expressed in domain-specific languages (DSLs) with optimization for performance, to ML task (learning problem) specifications with optimization for performance and accuracy. We argue that these different types of declarative ML complement each other as they address different users (data scientists and end users). This paper makes an attempt to create a taxonomy for declarative ML, including a definition of essential basic properties and types of declarative ML. Along the way, we provide insights into implications of these properties. We also use this taxonomy to classify existing systems. Finally, we draw conclusions on defining appropriate benchmarks and specification languages for declarative ML.