 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemPipes -- Optimizable Semantic Data Operators for Tabular Machine Learning Pipelines
Feb 04, 2026Real-world machine learning on tabular data relies on complex data preparation pipelines for prediction, data integration, augmentation, and debugging. Designing these pipelines requires substantial domain expertise and engineering effort, motivating the question of how large language models (LLMs) can support tabular ML through code synthesis. We introduce SemPipes, a novel declarative programming model that integrates LLM-powered semantic data operators into tabular ML pipelines. Semantic operators specify data transformations in natural language while delegating execution to a runtime system. During training, SemPipes synthesizes custom operator implementations based on data characteristics, operator instructions, and pipeline context. This design enables the automatic optimization of data operations in a pipeline via LLM-based code synthesis guided by evolutionary search. We evaluate SemPipes across diverse tabular ML tasks and show that semantic operators substantially improve end-to-end predictive performance for both expert-designed and agent-generated pipelines, while reducing pipeline complexity. We implement SemPipes in Python and release it at https://github.com/deem-data/sempipes/tree/v1.
Morphing-based Compression for Data-centric ML Pipelines
Apr 15, 2025Data-centric ML pipelines extend traditional machine learning (ML) pipelines -- of feature transformations and ML model training -- by outer loops for data cleaning, augmentation, and feature engineering to create high-quality input data. Existing lossless matrix compression applies lightweight compression schemes to numeric matrices and performs linear algebra operations such as matrix-vector multiplications directly on the compressed representation but struggles to efficiently rediscover structural data redundancy. Compressed operations are effective at fitting data in available memory, reducing I/O across the storage-memory-cache hierarchy, and improving instruction parallelism. The applied data cleaning, augmentation, and feature transformations provide a rich source of information about data characteristics such as distinct items, column sparsity, and column correlations. In this paper, we introduce BWARE -- an extension of AWARE for workload-aware lossless matrix compression -- that pushes compression through feature transformations and engineering to leverage information about structural transformations. Besides compressed feature transformations, we introduce a novel technique for lightweight morphing of a compressed representation into workload-optimized compressed representations without decompression. BWARE shows substantial end-to-end runtime improvements, reducing the execution time for training data-centric ML pipelines from days to hours.
CAMEO: Autocorrelation-Preserving Line Simplification for Lossy Time Series Compression
Jan 24, 2025



Time series data from a variety of sensors and IoT devices need effective compression to reduce storage and I/O bandwidth requirements. While most time series databases and systems rely on lossless compression, lossy techniques offer even greater space-saving with a small loss in precision. However, the unknown impact on downstream analytics applications requires a semi-manual trial-and-error exploration. We initiate work on lossy compression that provides guarantees on complex statistical features (which are strongly correlated with the accuracy of the downstream analytics). Specifically, we propose a new lossy compression method that provides guarantees on the autocorrelation and partial-autocorrelation functions (ACF/PACF) of a time series. Our method leverages line simplification techniques as well as incremental maintenance of aggregates, blocking, and parallelization strategies for effective and efficient compression. The results show that our method improves compression ratios by 2x on average and up to 54x on selected datasets, compared to previous lossy and lossless compression methods. Moreover, we maintain -- and sometimes even improve -- the forecasting accuracy by preserving the autocorrelation properties of the time series. Our framework is extensible to multivariate time series and other statistical features of the time series.
Deep Learning with Apache SystemML
Feb 08, 2018Enterprises operate large data lakes using Hadoop and Spark frameworks that (1) run a plethora of tools to automate powerful data preparation/transformation pipelines, (2) run on shared, large clusters to (3) perform many different analytics tasks ranging from model preparation, building, evaluation, and tuning for both machine learning and deep learning. Developing machine/deep learning models on data in such shared environments is challenging. Apache SystemML provides a unified framework for implementing machine learning and deep learning algorithms in a variety of shared deployment scenarios. SystemML's novel compilation approach automatically generates runtime execution plans for machine/deep learning algorithms that are composed of single-node and distributed runtime operations depending on data and cluster characteristics such as data size, data sparsity, cluster size, and memory configurations, while still exploiting the capabilities of the underlying big data frameworks.
Declarative Machine Learning - A Classification of Basic Properties and Types
May 19, 2016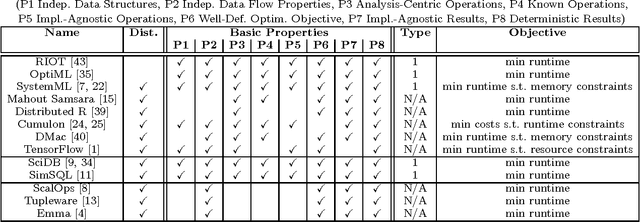

Declarative machine learning (ML) aims at the high-level specification of ML tasks or algorithms, and automatic generation of optimized execution plans from these specifications. The fundamental goal is to simplify the usage and/or development of ML algorithms, which is especially important in the context of large-scale computations. However, ML systems at different abstraction levels have emerged over time and accordingly there has been a controversy about the meaning of this general definition of declarative ML. Specification alternatives range from ML algorithms expressed in domain-specific languages (DSLs) with optimization for performance, to ML task (learning problem) specifications with optimization for performance and accuracy. We argue that these different types of declarative ML complement each other as they address different users (data scientists and end users). This paper makes an attempt to create a taxonomy for declarative ML, including a definition of essential basic properties and types of declarative ML. Along the way, we provide insights into implications of these properties. We also use this taxonomy to classify existing systems. Finally, we draw conclusions on defining appropriate benchmarks and specification languages for declarative ML.
Costing Generated Runtime Execution Plans for Large-Scale Machine Learning Programs
Mar 22, 2015
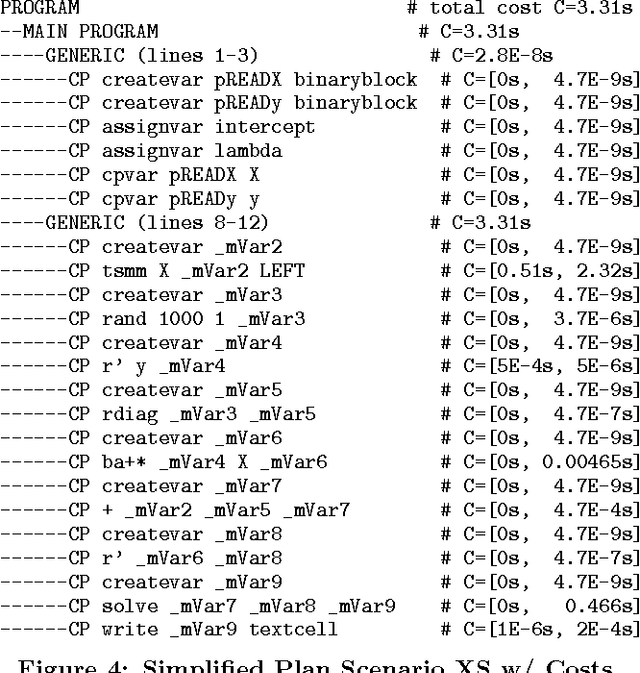

Declarative large-scale machine learning (ML) aims at the specification of ML algorithms in a high-level language and automatic generation of hybrid runtime execution plans ranging from single node, in-memory computations to distributed computations on MapReduce (MR) or similar frameworks like Spark. The compilation of large-scale ML programs exhibits many opportunities for automatic optimization. Advanced cost-based optimization techniques require---as a fundamental precondition---an accurate cost model for evaluating the impact of optimization decisions. In this paper, we share insights into a simple and robust yet accurate technique for costing alternative runtime execution plans of ML programs. Our cost model relies on generating and costing runtime plans in order to automatically reflect all successive optimization phases. Costing runtime plans also captures control flow structures such as loops and branches, and a variety of cost factors like IO, latency, and computation costs. Finally, we linearize all these cost factors into a single measure of expected execution time. Within SystemML, this cost model is leveraged by several advanced optimizers like resource optimization and global data flow optimization. We share our lessons learned in order to provide foundations for the optimization of ML programs.