 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Search of Truth: An Interrogation Approach to Hallucination Detection
Mar 05, 2024



Despite the many advances of Large Language Models (LLMs) and their unprecedented rapid evolution, their impact and integration into every facet of our daily lives is limited due to various reasons. One critical factor hindering their widespread adoption is the occurrence of hallucinations, where LLMs invent answers that sound realistic, yet drift away from factual truth. In this paper, we present a novel method for detecting hallucinations in large language models, which tackles a critical issue in the adoption of these models in various real-world scenarios. Through extensive evaluations across multiple datasets and LLMs, including Llama-2, we study the hallucination levels of various recent LLMs and demonstrate the effectiveness of our method to automatically detect them. Notably, we observe up to 62% hallucinations for Llama-2 in a specific experiment, where our method achieves a Balanced Accuracy (B-ACC) of 87%, all without relying on external knowledge.
GPT-Calls: Enhancing Call Segmentation and Tagging by Generating Synthetic Conversations via Large Language Models
Jun 09, 2023



Transcriptions of phone calls are of significant value across diverse fields, such as sales, customer service, healthcare, and law enforcement. Nevertheless, the analysis of these recorded conversations can be an arduous and time-intensive process, especially when dealing with extended or multifaceted dialogues. In this work, we propose a novel method, GPT-distilled Calls Segmentation and Tagging (GPT-Calls), for efficient and accurate call segmentation and topic extraction. GPT-Calls is composed of offline and online phases. The offline phase is applied once to a given list of topics and involves generating a distribution of synthetic sentences for each topic using a GPT model and extracting anchor vectors. The online phase is applied to every call separately and scores the similarity between the transcripted conversation and the topic anchors found in the offline phase. Then, time domain analysis is applied to the similarity scores to group utterances into segments and tag them with topics. The proposed paradigm provides an accurate and efficient method for call segmentation and topic extraction that does not require labeled data, thus making it a versatile approach applicable to various domains. Our algorithm operates in production under Dynamics 365 Sales Conversation Intelligence, and our research is based on real sales conversations gathered from various Dynamics 365 Sales tenants.
An End-to-End Dialogue Summarization System for Sales Calls
Apr 28, 2022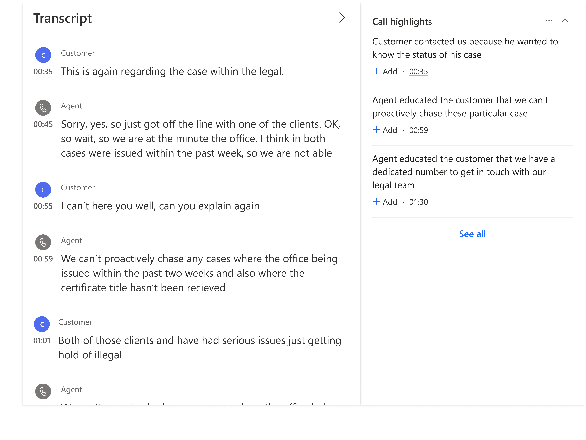
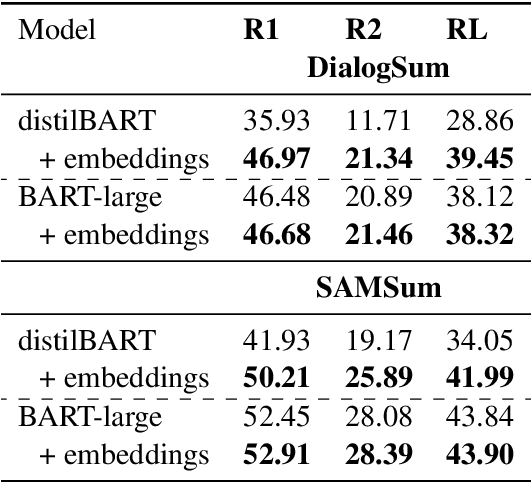
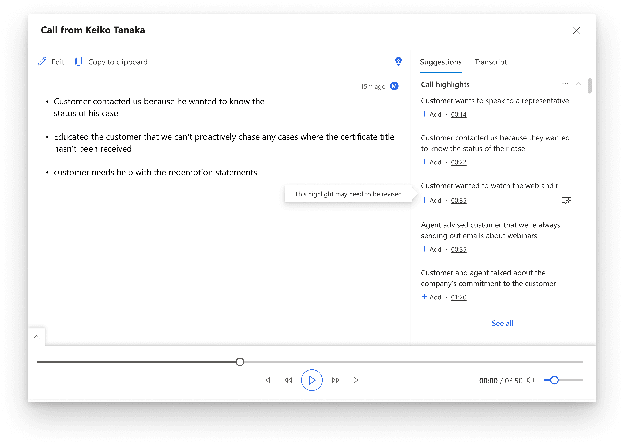
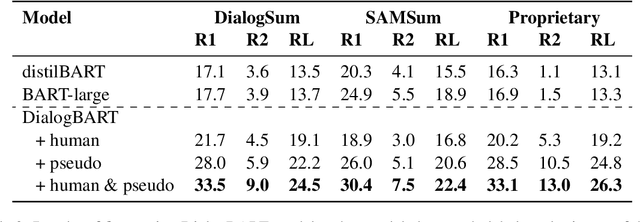
Summarizing sales calls is a routine task performed manually by salespeople. We present a production system which combines generative models fine-tuned for customer-agent setting, with a human-in-the-loop user experience for an interactive summary curation process. We address challenging aspects of dialogue summarization task in a real-world setting including long input dialogues, content validation, lack of labeled data and quality evaluation. We show how GPT-3 can be leveraged as an offline data labeler to handle training data scarcity and accommodate privacy constraints in an industrial setting. Experiments show significant improvements by our models in tackling the summarization and content validation tasks on public datasets.
Learning to Customize Network Security Rules
Dec 28, 2017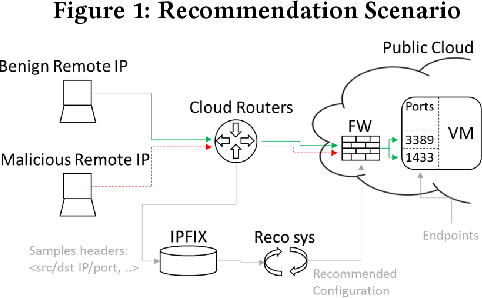
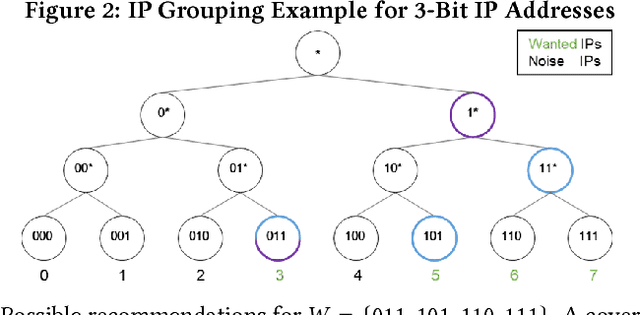


Security is a major concern for organizations who wish to leverage cloud computing. In order to reduce security vulnerabilities, public cloud providers offer firewall functionalities. When properly configured, a firewall protects cloud networks from cyber-attacks. However, proper firewall configuration requires intimate knowledge of the protected system, high expertise and on-going maintenance. As a result, many organizations do not use firewalls effectively, leaving their cloud resources vulnerable. In this paper, we present a novel supervised learning method, and prototype, which compute recommendations for firewall rules. Recommendations are based on sampled network traffic meta-data (NetFlow) collected from a public cloud provider. Labels are extracted from firewall configurations deemed to be authored by experts. NetFlow is collected from network routers, avoiding expensive collection from cloud VMs, as well as relieving privacy concerns. The proposed method captures network routines and dependencies between resources and firewall configuration. The method predicts IPs to be allowed by the firewall. A grouping algorithm is subsequently used to generate a manageable number of IP ranges. Each range is a parameter for a firewall rule. We present results of experiments on real data, showing ROC AUC of 0.92, compared to 0.58 for an unsupervised baseline. The results prove the hypothesis that firewall rules can be automatically generated based on router data, and that an automated method can be effective in blocking a high percentage of malicious traffic.