 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePassive acoustic non-line-of-sight localization without a relay surface
Jun 10, 2025The detection and localization of a source hidden outside the Line-of-Sight (LOS) traditionally rely on the acquisition of indirect signals, such as those reflected from visible relay surfaces such as floors or walls. These reflected signals are then utilized to reconstruct the obscured scene. In this study, we present an approach that utilize signals diffracted from an edge of an obstacle to achieve three-dimensional (3D) localization of an acoustic point source situated outside the LOS. We address two scenarios - a doorway and a convex corner - and propose a localization method for each of them. For the first scenario, we utilize the two edges of the door as virtual detector arrays. For the second scenario, we exploit the spectral signature of a knife-edge diffraction, inspired by the human perception of sound location by the head-related transfer function (HRTF). In both methods, knife-edge diffraction is utilized to extend the capabilities of non-line-of-sight (NLOS) acoustic sensing, enabling localization in environments where conventional relay-surface based approaches may be limited.
Ptychographic lensless coherent endomicroscopy through a flexible fiber bundle
Jan 31, 2024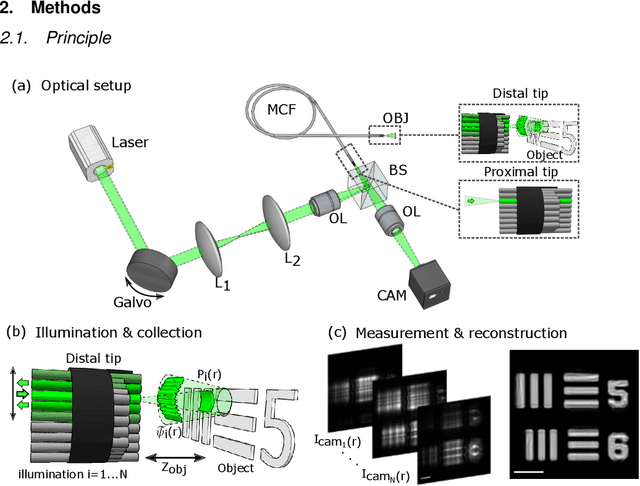

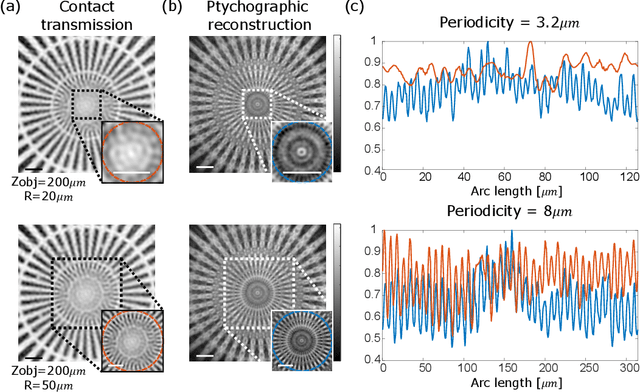

Conventional fiber-bundle-based endoscopes allow minimally invasive imaging through flexible multi-core fiber (MCF) bundles by placing a miniature lens at the distal tip and using each core as an imaging pixel. In recent years, lensless imaging through MCFs was made possible by correcting the core-to-core phase distortions pre-measured in a calibration procedure. However, temporally varying wavefront distortions, for instance, due to dynamic fiber bending, pose a challenge for such approaches. Here, we demonstrate a coherent lensless imaging technique based on intensity-only measurements insensitive to core-to-core phase distortions. We leverage a ptychographic reconstruction algorithm to retrieve the phase and amplitude profiles of reflective objects placed at a distance from the fiber tip, using as input a set of diffracted intensity patterns reflected from the object when the illumination is scanned over the MCF cores. Our approach thus utilizes an acquisition process equivalent to confocal microendoscopy, only replacing the single detector with a camera.
Efficient Discovery and Effective Evaluation of Visual Perceptual Similarity: A Benchmark and Beyond
Aug 28, 2023

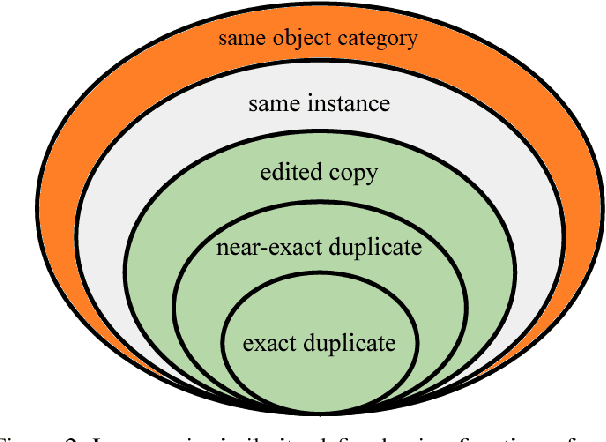
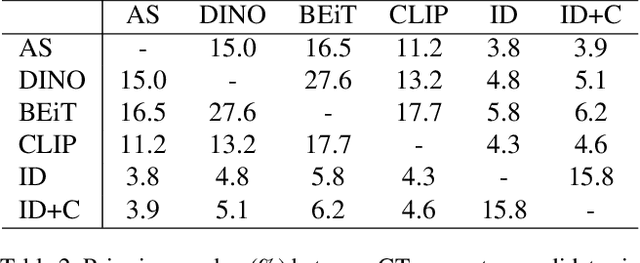
Visual similarities discovery (VSD) is an important task with broad e-commerce applications. Given an image of a certain object, the goal of VSD is to retrieve images of different objects with high perceptual visual similarity. Although being a highly addressed problem, the evaluation of proposed methods for VSD is often based on a proxy of an identification-retrieval task, evaluating the ability of a model to retrieve different images of the same object. We posit that evaluating VSD methods based on identification tasks is limited, and faithful evaluation must rely on expert annotations. In this paper, we introduce the first large-scale fashion visual similarity benchmark dataset, consisting of more than 110K expert-annotated image pairs. Besides this major contribution, we share insight from the challenges we faced while curating this dataset. Based on these insights, we propose a novel and efficient labeling procedure that can be applied to any dataset. Our analysis examines its limitations and inductive biases, and based on these findings, we propose metrics to mitigate those limitations. Though our primary focus lies on visual similarity, the methodologies we present have broader applications for discovering and evaluating perceptual similarity across various domains.
Representation Learning via Variational Bayesian Networks
Jun 28, 2023



We present Variational Bayesian Network (VBN) - a novel Bayesian entity representation learning model that utilizes hierarchical and relational side information and is particularly useful for modeling entities in the ``long-tail'', where the data is scarce. VBN provides better modeling for long-tail entities via two complementary mechanisms: First, VBN employs informative hierarchical priors that enable information propagation between entities sharing common ancestors. Additionally, VBN models explicit relations between entities that enforce complementary structure and consistency, guiding the learned representations towards a more meaningful arrangement in space. Second, VBN represents entities by densities (rather than vectors), hence modeling uncertainty that plays a complementary role in coping with data scarcity. Finally, we propose a scalable Variational Bayes optimization algorithm that enables fast approximate Bayesian inference. We evaluate the effectiveness of VBN on linguistic, recommendations, and medical inference tasks. Our findings show that VBN outperforms other existing methods across multiple datasets, and especially in the long-tail.
K-space interpretation of image-scanning-microscopy
Jan 11, 2023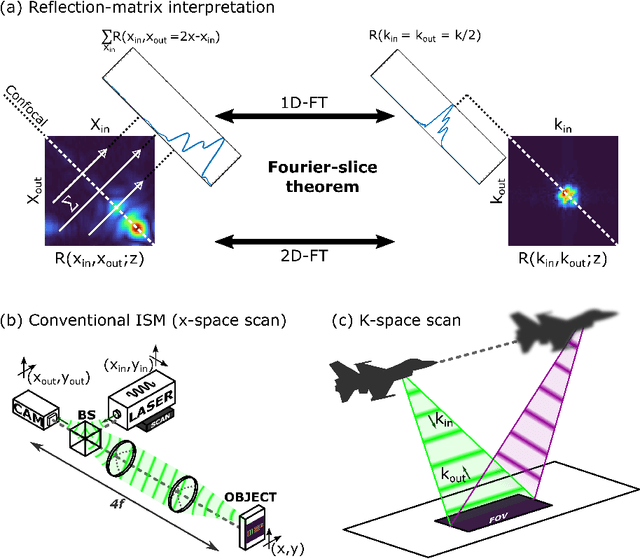
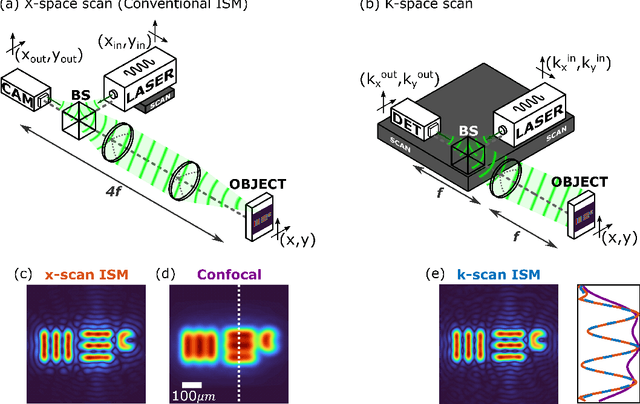
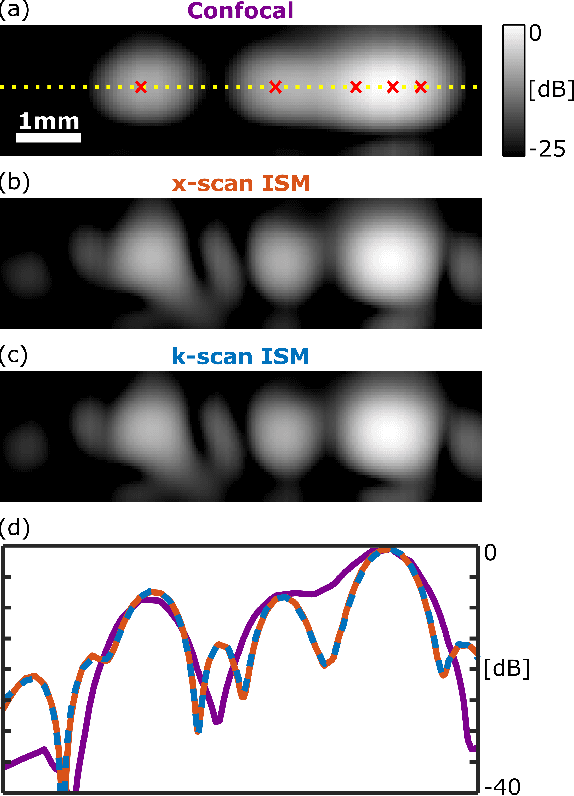
In recent years, image-scanning microscopy (ISM, also termed pixel-reassignment microscopy) has emerged as a technique that improves the resolution and signal-to-noise compared to confocal and widefield microscopy by employing a detector array at the image plane of a confocal laser scanning microscope. Here, we present a k-space analysis of coherent ISM, showing that ISM is equivalent to spotlight synthetic-aperture radar (SAR) and analogous to oblique-illumination microscopy. This insight indicates that ISM can be performed with a single detector placed in the k-space of the sample, which we numerically demonstrate.
Grad-SAM: Explaining Transformers via Gradient Self-Attention Maps
Apr 23, 2022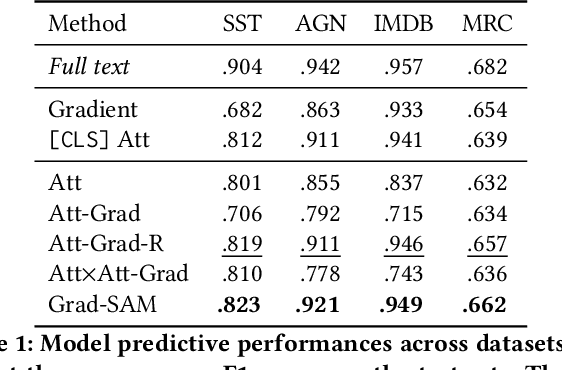
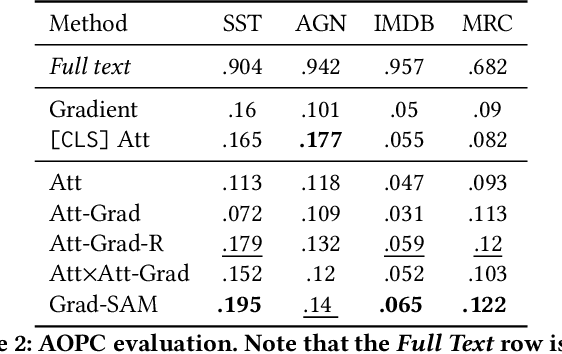

Transformer-based language models significantly advanced the state-of-the-art in many linguistic tasks. As this revolution continues, the ability to explain model predictions has become a major area of interest for the NLP community. In this work, we present Gradient Self-Attention Maps (Grad-SAM) - a novel gradient-based method that analyzes self-attention units and identifies the input elements that explain the model's prediction the best. Extensive evaluations on various benchmarks show that Grad-SAM obtains significant improvements over state-of-the-art alternatives.
Cold Item Integration in Deep Hybrid Recommenders via Tunable Stochastic Gates
Dec 12, 2021
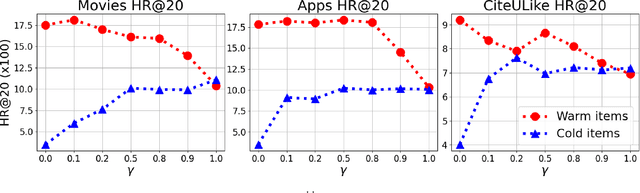
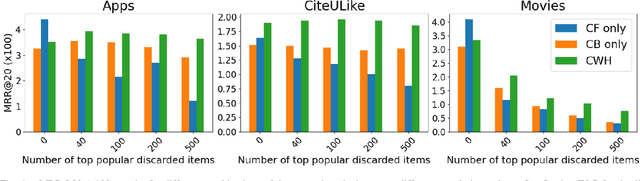
A major challenge in collaborative filtering methods is how to produce recommendations for cold items (items with no ratings), or integrate cold item into an existing catalog. Over the years, a variety of hybrid recommendation models have been proposed to address this problem by utilizing items' metadata and content along with their ratings or usage patterns. In this work, we wish to revisit the cold start problem in order to draw attention to an overlooked challenge: the ability to integrate and balance between (regular) warm items and completely cold items. In this case, two different challenges arise: (1) preserving high quality performance on warm items, while (2) learning to promote cold items to relevant users. First, we show that these two objectives are in fact conflicting, and the balance between them depends on the business needs and the application at hand. Next, we propose a novel hybrid recommendation algorithm that bridges these two conflicting objectives and enables a harmonized balance between preserving high accuracy for warm items while effectively promoting completely cold items. We demonstrate the effectiveness of the proposed algorithm on movies, apps, and articles recommendations, and provide an empirical analysis of the cold-warm trade-off.
Single Independent Component Recovery and Applications
Oct 12, 2021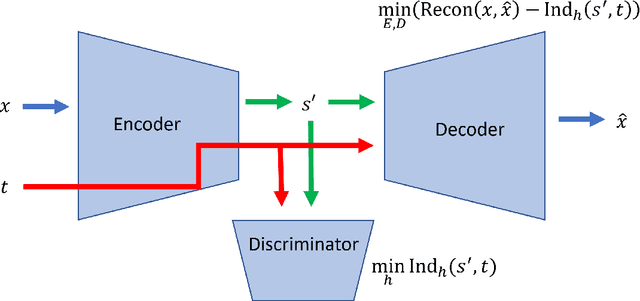
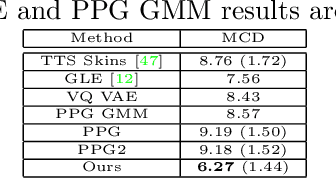
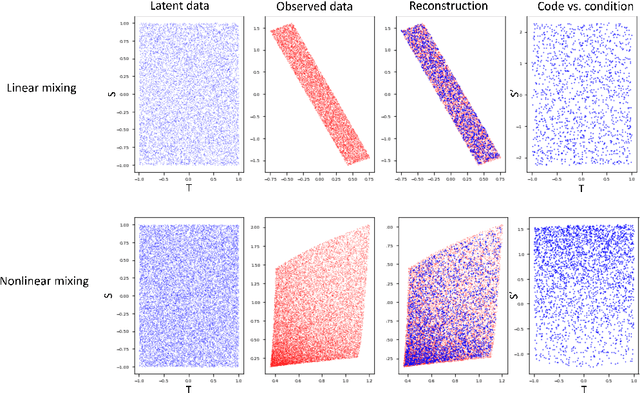
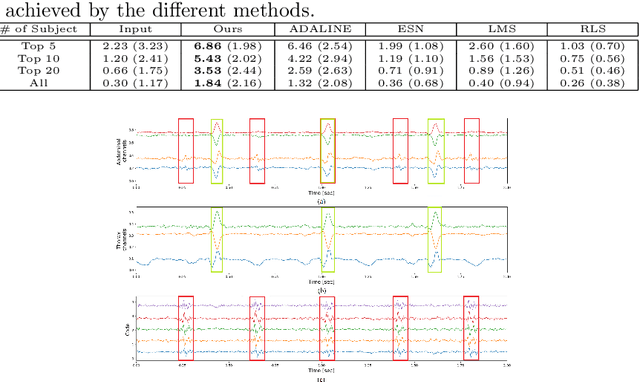
Latent variable discovery is a central problem in data analysis with a broad range of applications in applied science. In this work, we consider data given as an invertible mixture of two statistically independent components, and assume that one of the components is observed while the other is hidden. Our goal is to recover the hidden component. For this purpose, we propose an autoencoder equipped with a discriminator. Unlike the standard nonlinear ICA problem, which was shown to be non-identifiable, in the special case of ICA we consider here, we show that our approach can recover the component of interest up to entropy-preserving transformation. We demonstrate the performance of the proposed approach on several datasets, including image synthesis, voice cloning, and fetal ECG extraction.
GAM: Explainable Visual Similarity and Classification via Gradient Activation Maps
Sep 02, 2021

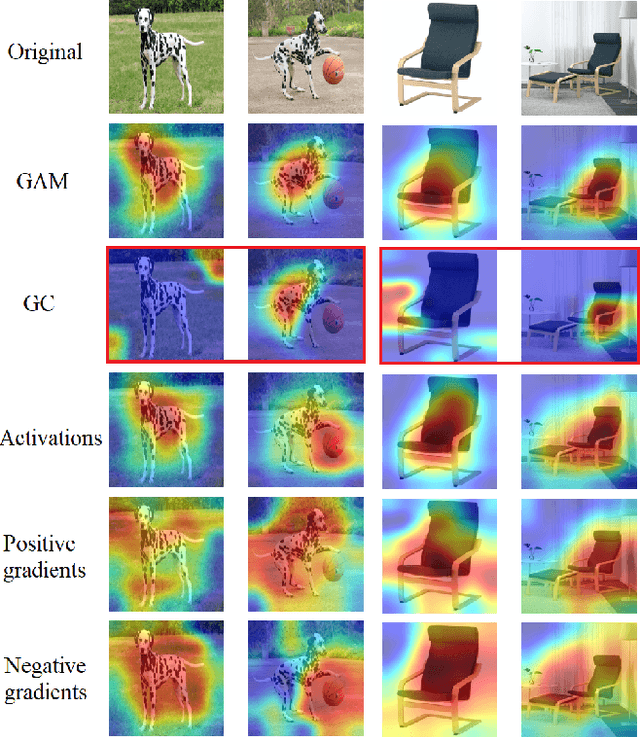

We present Gradient Activation Maps (GAM) - a machinery for explaining predictions made by visual similarity and classification models. By gleaning localized gradient and activation information from multiple network layers, GAM offers improved visual explanations, when compared to existing alternatives. The algorithmic advantages of GAM are explained in detail, and validated empirically, where it is shown that GAM outperforms its alternatives across various tasks and datasets.
Pixel-reassignment in Ultrasound Imaging
Jun 15, 2021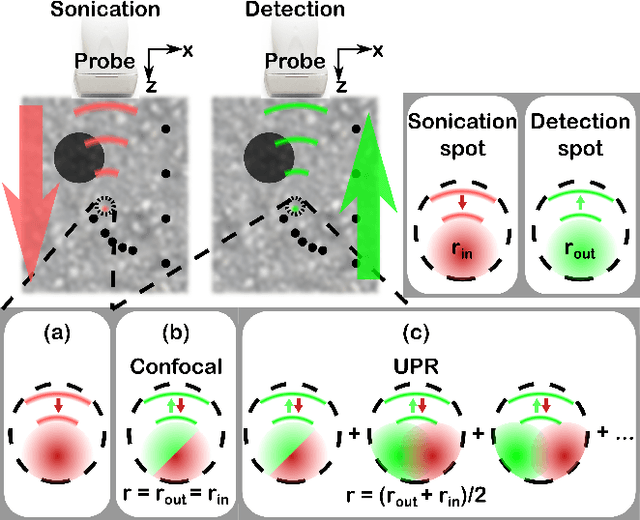
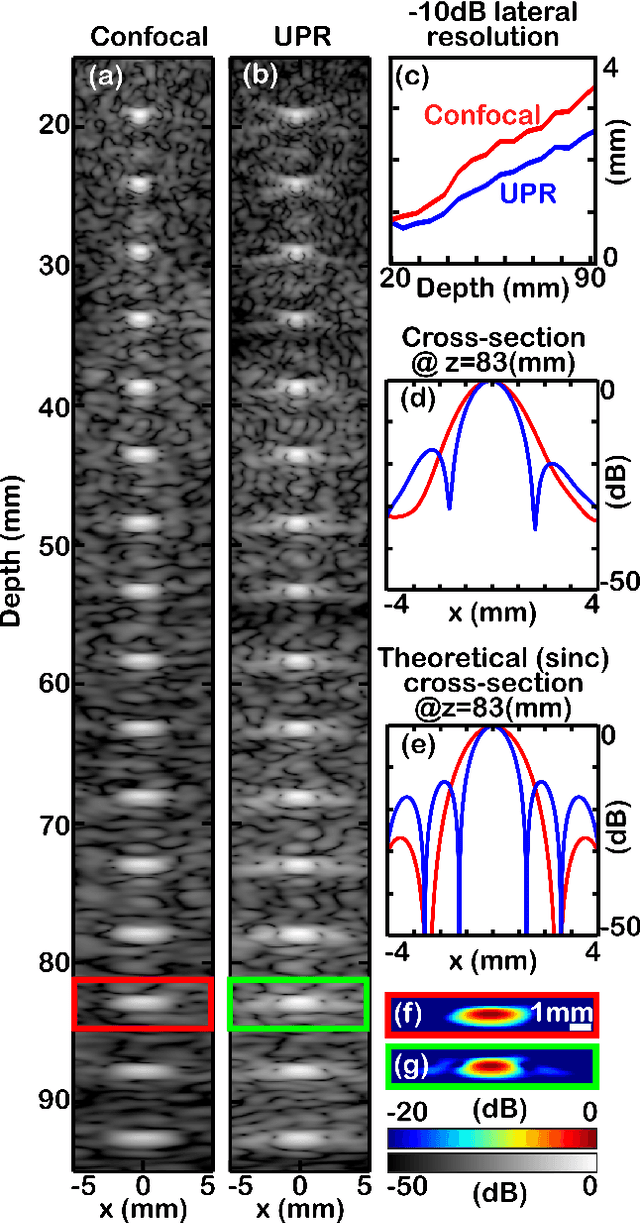
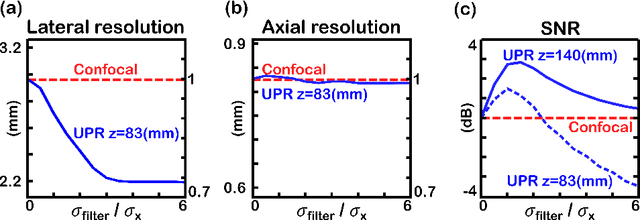

We present an adaptation of the pixel-reassignment technique from confocal fluorescent microscopy to coherent ultrasound imaging. The method, Ultrasound Pixel-Reassignment (UPR), provides a resolution and signal to noise (SNR) improvement in ultrasound imaging by computationally reassigning off-focus signals acquired using traditional plane-wave compounding ultrasonography. We theoretically analyze the analogy between the optical and ultrasound implementations of pixel reassignment, and experimentally evaluate the imaging quality on tissue-mimicking acoustic phantoms. We demonstrate that UPR provides a $25\%$ resolution improvement and a $3dB$ SNR improvement in in-vitro scans, without any change in hardware or acquisition scheme.