 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePtychographic lensless coherent endomicroscopy through a flexible fiber bundle
Jan 31, 2024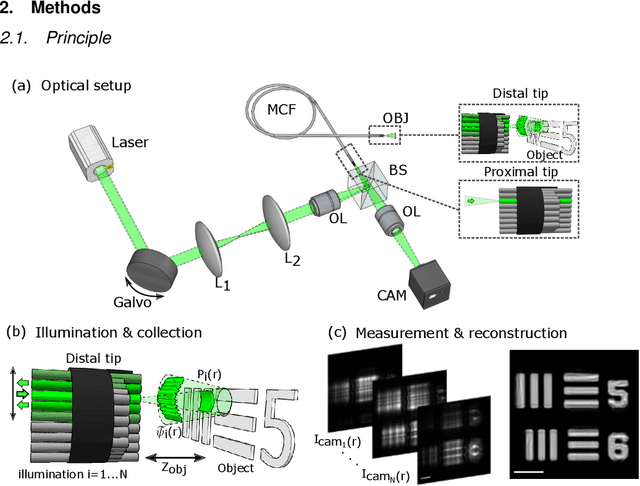

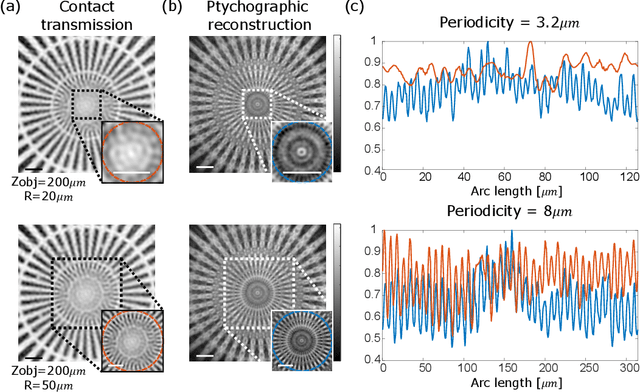

Conventional fiber-bundle-based endoscopes allow minimally invasive imaging through flexible multi-core fiber (MCF) bundles by placing a miniature lens at the distal tip and using each core as an imaging pixel. In recent years, lensless imaging through MCFs was made possible by correcting the core-to-core phase distortions pre-measured in a calibration procedure. However, temporally varying wavefront distortions, for instance, due to dynamic fiber bending, pose a challenge for such approaches. Here, we demonstrate a coherent lensless imaging technique based on intensity-only measurements insensitive to core-to-core phase distortions. We leverage a ptychographic reconstruction algorithm to retrieve the phase and amplitude profiles of reflective objects placed at a distance from the fiber tip, using as input a set of diffracted intensity patterns reflected from the object when the illumination is scanned over the MCF cores. Our approach thus utilizes an acquisition process equivalent to confocal microendoscopy, only replacing the single detector with a camera.
K-space interpretation of image-scanning-microscopy
Jan 11, 2023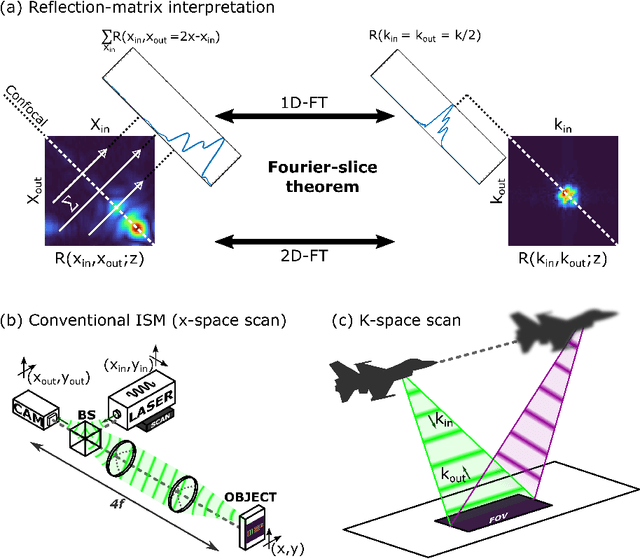
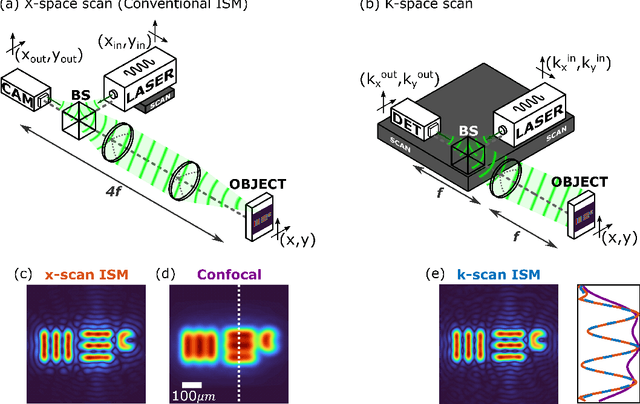
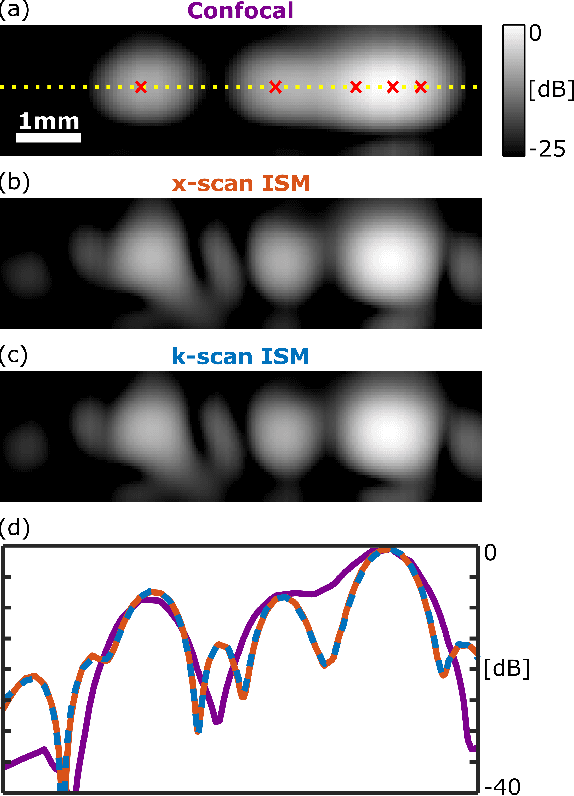
In recent years, image-scanning microscopy (ISM, also termed pixel-reassignment microscopy) has emerged as a technique that improves the resolution and signal-to-noise compared to confocal and widefield microscopy by employing a detector array at the image plane of a confocal laser scanning microscope. Here, we present a k-space analysis of coherent ISM, showing that ISM is equivalent to spotlight synthetic-aperture radar (SAR) and analogous to oblique-illumination microscopy. This insight indicates that ISM can be performed with a single detector placed in the k-space of the sample, which we numerically demonstrate.
Say What? Collaborative Pop Lyric Generation Using Multitask Transfer Learning
Nov 15, 2021
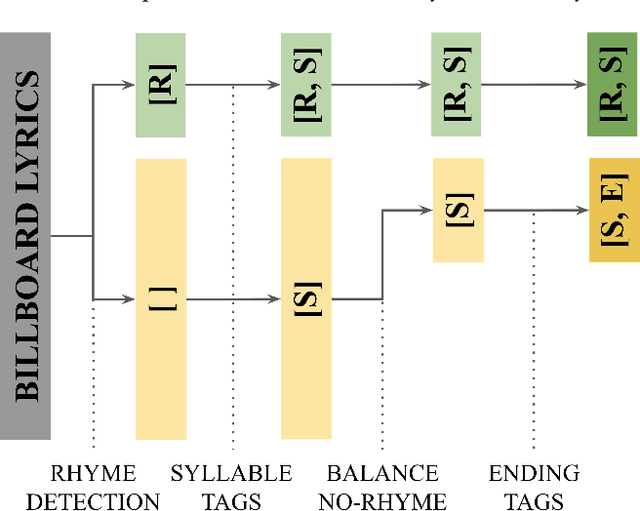

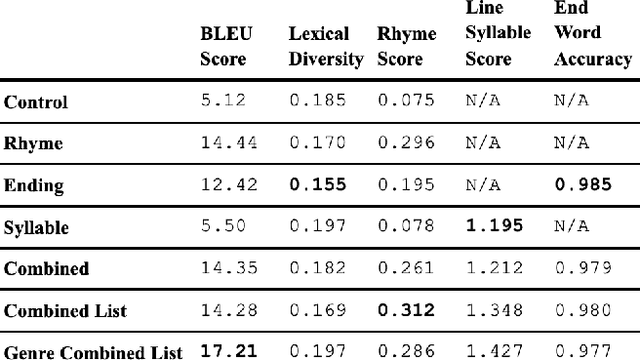
Lyric generation is a popular sub-field of natural language generation that has seen growth in recent years. Pop lyrics are of unique interest due to the genre's unique style and content, in addition to the high level of collaboration that goes on behind the scenes in the professional pop songwriting process. In this paper, we present a collaborative line-level lyric generation system that utilizes transfer-learning via the T5 transformer model, which, till date, has not been used to generate pop lyrics. By working and communicating directly with professional songwriters, we develop a model that is able to learn lyrical and stylistic tasks like rhyming, matching line beat requirements, and ending lines with specific target words. Our approach compares favorably to existing methods for multiple datasets and yields positive results from our online studies and interviews with industry songwriters.
* HAI '21: Proceedings of the 9th International Conference on Human-Agent Interaction
Musical Prosody-Driven Emotion Classification: Interpreting Vocalists Portrayal of Emotions Through Machine Learning
Jun 13, 2021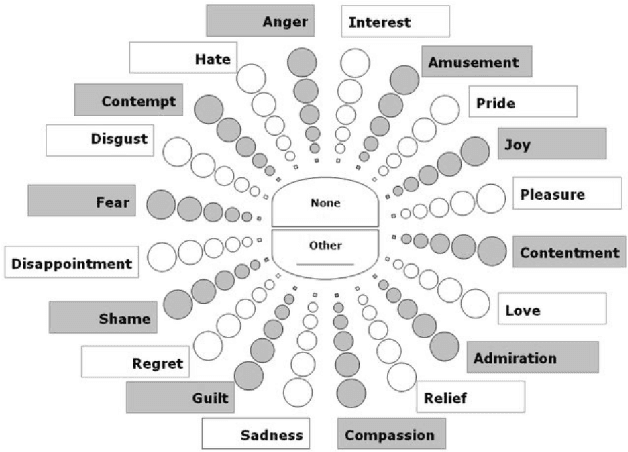
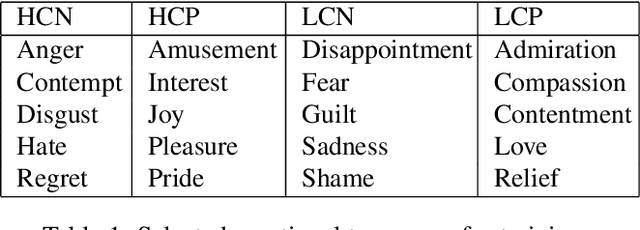
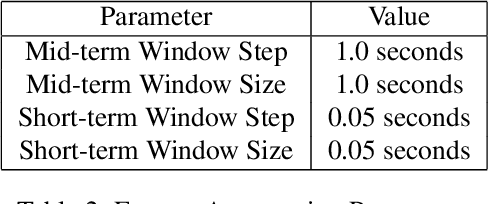
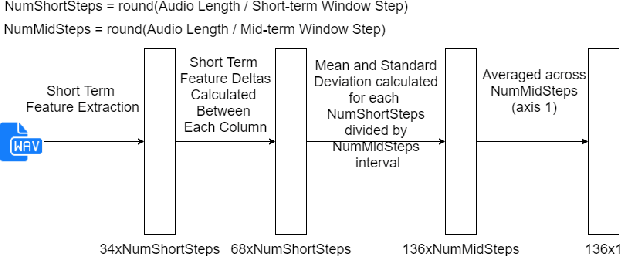
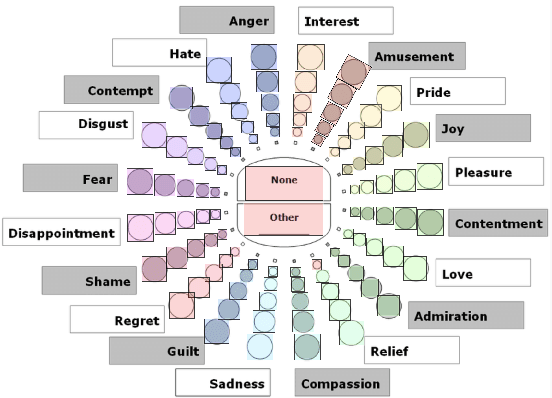
The task of classifying emotions within a musical track has received widespread attention within the Music Information Retrieval (MIR) community. Music emotion recognition has traditionally relied on the use of acoustic features, verbal features, and metadata-based filtering. The role of musical prosody remains under-explored despite several studies demonstrating a strong connection between prosody and emotion. In this study, we restrict the input of traditional machine learning algorithms to the features of musical prosody. Furthermore, our proposed approach builds upon the prior by classifying emotions under an expanded emotional taxonomy, using the Geneva Wheel of Emotion. We utilize a methodology for individual data collection from vocalists, and personal ground truth labeling by the artist themselves. We found that traditional machine learning algorithms when limited to the features of musical prosody (1) achieve high accuracies for a single singer, (2) maintain high accuracy when the dataset is expanded to multiple singers, and (3) achieve high accuracies when trained on a reduced subset of the total features.
Emotional Musical Prosody: Validated Vocal Dataset for Human Robot Interaction
Oct 09, 2020
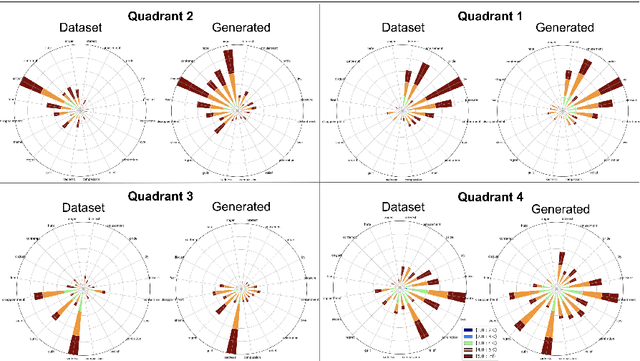
Human collaboration with robotics is dependant on the development of a relationship between human and robot, without which performance and utilization can decrease. Emotion and personality conveyance has been shown to enhance robotic collaborations, with improved human-robot relationships and increased trust. One under-explored way for an artificial agent to convey emotions is through non-linguistic musical prosody. In this work we present a new 4.2 hour dataset of improvised emotional vocal phrases based on the Geneva Emotion Wheel. This dataset has been validated through extensive listening tests and shows promising preliminary results for use in generative systems.
Shimon the Rapper: A Real-Time System for Human-Robot Interactive Rap Battles
Sep 19, 2020
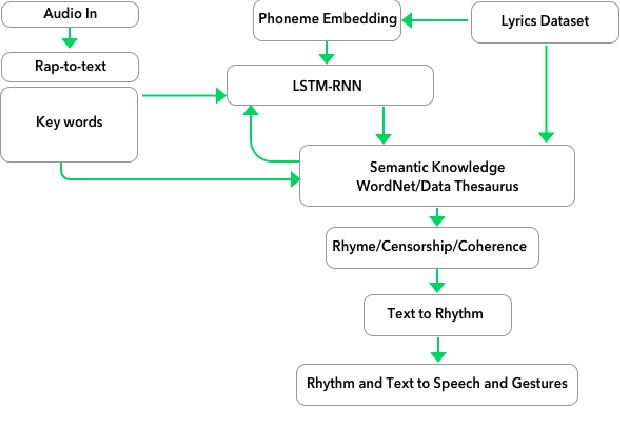
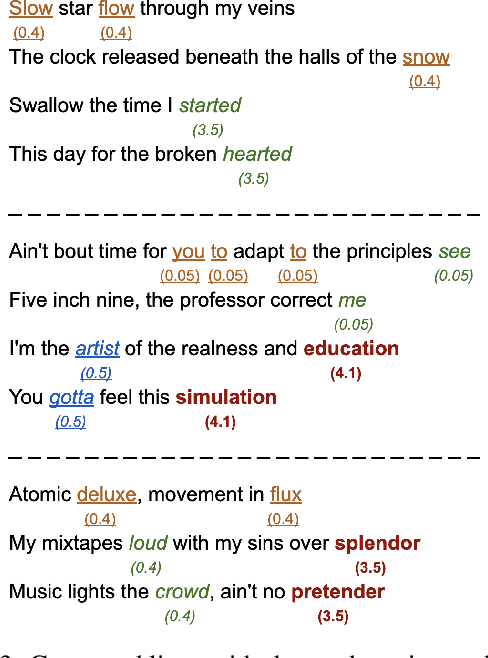

We present a system for real-time lyrical improvisation between a human and a robot in the style of hip hop. Our system takes vocal input from a human rapper, analyzes the semantic meaning, and generates a response that is rapped back by a robot over a musical groove. Previous work with real-time interactive music systems has largely focused on instrumental output, and vocal interactions with robots have been explored, but not in a musical context. Our generative system includes custom methods for censorship, voice, rhythm, rhyming and a novel deep learning pipeline based on phoneme embeddings. The rap performances are accompanied by synchronized robotic gestures and mouth movements. Key technical challenges that were overcome in the system are developing rhymes, performing with low-latency and dataset censorship. We evaluated several aspects of the system through a survey of videos and sample text output. Analysis of comments showed that the overall perception of the system was positive. The model trained on our hip hop dataset was rated significantly higher than our metal dataset in coherence, rhyme quality, and enjoyment. Participants preferred outputs generated by a given input phrase over outputs generated from unknown keywords, indicating that the system successfully relates its output to its input.
Emotional Musical Prosody for the Enhancement of Trust in Robotic Arm Communication
Sep 18, 2020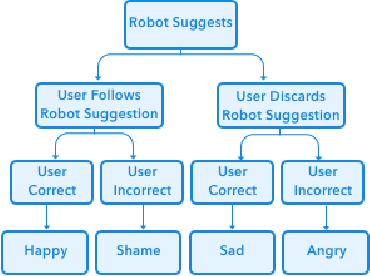

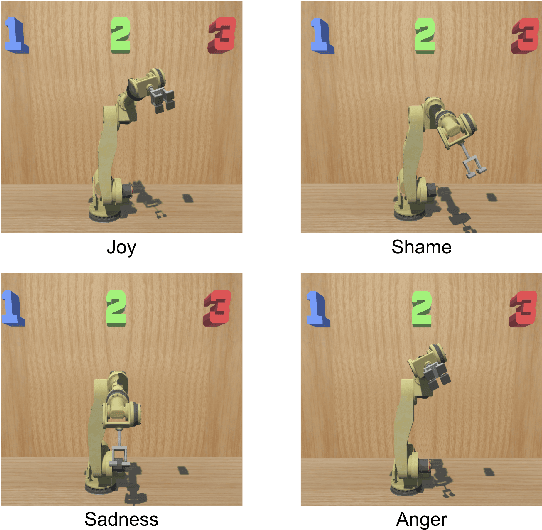
As robotic arms become prevalent in industry it is crucial to improve levels of trust from human collaborators. Low levels of trust in human-robot interaction can reduce overall performance and prevent full robot utilization. We investigated the potential benefits of using emotional musical prosody to allow the robot to respond emotionally to the user's actions. We tested participants' responses to interacting with a virtual robot arm that acted as a decision agent, helping participants select the next number in a sequence. We compared results from three versions of the application in a between-group experiment, where the robot had different emotional reactions to the user's input depending on whether the user agreed with the robot and whether the user's choice was correct. In all versions, the robot reacted with emotional gestures. One version used prosody-based emotional audio phrases selected from our dataset of singer improvisations, the second version used audio consisting of a single pitch randomly assigned to each emotion, and the final version used no audio, only gestures. Our results showed no significant difference for the percentage of times users from each group agreed with the robot, and no difference between user's agreement with the robot after it made a mistake. However, participants also took a trust survey following the interaction, and we found that the reported trust ratings of the musical prosody group were significantly higher than both the single-pitch and no audio groups.
Mechatronics-Driven Musical Expressivity for Robotic Percussionists
Jul 29, 2020


Musical expressivity is an important aspect of musical performance for humans as well as robotic musicians. We present a novel mechatronics-driven implementation of Brushless Direct Current (BLDC) motors in a robotic marimba player, named Shimon, designed to improve speed, dynamic range (loudness), and ultimately perceived musical expressivity in comparison to state-of-the-art robotic percussionist actuators. In an objective test of dynamic range, we find that our implementation provides wider and more consistent dynamic range response in comparison with solenoid-based robotic percussionists. Our implementation also outperforms both solenoid and human marimba players in striking speed. In a subjective listening test measuring musical expressivity, our system performs significantly better than a solenoid-based system and is statistically indistinguishable from human performers.
A Survey of Robotics and Emotion: Classifications and Models of Emotional Interaction
Jul 29, 2020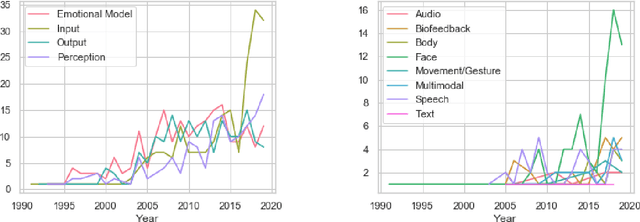
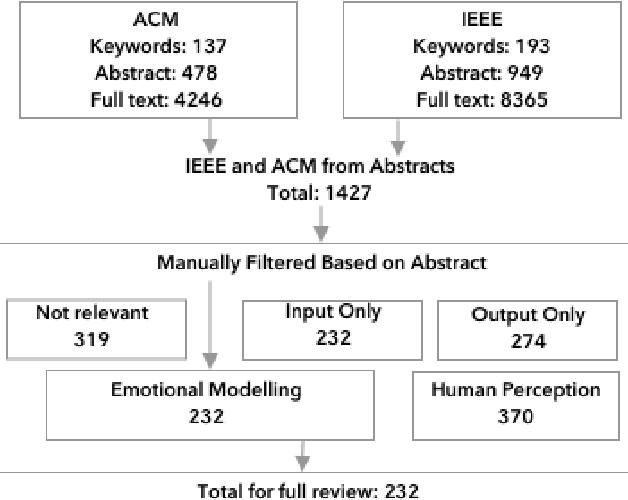
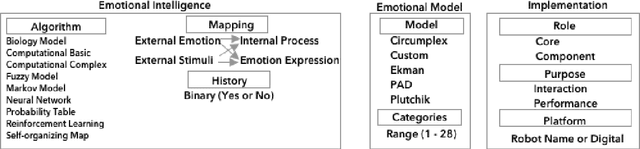
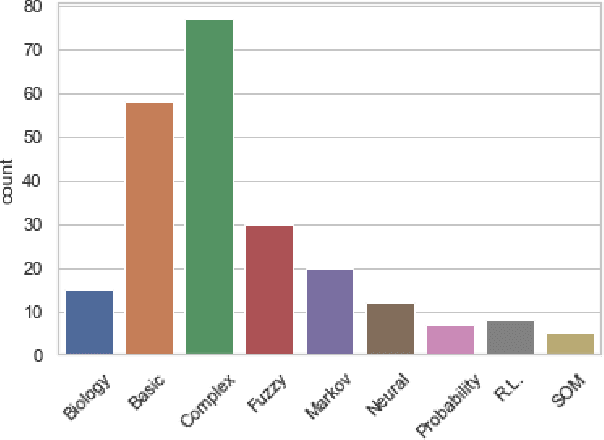
As emotion plays a growing role in robotic research it is crucial to develop methods to analyze and compare among the wide range of approaches. To this end we present a survey of 1427 IEEE and ACM publications that include robotics and emotion. This includes broad categorizations of trends in emotion input analysis, robot emotional expression, studies of emotional interaction and models for internal processing. We then focus on 232 papers that present internal processing of emotion, such as using a human's emotion for better interaction or turning environmental stimuli into an emotional drive for robotic path planning. We conducted constant comparison analysis of the 232 papers and arrived at three broad categorization metrics; emotional intelligence, emotional model and implementation, each including two or three subcategories. The subcategories address the algorithm used, emotional mapping, history, the emotional model, emotional categories, the role of emotion, the purpose of emotion and the platform. Our results show a diverse field of study, largely divided by the role of emotion in the system, either for improved interaction, or improved robotic performance. We also present multiple future opportunities for research and describe intrinsic challenges common in all publications.
Establishing Human-Robot Trust through Music-Driven Robotic Emotion Prosody and Gesture
Jan 11, 2020
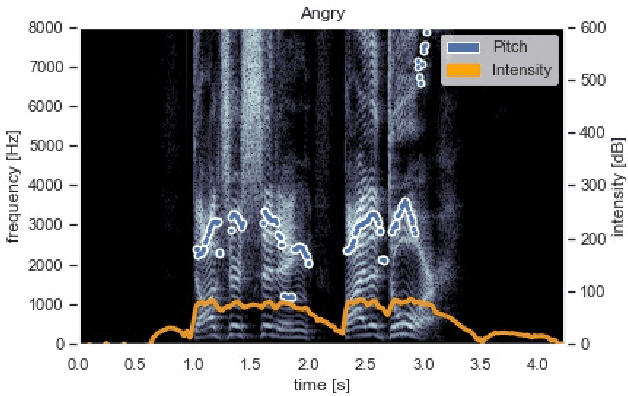
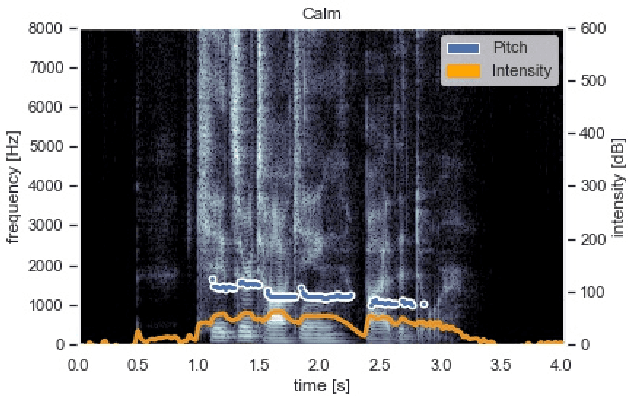
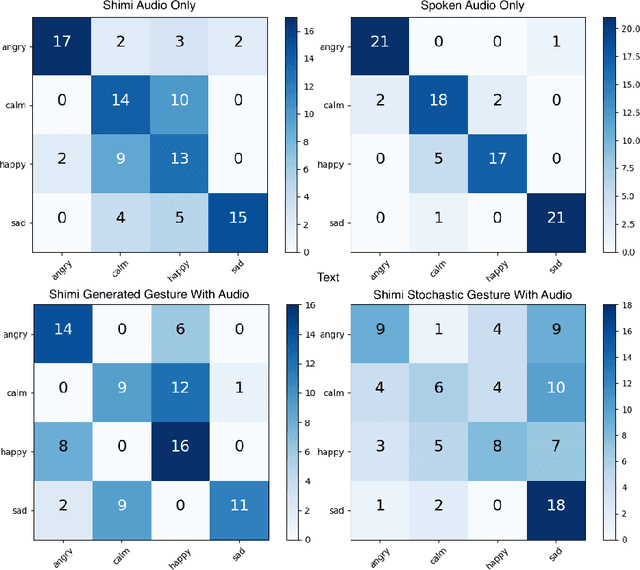
As human-robot collaboration opportunities continue to expand, trust becomes ever more important for full engagement and utilization of robots. Affective trust, built on emotional relationship and interpersonal bonds is particularly critical as it is more resilient to mistakes and increases the willingness to collaborate. In this paper we present a novel model built on music-driven emotional prosody and gestures that encourages the perception of a robotic identity, designed to avoid uncanny valley. Symbolic musical phrases were generated and tagged with emotional information by human musicians. These phrases controlled a synthesis engine playing back pre-rendered audio samples generated through interpolation of phonemes and electronic instruments. Gestures were also driven by the symbolic phrases, encoding the emotion from the musical phrase to low degree-of-freedom movements. Through a user study we showed that our system was able to accurately portray a range of emotions to the user. We also showed with a significant result that our non-linguistic audio generation achieved an 8% higher mean of average trust than using a state-of-the-art text-to-speech system.