 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighly Generalizable Models for Multilingual Hate Speech Detection
Jan 27, 2022Hate speech detection has become an important research topic within the past decade. More private corporations are needing to regulate user generated content on different platforms across the globe. In this paper, we introduce a study of multilingual hate speech classification. We compile a dataset of 11 languages and resolve different taxonomies by analyzing the combined data with binary labels: hate speech or not hate speech. Defining hate speech in a single way across different languages and datasets may erase cultural nuances to the definition, therefore, we utilize language agnostic embeddings provided by LASER and MUSE in order to develop models that can use a generalized definition of hate speech across datasets. Furthermore, we evaluate prior state of the art methodologies for hate speech detection under our expanded dataset. We conduct three types of experiments for a binary hate speech classification task: Multilingual-Train Monolingual-Test, MonolingualTrain Monolingual-Test and Language-Family-Train Monolingual Test scenarios to see if performance increases for each language due to learning more from other language data.
Musical Prosody-Driven Emotion Classification: Interpreting Vocalists Portrayal of Emotions Through Machine Learning
Jun 13, 2021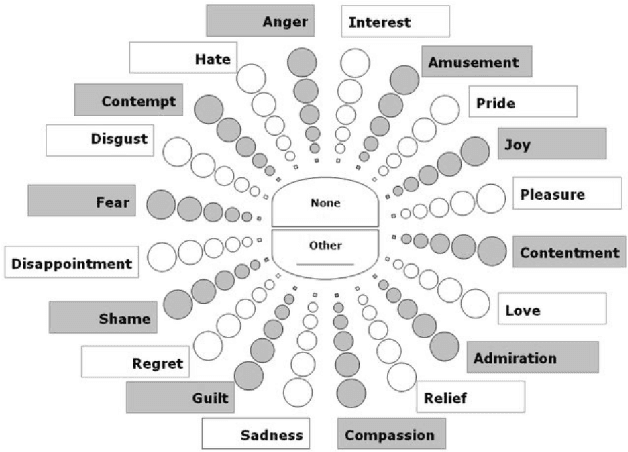
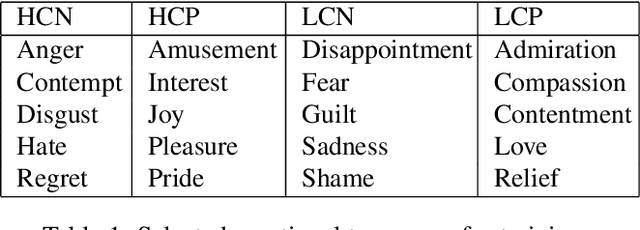
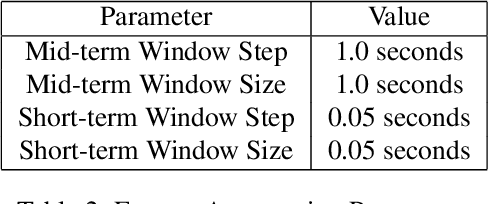
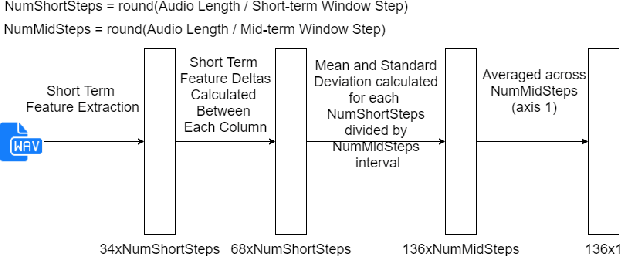
The task of classifying emotions within a musical track has received widespread attention within the Music Information Retrieval (MIR) community. Music emotion recognition has traditionally relied on the use of acoustic features, verbal features, and metadata-based filtering. The role of musical prosody remains under-explored despite several studies demonstrating a strong connection between prosody and emotion. In this study, we restrict the input of traditional machine learning algorithms to the features of musical prosody. Furthermore, our proposed approach builds upon the prior by classifying emotions under an expanded emotional taxonomy, using the Geneva Wheel of Emotion. We utilize a methodology for individual data collection from vocalists, and personal ground truth labeling by the artist themselves. We found that traditional machine learning algorithms when limited to the features of musical prosody (1) achieve high accuracies for a single singer, (2) maintain high accuracy when the dataset is expanded to multiple singers, and (3) achieve high accuracies when trained on a reduced subset of the total features.