 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighly Generalizable Models for Multilingual Hate Speech Detection
Jan 27, 2022Hate speech detection has become an important research topic within the past decade. More private corporations are needing to regulate user generated content on different platforms across the globe. In this paper, we introduce a study of multilingual hate speech classification. We compile a dataset of 11 languages and resolve different taxonomies by analyzing the combined data with binary labels: hate speech or not hate speech. Defining hate speech in a single way across different languages and datasets may erase cultural nuances to the definition, therefore, we utilize language agnostic embeddings provided by LASER and MUSE in order to develop models that can use a generalized definition of hate speech across datasets. Furthermore, we evaluate prior state of the art methodologies for hate speech detection under our expanded dataset. We conduct three types of experiments for a binary hate speech classification task: Multilingual-Train Monolingual-Test, MonolingualTrain Monolingual-Test and Language-Family-Train Monolingual Test scenarios to see if performance increases for each language due to learning more from other language data.
Efficient Incorporation of Multiple Latency Targets in the Once-For-All Network
Dec 12, 2020
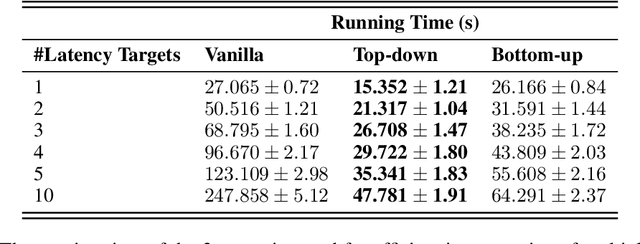
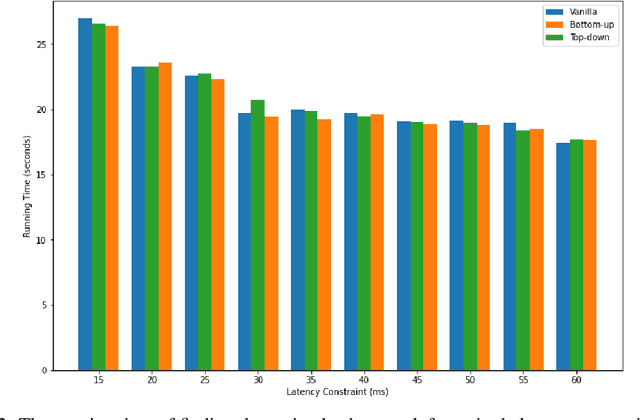
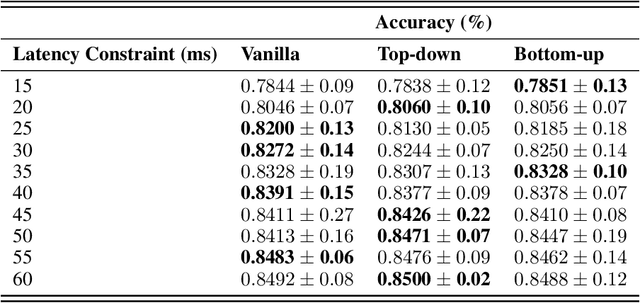
Neural Architecture Search has proven an effective method of automating architecture engineering. Recent work in the field has been to look for architectures subject to multiple objectives such as accuracy and latency to efficiently deploy them on different target hardware. Once-for-All (OFA) is one such method that decouples training and search and is able to find high-performance networks for different latency constraints. However, the search phase is inefficient at incorporating multiple latency targets. In this paper, we introduce two strategies (Top-down and Bottom-up) that use warm starting and randomized network pruning for the efficient incorporation of multiple latency targets in the OFA network. We evaluate these strategies against the current OFA implementation and demonstrate that our strategies offer significant running time performance gains while not sacrificing the accuracy of the subnetworks that were found for each latency target. We further demonstrate that these performance gains are generalized to every design space used by the OFA network.