 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Incorporation of Multiple Latency Targets in the Once-For-All Network
Paper and Code

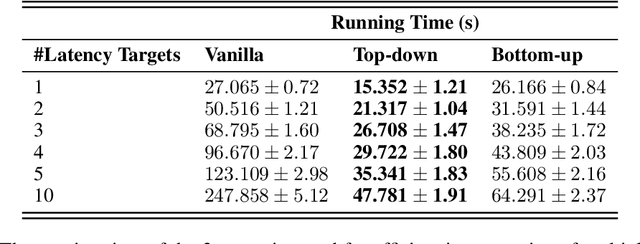
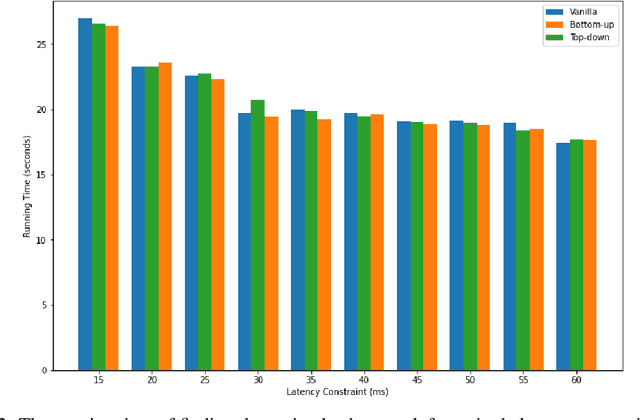
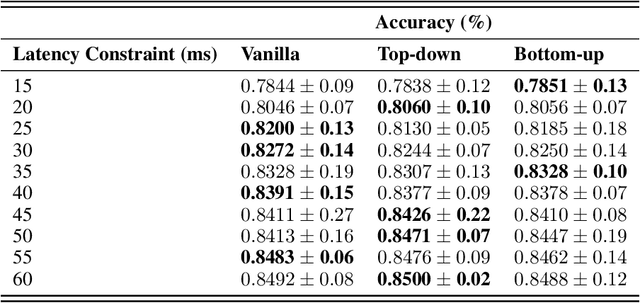
Neural Architecture Search has proven an effective method of automating architecture engineering. Recent work in the field has been to look for architectures subject to multiple objectives such as accuracy and latency to efficiently deploy them on different target hardware. Once-for-All (OFA) is one such method that decouples training and search and is able to find high-performance networks for different latency constraints. However, the search phase is inefficient at incorporating multiple latency targets. In this paper, we introduce two strategies (Top-down and Bottom-up) that use warm starting and randomized network pruning for the efficient incorporation of multiple latency targets in the OFA network. We evaluate these strategies against the current OFA implementation and demonstrate that our strategies offer significant running time performance gains while not sacrificing the accuracy of the subnetworks that were found for each latency target. We further demonstrate that these performance gains are generalized to every design space used by the OFA network.