 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShimon the Rapper: A Real-Time System for Human-Robot Interactive Rap Battles
Paper and Code

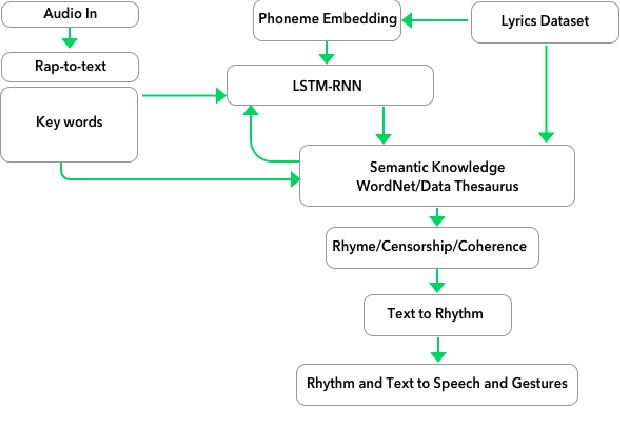
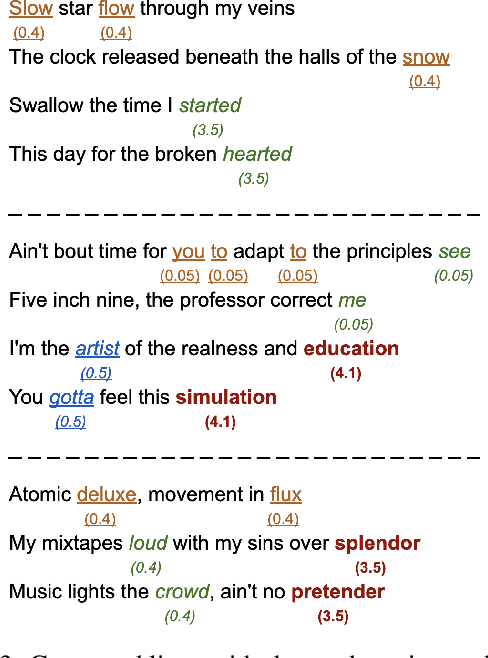

We present a system for real-time lyrical improvisation between a human and a robot in the style of hip hop. Our system takes vocal input from a human rapper, analyzes the semantic meaning, and generates a response that is rapped back by a robot over a musical groove. Previous work with real-time interactive music systems has largely focused on instrumental output, and vocal interactions with robots have been explored, but not in a musical context. Our generative system includes custom methods for censorship, voice, rhythm, rhyming and a novel deep learning pipeline based on phoneme embeddings. The rap performances are accompanied by synchronized robotic gestures and mouth movements. Key technical challenges that were overcome in the system are developing rhymes, performing with low-latency and dataset censorship. We evaluated several aspects of the system through a survey of videos and sample text output. Analysis of comments showed that the overall perception of the system was positive. The model trained on our hip hop dataset was rated significantly higher than our metal dataset in coherence, rhyme quality, and enjoyment. Participants preferred outputs generated by a given input phrase over outputs generated from unknown keywords, indicating that the system successfully relates its output to its input.