 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing Human-Robot Trust through Music-Driven Robotic Emotion Prosody and Gesture
Jan 11, 2020
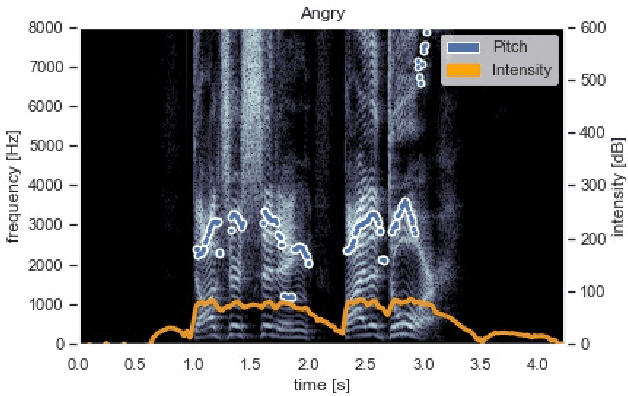
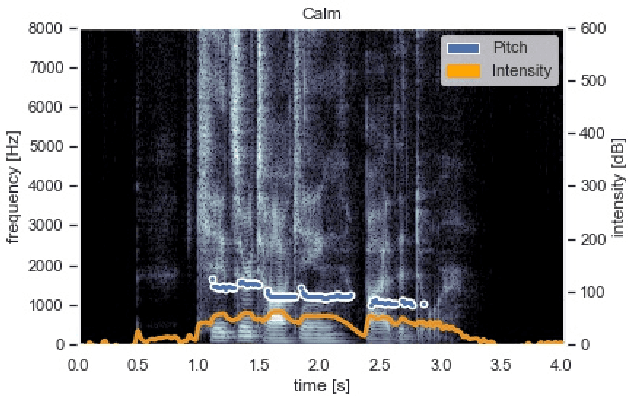
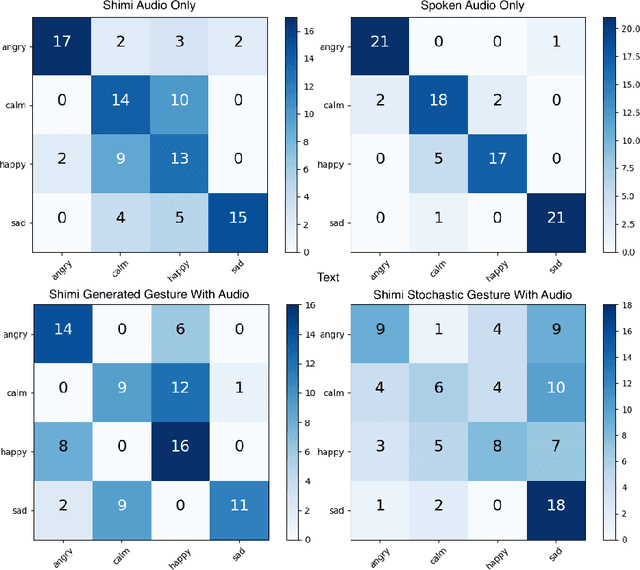
As human-robot collaboration opportunities continue to expand, trust becomes ever more important for full engagement and utilization of robots. Affective trust, built on emotional relationship and interpersonal bonds is particularly critical as it is more resilient to mistakes and increases the willingness to collaborate. In this paper we present a novel model built on music-driven emotional prosody and gestures that encourages the perception of a robotic identity, designed to avoid uncanny valley. Symbolic musical phrases were generated and tagged with emotional information by human musicians. These phrases controlled a synthesis engine playing back pre-rendered audio samples generated through interpolation of phonemes and electronic instruments. Gestures were also driven by the symbolic phrases, encoding the emotion from the musical phrase to low degree-of-freedom movements. Through a user study we showed that our system was able to accurately portray a range of emotions to the user. We also showed with a significant result that our non-linguistic audio generation achieved an 8% higher mean of average trust than using a state-of-the-art text-to-speech system.