 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake-A-Texture: Fast Shape-Aware Texture Generation in 3 Seconds
Dec 10, 2024



We present Make-A-Texture, a new framework that efficiently synthesizes high-resolution texture maps from textual prompts for given 3D geometries. Our approach progressively generates textures that are consistent across multiple viewpoints with a depth-aware inpainting diffusion model, in an optimized sequence of viewpoints determined by an automatic view selection algorithm. A significant feature of our method is its remarkable efficiency, achieving a full texture generation within an end-to-end runtime of just 3.07 seconds on a single NVIDIA H100 GPU, significantly outperforming existing methods. Such an acceleration is achieved by optimizations in the diffusion model and a specialized backprojection method. Moreover, our method reduces the artifacts in the backprojection phase, by selectively masking out non-frontal faces, and internal faces of open-surfaced objects. Experimental results demonstrate that Make-A-Texture matches or exceeds the quality of other state-of-the-art methods. Our work significantly improves the applicability and practicality of texture generation models for real-world 3D content creation, including interactive creation and text-guided texture editing.
Grad-SAM: Explaining Transformers via Gradient Self-Attention Maps
Apr 23, 2022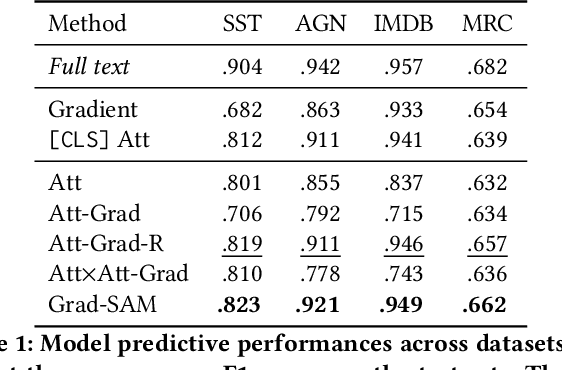
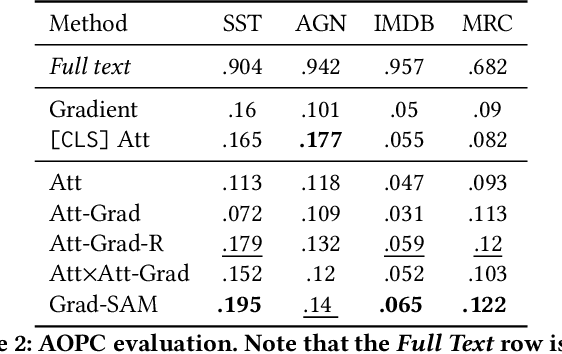

Transformer-based language models significantly advanced the state-of-the-art in many linguistic tasks. As this revolution continues, the ability to explain model predictions has become a major area of interest for the NLP community. In this work, we present Gradient Self-Attention Maps (Grad-SAM) - a novel gradient-based method that analyzes self-attention units and identifies the input elements that explain the model's prediction the best. Extensive evaluations on various benchmarks show that Grad-SAM obtains significant improvements over state-of-the-art alternatives.
GAM: Explainable Visual Similarity and Classification via Gradient Activation Maps
Sep 02, 2021

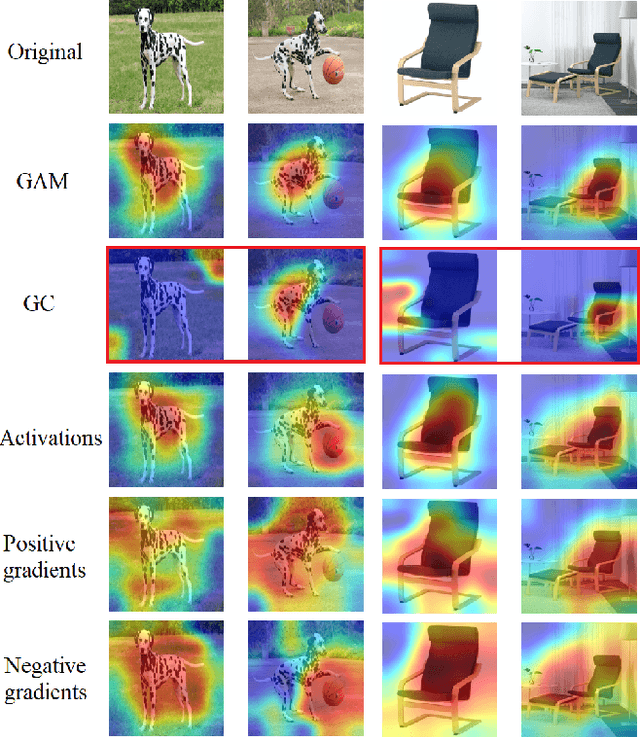

We present Gradient Activation Maps (GAM) - a machinery for explaining predictions made by visual similarity and classification models. By gleaning localized gradient and activation information from multiple network layers, GAM offers improved visual explanations, when compared to existing alternatives. The algorithmic advantages of GAM are explained in detail, and validated empirically, where it is shown that GAM outperforms its alternatives across various tasks and datasets.
Robust Model Compression Using Deep Hypotheses
Mar 13, 2021
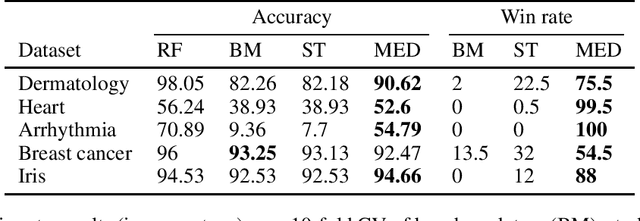
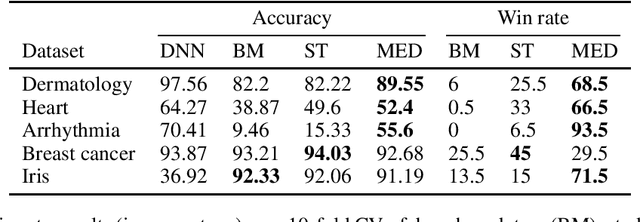
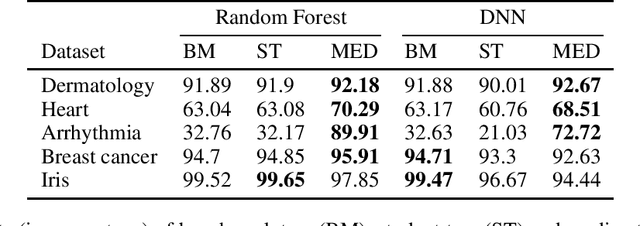
Machine Learning models should ideally be compact and robust. Compactness provides efficiency and comprehensibility whereas robustness provides resilience. Both topics have been studied in recent years but in isolation. Here we present a robust model compression scheme which is independent of model types: it can compress ensembles, neural networks and other types of models into diverse types of small models. The main building block is the notion of depth derived from robust statistics. Originally, depth was introduced as a measure of the centrality of a point in a sample such that the median is the deepest point. This concept was extended to classification functions which makes it possible to define the depth of a hypothesis and the median hypothesis. Algorithms have been suggested to approximate the median but they have been limited to binary classification. In this study, we present a new algorithm, the Multiclass Empirical Median Optimization (MEMO) algorithm that finds a deep hypothesis in multi-class tasks, and prove its correctness. This leads to our Compact Robust Estimated Median Belief Optimization (CREMBO) algorithm for robust model compression. We demonstrate the success of this algorithm empirically by compressing neural networks and random forests into small decision trees, which are interpretable models, and show that they are more accurate and robust than other comparable methods. In addition, our empirical study shows that our method outperforms Knowledge Distillation on DNN to DNN compression.