 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake-A-Texture: Fast Shape-Aware Texture Generation in 3 Seconds
Dec 10, 2024



We present Make-A-Texture, a new framework that efficiently synthesizes high-resolution texture maps from textual prompts for given 3D geometries. Our approach progressively generates textures that are consistent across multiple viewpoints with a depth-aware inpainting diffusion model, in an optimized sequence of viewpoints determined by an automatic view selection algorithm. A significant feature of our method is its remarkable efficiency, achieving a full texture generation within an end-to-end runtime of just 3.07 seconds on a single NVIDIA H100 GPU, significantly outperforming existing methods. Such an acceleration is achieved by optimizations in the diffusion model and a specialized backprojection method. Moreover, our method reduces the artifacts in the backprojection phase, by selectively masking out non-frontal faces, and internal faces of open-surfaced objects. Experimental results demonstrate that Make-A-Texture matches or exceeds the quality of other state-of-the-art methods. Our work significantly improves the applicability and practicality of texture generation models for real-world 3D content creation, including interactive creation and text-guided texture editing.
Human Pose Estimation using Deep Consensus Voting
Mar 27, 2016
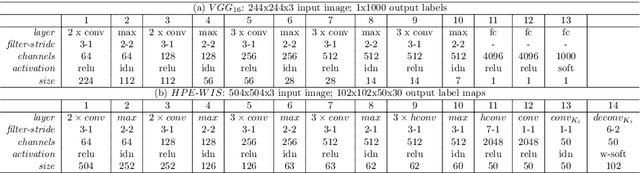

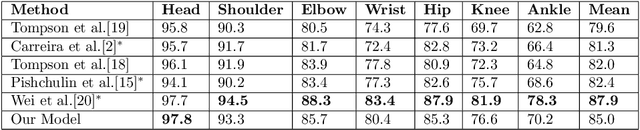
In this paper we consider the problem of human pose estimation from a single still image. We propose a novel approach where each location in the image votes for the position of each keypoint using a convolutional neural net. The voting scheme allows us to utilize information from the whole image, rather than rely on a sparse set of keypoint locations. Using dense, multi-target votes, not only produces good keypoint predictions, but also enables us to compute image-dependent joint keypoint probabilities by looking at consensus voting. This differs from most previous methods where joint probabilities are learned from relative keypoint locations and are independent of the image. We finally combine the keypoints votes and joint probabilities in order to identify the optimal pose configuration. We show our competitive performance on the MPII Human Pose and Leeds Sports Pose datasets.