 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake-A-Texture: Fast Shape-Aware Texture Generation in 3 Seconds
Dec 10, 2024



We present Make-A-Texture, a new framework that efficiently synthesizes high-resolution texture maps from textual prompts for given 3D geometries. Our approach progressively generates textures that are consistent across multiple viewpoints with a depth-aware inpainting diffusion model, in an optimized sequence of viewpoints determined by an automatic view selection algorithm. A significant feature of our method is its remarkable efficiency, achieving a full texture generation within an end-to-end runtime of just 3.07 seconds on a single NVIDIA H100 GPU, significantly outperforming existing methods. Such an acceleration is achieved by optimizations in the diffusion model and a specialized backprojection method. Moreover, our method reduces the artifacts in the backprojection phase, by selectively masking out non-frontal faces, and internal faces of open-surfaced objects. Experimental results demonstrate that Make-A-Texture matches or exceeds the quality of other state-of-the-art methods. Our work significantly improves the applicability and practicality of texture generation models for real-world 3D content creation, including interactive creation and text-guided texture editing.
WaSt-3D: Wasserstein-2 Distance for Scene-to-Scene Stylization on 3D Gaussians
Sep 26, 2024



While style transfer techniques have been well-developed for 2D image stylization, the extension of these methods to 3D scenes remains relatively unexplored. Existing approaches demonstrate proficiency in transferring colors and textures but often struggle with replicating the geometry of the scenes. In our work, we leverage an explicit Gaussian Splatting (GS) representation and directly match the distributions of Gaussians between style and content scenes using the Earth Mover's Distance (EMD). By employing the entropy-regularized Wasserstein-2 distance, we ensure that the transformation maintains spatial smoothness. Additionally, we decompose the scene stylization problem into smaller chunks to enhance efficiency. This paradigm shift reframes stylization from a pure generative process driven by latent space losses to an explicit matching of distributions between two Gaussian representations. Our method achieves high-resolution 3D stylization by faithfully transferring details from 3D style scenes onto the content scene. Furthermore, WaSt-3D consistently delivers results across diverse content and style scenes without necessitating any training, as it relies solely on optimization-based techniques. See our project page for additional results and source code: $\href{https://compvis.github.io/wast3d/}{https://compvis.github.io/wast3d/}$.
Garment3DGen: 3D Garment Stylization and Texture Generation
Mar 27, 2024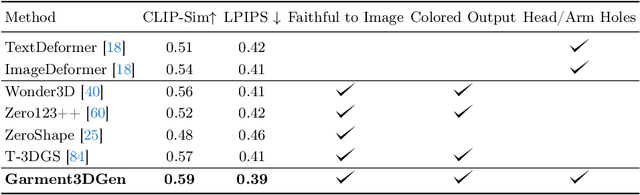
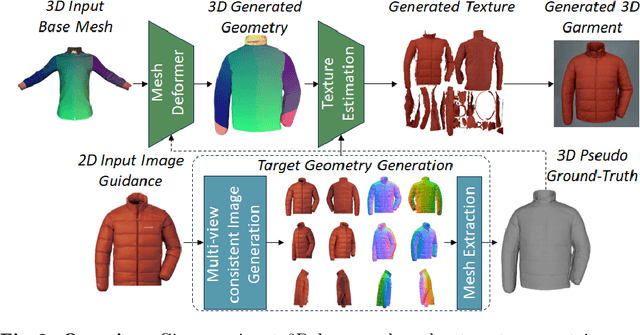


We introduce Garment3DGen a new method to synthesize 3D garment assets from a base mesh given a single input image as guidance. Our proposed approach allows users to generate 3D textured clothes based on both real and synthetic images, such as those generated by text prompts. The generated assets can be directly draped and simulated on human bodies. First, we leverage the recent progress of image to 3D diffusion methods to generate 3D garment geometries. However, since these geometries cannot be utilized directly for downstream tasks, we propose to use them as pseudo ground-truth and set up a mesh deformation optimization procedure that deforms a base template mesh to match the generated 3D target. Second, we introduce carefully designed losses that allow the input base mesh to freely deform towards the desired target, yet preserve mesh quality and topology such that they can be simulated. Finally, a texture estimation module generates high-fidelity texture maps that are globally and locally consistent and faithfully capture the input guidance, allowing us to render the generated 3D assets. With Garment3DGen users can generate the textured 3D garment of their choice without the need of artist intervention. One can provide a textual prompt describing the garment they desire to generate a simulation-ready 3D asset. We present a plethora of quantitative and qualitative comparisons on various assets both real and generated and provide use-cases of how one can generate simulation-ready 3D garments.
SteinDreamer: Variance Reduction for Text-to-3D Score Distillation via Stein Identity
Dec 31, 2023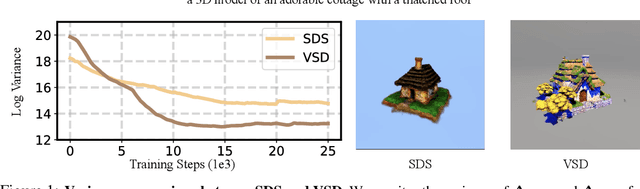
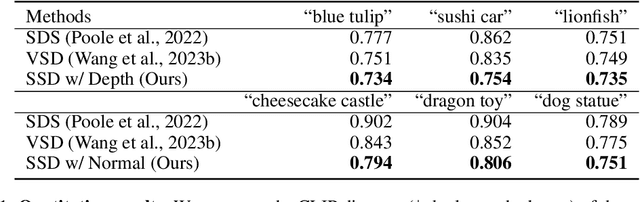
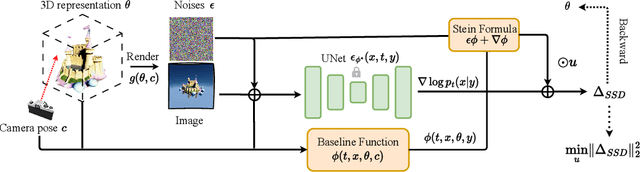
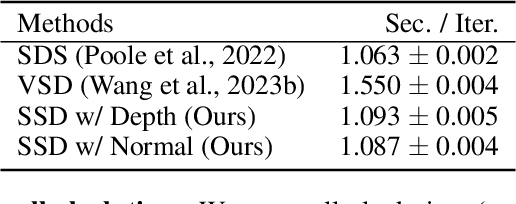
Score distillation has emerged as one of the most prevalent approaches for text-to-3D asset synthesis. Essentially, score distillation updates 3D parameters by lifting and back-propagating scores averaged over different views. In this paper, we reveal that the gradient estimation in score distillation is inherent to high variance. Through the lens of variance reduction, the effectiveness of SDS and VSD can be interpreted as applications of various control variates to the Monte Carlo estimator of the distilled score. Motivated by this rethinking and based on Stein's identity, we propose a more general solution to reduce variance for score distillation, termed Stein Score Distillation (SSD). SSD incorporates control variates constructed by Stein identity, allowing for arbitrary baseline functions. This enables us to include flexible guidance priors and network architectures to explicitly optimize for variance reduction. In our experiments, the overall pipeline, dubbed SteinDreamer, is implemented by instantiating the control variate with a monocular depth estimator. The results suggest that SSD can effectively reduce the distillation variance and consistently improve visual quality for both object- and scene-level generation. Moreover, we demonstrate that SteinDreamer achieves faster convergence than existing methods due to more stable gradient updates.
Taming Mode Collapse in Score Distillation for Text-to-3D Generation
Dec 31, 2023
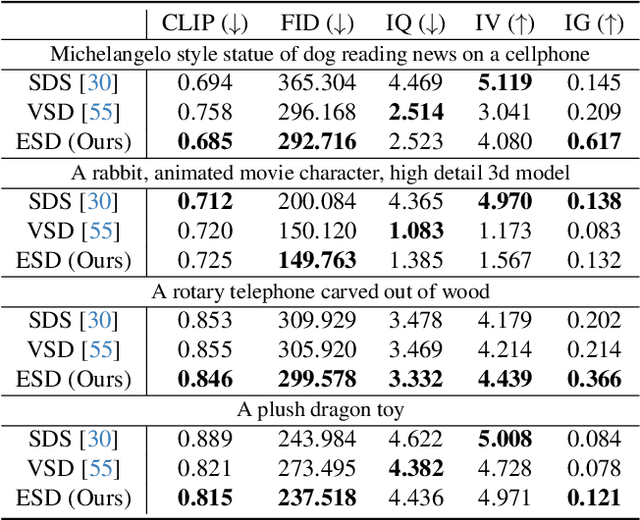
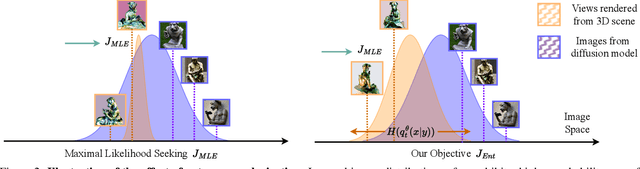
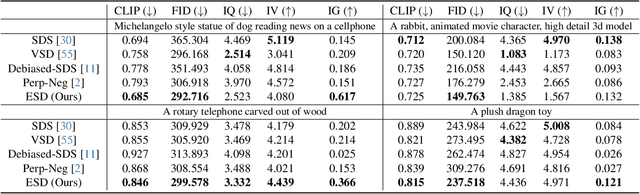
Despite the remarkable performance of score distillation in text-to-3D generation, such techniques notoriously suffer from view inconsistency issues, also known as "Janus" artifact, where the generated objects fake each view with multiple front faces. Although empirically effective methods have approached this problem via score debiasing or prompt engineering, a more rigorous perspective to explain and tackle this problem remains elusive. In this paper, we reveal that the existing score distillation-based text-to-3D generation frameworks degenerate to maximal likelihood seeking on each view independently and thus suffer from the mode collapse problem, manifesting as the Janus artifact in practice. To tame mode collapse, we improve score distillation by re-establishing in entropy term in the corresponding variational objective, which is applied to the distribution of rendered images. Maximizing the entropy encourages diversity among different views in generated 3D assets, thereby mitigating the Janus problem. Based on this new objective, we derive a new update rule for 3D score distillation, dubbed Entropic Score Distillation (ESD). We theoretically reveal that ESD can be simplified and implemented by just adopting the classifier-free guidance trick upon variational score distillation. Although embarrassingly straightforward, our extensive experiments successfully demonstrate that ESD can be an effective treatment for Janus artifacts in score distillation.
MMG-Ego4D: Multi-Modal Generalization in Egocentric Action Recognition
May 12, 2023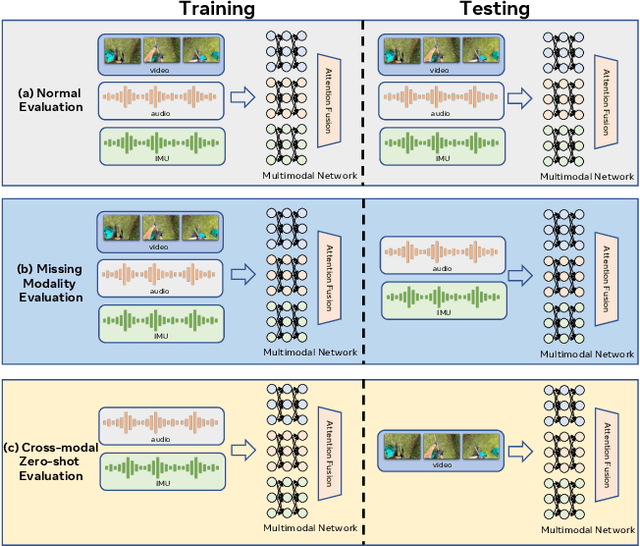

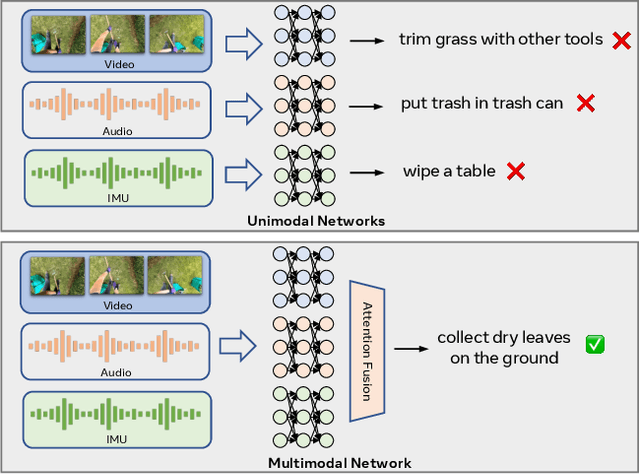
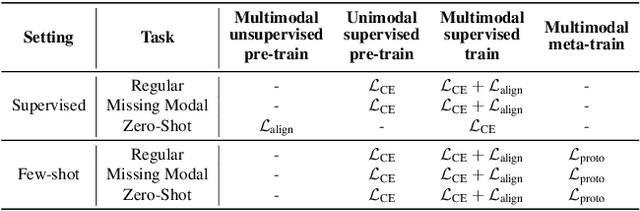
In this paper, we study a novel problem in egocentric action recognition, which we term as "Multimodal Generalization" (MMG). MMG aims to study how systems can generalize when data from certain modalities is limited or even completely missing. We thoroughly investigate MMG in the context of standard supervised action recognition and the more challenging few-shot setting for learning new action categories. MMG consists of two novel scenarios, designed to support security, and efficiency considerations in real-world applications: (1) missing modality generalization where some modalities that were present during the train time are missing during the inference time, and (2) cross-modal zero-shot generalization, where the modalities present during the inference time and the training time are disjoint. To enable this investigation, we construct a new dataset MMG-Ego4D containing data points with video, audio, and inertial motion sensor (IMU) modalities. Our dataset is derived from Ego4D dataset, but processed and thoroughly re-annotated by human experts to facilitate research in the MMG problem. We evaluate a diverse array of models on MMG-Ego4D and propose new methods with improved generalization ability. In particular, we introduce a new fusion module with modality dropout training, contrastive-based alignment training, and a novel cross-modal prototypical loss for better few-shot performance. We hope this study will serve as a benchmark and guide future research in multimodal generalization problems. The benchmark and code will be available at https://github.com/facebookresearch/MMG_Ego4D.
PyTorchVideo: A Deep Learning Library for Video Understanding
Nov 18, 2021
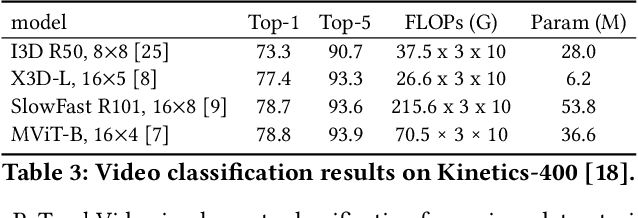

We introduce PyTorchVideo, an open-source deep-learning library that provides a rich set of modular, efficient, and reproducible components for a variety of video understanding tasks, including classification, detection, self-supervised learning, and low-level processing. The library covers a full stack of video understanding tools including multimodal data loading, transformations, and models that reproduce state-of-the-art performance. PyTorchVideo further supports hardware acceleration that enables real-time inference on mobile devices. The library is based on PyTorch and can be used by any training framework; for example, PyTorchLightning, PySlowFast, or Classy Vision. PyTorchVideo is available at https://pytorchvideo.org/
Improving Efficiency in Neural Network Accelerator Using Operands Hamming Distance optimization
Feb 13, 2020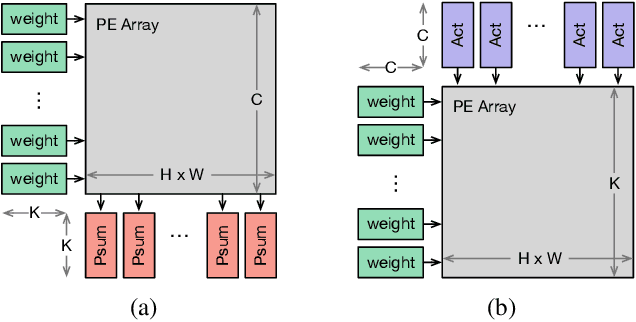

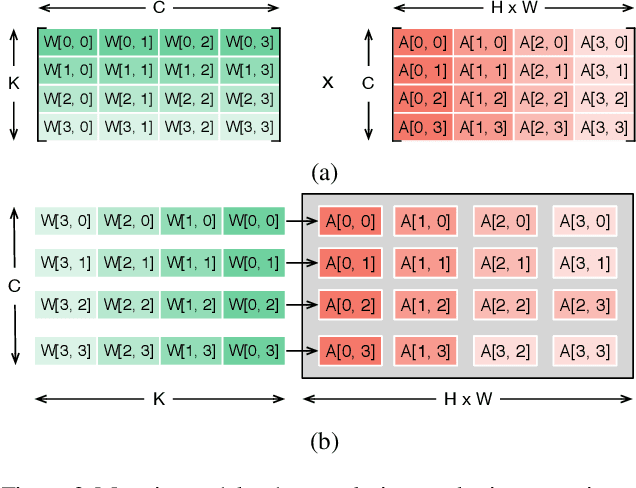
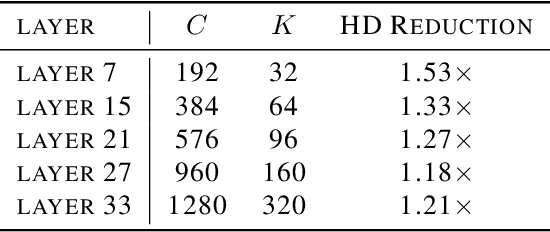
Neural network accelerator is a key enabler for the on-device AI inference, for which energy efficiency is an important metric. The data-path energy, including the computation energy and the data movement energy among the arithmetic units, claims a significant part of the total accelerator energy. By revisiting the basic physics of the arithmetic logic circuits, we show that the data-path energy is highly correlated with the bit flips when streaming the input operands into the arithmetic units, defined as the hamming distance of the input operand matrices. Based on the insight, we propose a post-training optimization algorithm and a hamming-distance-aware training algorithm to co-design and co-optimize the accelerator and the network synergistically. The experimental results based on post-layout simulation with MobileNetV2 demonstrate on average 2.85X data-path energy reduction and up to 8.51X data-path energy reduction for certain layers.
A Streaming Accelerator for Deep Convolutional Neural Networks with Image and Feature Decomposition for Resource-limited System Applications
Sep 15, 2017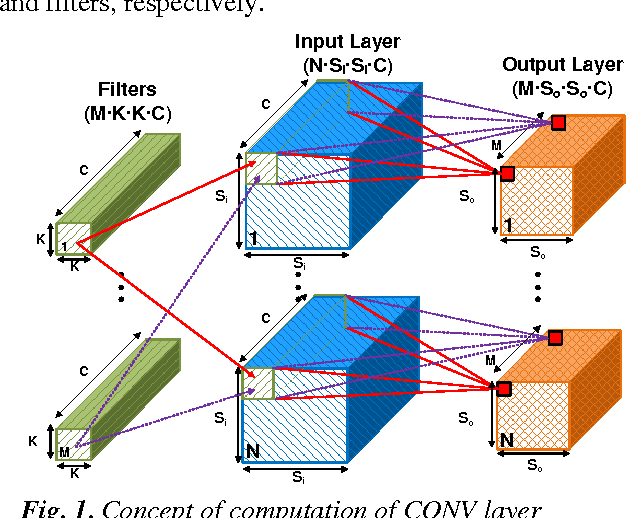
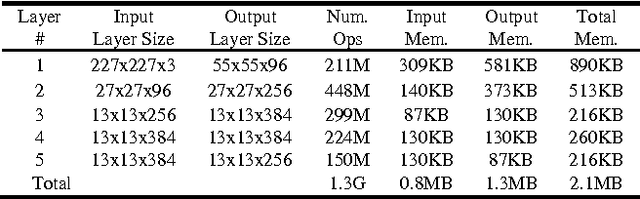
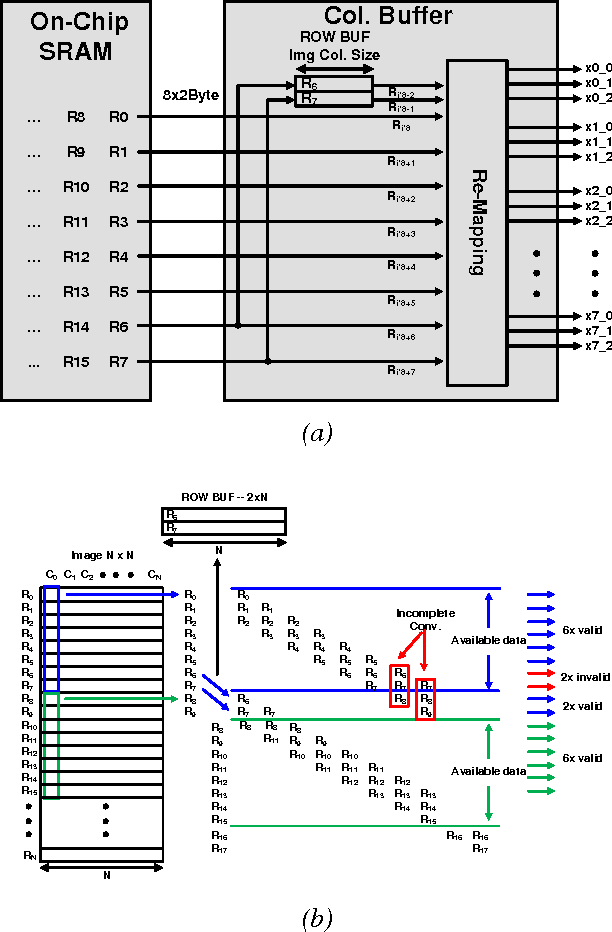
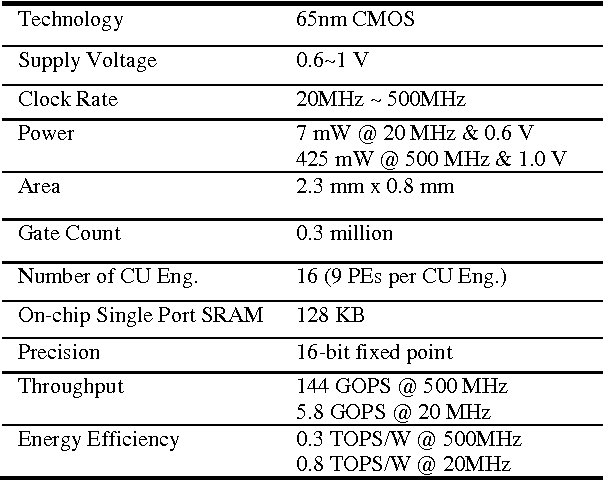
Deep convolutional neural networks (CNN) are widely used in modern artificial intelligence (AI) and smart vision systems but also limited by computation latency, throughput, and energy efficiency on a resource-limited scenario, such as mobile devices, internet of things (IoT), unmanned aerial vehicles (UAV), and so on. A hardware streaming architecture is proposed to accelerate convolution and pooling computations for state-of-the-art deep CNNs. It is optimized for energy efficiency by maximizing local data reuse to reduce off-chip DRAM data access. In addition, image and feature decomposition techniques are introduced to optimize memory access pattern for an arbitrary size of image and number of features within limited on-chip SRAM capacity. A prototype accelerator was implemented in TSMC 65 nm CMOS technology with 2.3 mm x 0.8 mm core area, which achieves 144 GOPS peak throughput and 0.8 TOPS/W peak energy efficiency.
A Reconfigurable Streaming Deep Convolutional Neural Network Accelerator for Internet of Things
Jul 08, 2017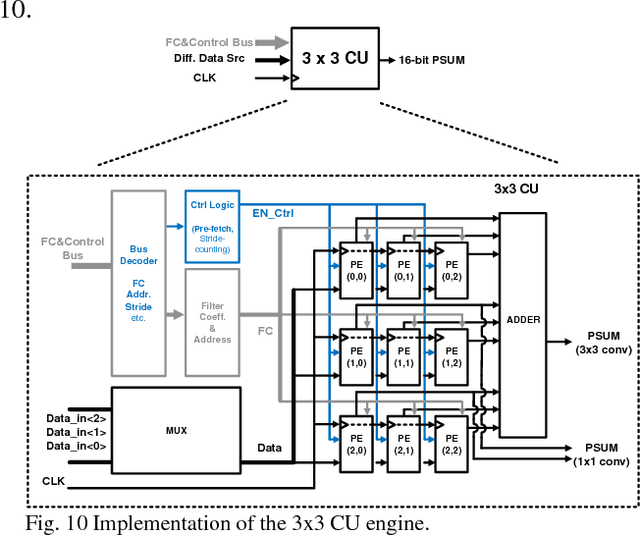
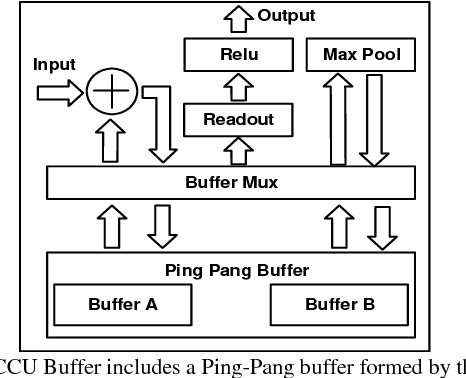
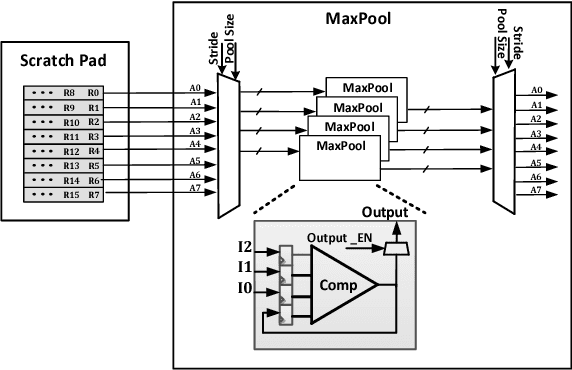
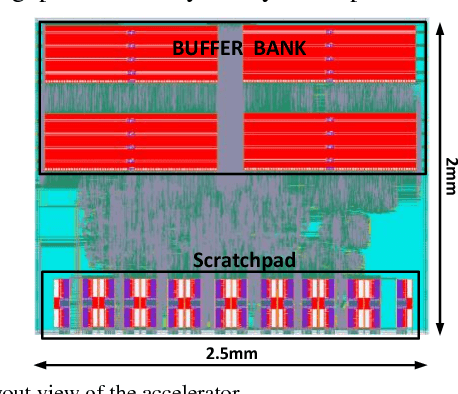
Convolutional neural network (CNN) offers significant accuracy in image detection. To implement image detection using CNN in the internet of things (IoT) devices, a streaming hardware accelerator is proposed. The proposed accelerator optimizes the energy efficiency by avoiding unnecessary data movement. With unique filter decomposition technique, the accelerator can support arbitrary convolution window size. In addition, max pooling function can be computed in parallel with convolution by using separate pooling unit, thus achieving throughput improvement. A prototype accelerator was implemented in TSMC 65nm technology with a core size of 5mm2. The accelerator can support major CNNs and achieve 152GOPS peak throughput and 434GOPS/W energy efficiency at 350mW, making it a promising hardware accelerator for intelligent IoT devices.