 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analog Neural Network Computing Engine using CMOS-Compatible Charge-Trap-Transistor (CTT)
Aug 09, 2018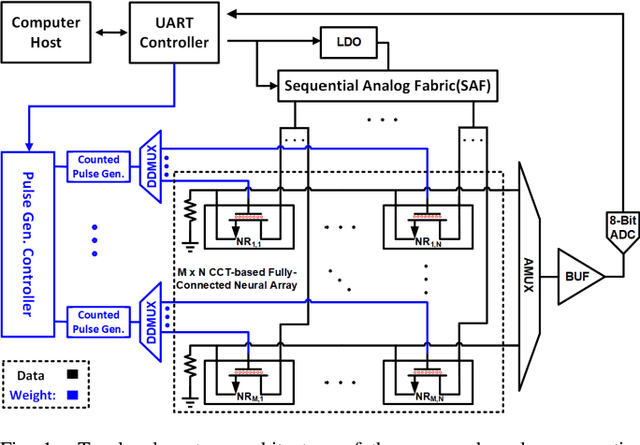
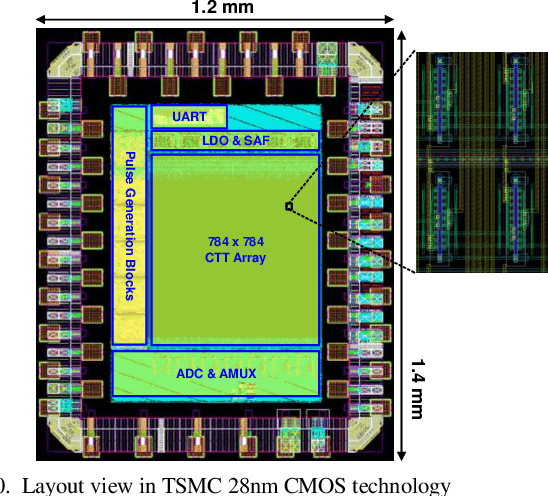
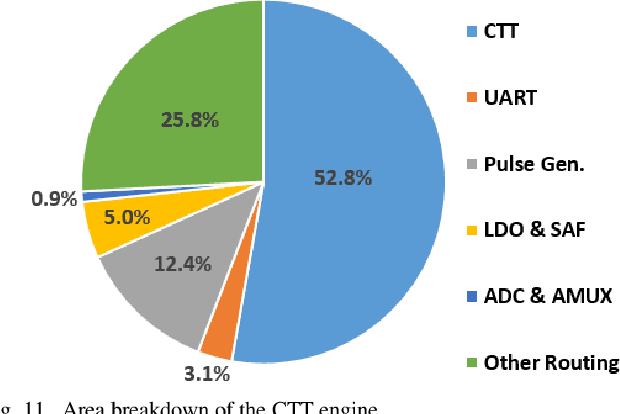
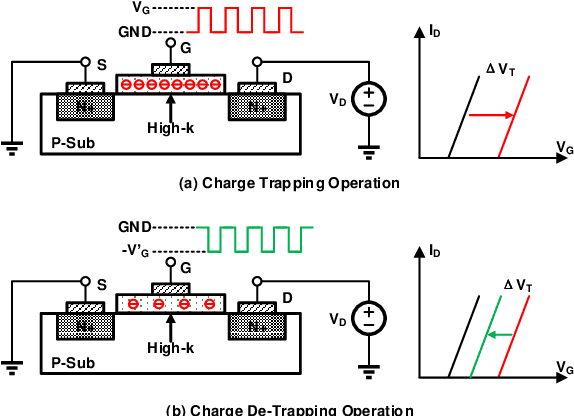
An analog neural network computing engine based on CMOS-compatible charge-trap transistor (CTT) is proposed in this paper. CTT devices are used as analog multipliers. Compared to digital multipliers, CTT-based analog multiplier shows significant area and power reduction. The proposed computing engine is composed of a scalable CTT multiplier array and energy efficient analog-digital interfaces. Through implementing the sequential analog fabric (SAF), the engine mixed-signal interfaces are simplified and hardware overhead remains constant regardless of the size of the array. A proof-of-concept 784 by 784 CTT computing engine is implemented using TSMC 28nm CMOS technology and occupied 0.68mm2. The simulated performance achieves 76.8 TOPS (8-bit) with 500 MHz clock frequency and consumes 14.8 mW. As an example, we utilize this computing engine to address a classic pattern recognition problem -- classifying handwritten digits on MNIST database and obtained a performance comparable to state-of-the-art fully connected neural networks using 8-bit fixed-point resolution.
A Streaming Accelerator for Deep Convolutional Neural Networks with Image and Feature Decomposition for Resource-limited System Applications
Sep 15, 2017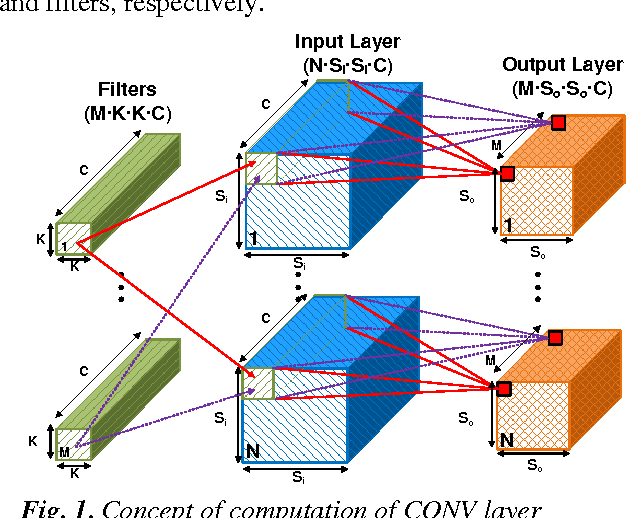
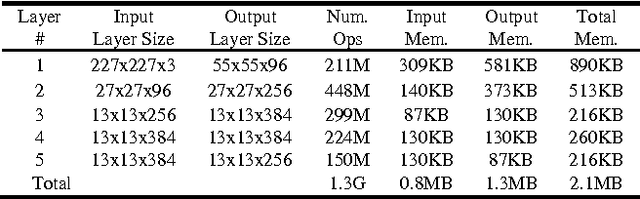
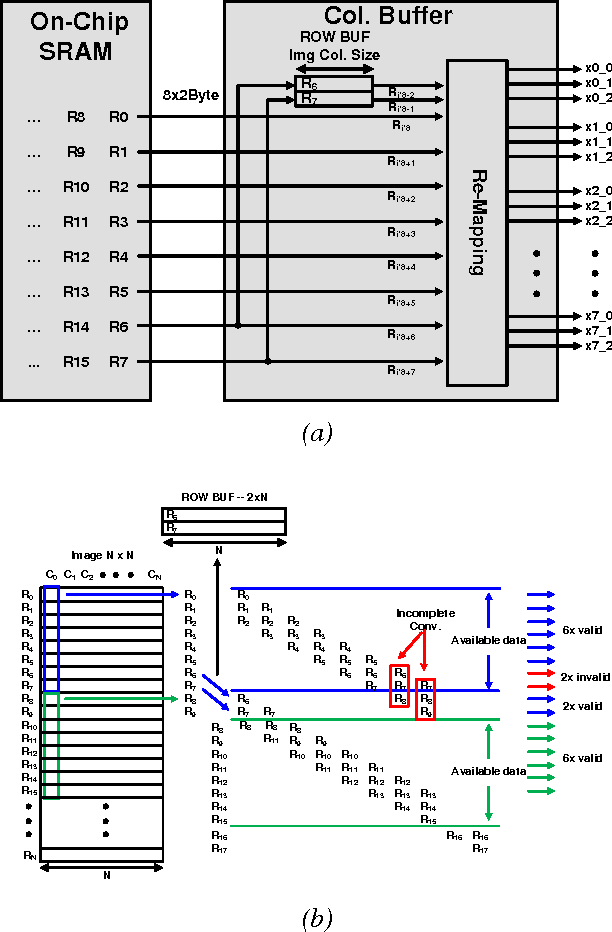
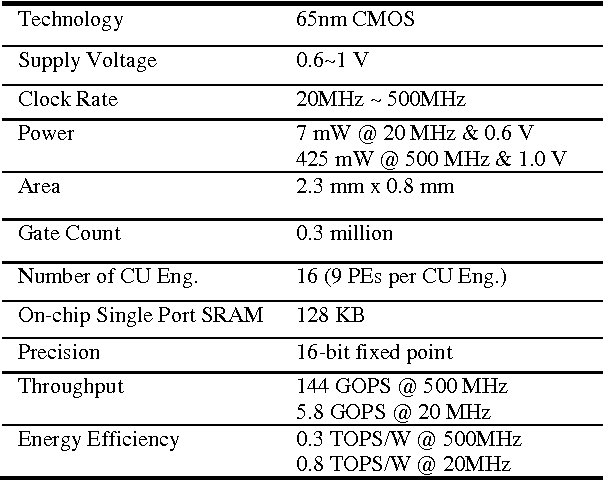
Deep convolutional neural networks (CNN) are widely used in modern artificial intelligence (AI) and smart vision systems but also limited by computation latency, throughput, and energy efficiency on a resource-limited scenario, such as mobile devices, internet of things (IoT), unmanned aerial vehicles (UAV), and so on. A hardware streaming architecture is proposed to accelerate convolution and pooling computations for state-of-the-art deep CNNs. It is optimized for energy efficiency by maximizing local data reuse to reduce off-chip DRAM data access. In addition, image and feature decomposition techniques are introduced to optimize memory access pattern for an arbitrary size of image and number of features within limited on-chip SRAM capacity. A prototype accelerator was implemented in TSMC 65 nm CMOS technology with 2.3 mm x 0.8 mm core area, which achieves 144 GOPS peak throughput and 0.8 TOPS/W peak energy efficiency.
A Reconfigurable Streaming Deep Convolutional Neural Network Accelerator for Internet of Things
Jul 08, 2017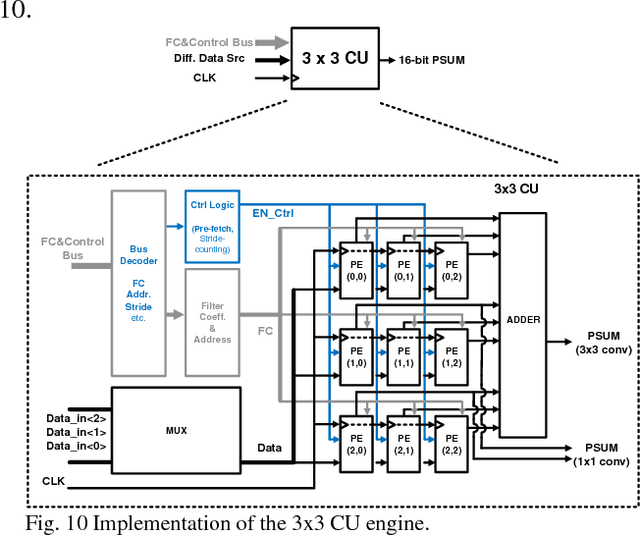
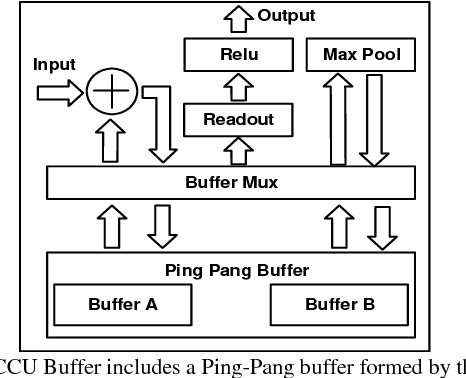
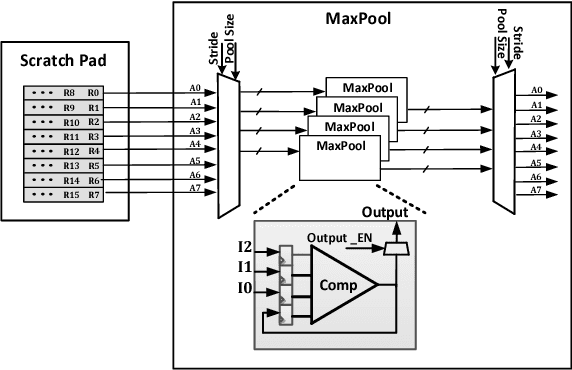
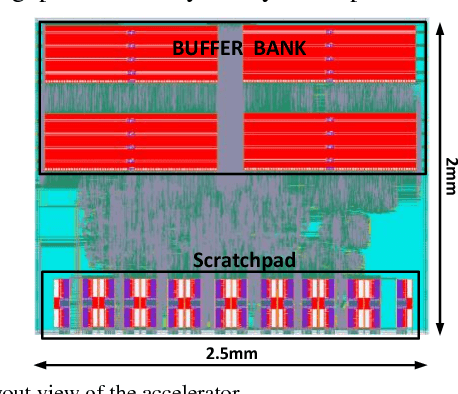
Convolutional neural network (CNN) offers significant accuracy in image detection. To implement image detection using CNN in the internet of things (IoT) devices, a streaming hardware accelerator is proposed. The proposed accelerator optimizes the energy efficiency by avoiding unnecessary data movement. With unique filter decomposition technique, the accelerator can support arbitrary convolution window size. In addition, max pooling function can be computed in parallel with convolution by using separate pooling unit, thus achieving throughput improvement. A prototype accelerator was implemented in TSMC 65nm technology with a core size of 5mm2. The accelerator can support major CNNs and achieve 152GOPS peak throughput and 434GOPS/W energy efficiency at 350mW, making it a promising hardware accelerator for intelligent IoT devices.