 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept-Guided Fine-Tuning: Steering ViTs away from Spurious Correlations to Improve Robustness
Mar 09, 2026Vision Transformers (ViTs) often degrade under distribution shifts because they rely on spurious correlations, such as background cues, rather than semantically meaningful features. Existing regularization methods, typically relying on simple foreground-background masks, which fail to capture the fine-grained semantic concepts that define an object (e.g., ``long beak'' and ``wings'' for a ``bird''). As a result, these methods provide limited robustness to distribution shifts. To address this limitation, we introduce a novel finetuning framework that steers model reasoning toward concept-level semantics. Our approach optimizes the model's internal relevance maps to align with spatially grounded concept masks. These masks are generated automatically, without manual annotation: class-relevant concepts are first proposed using an LLM-based, label-free method, and then segmented using a VLM. The finetuning objective aligns relevance with these concept regions while simultaneously suppressing focus on spurious background areas. Notably, this process requires only a minimal set of images and uses half of the dataset classes. Extensive experiments on five out-of-distribution benchmarks demonstrate that our method improves robustness across multiple ViT-based models. Furthermore, we show that the resulting relevance maps exhibit stronger alignment with semantic object parts, offering a scalable path toward more robust and interpretable vision models. Finally, we confirm that concept-guided masks provide more effective supervision for model robustness than conventional segmentation maps, supporting our central hypothesis.
Rethinking Saliency Maps: A Cognitive Human Aligned Taxonomy and Evaluation Framework for Explanations
Nov 18, 2025
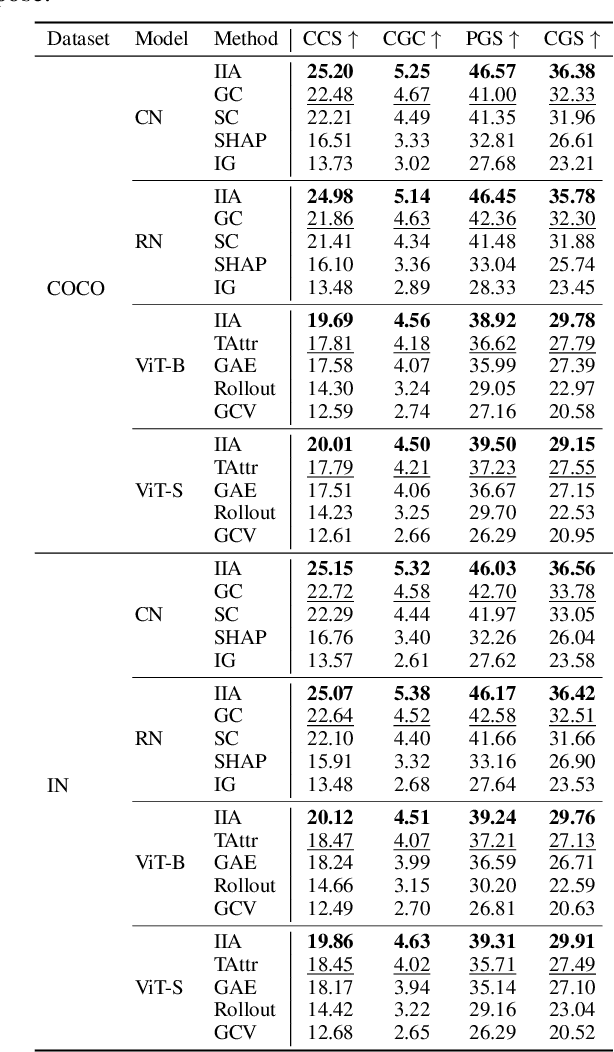


Saliency maps are widely used for visual explanations in deep learning, but a fundamental lack of consensus persists regarding their intended purpose and alignment with diverse user queries. This ambiguity hinders the effective evaluation and practical utility of explanation methods. We address this gap by introducing the Reference-Frame $\times$ Granularity (RFxG) taxonomy, a principled conceptual framework that organizes saliency explanations along two essential axes:Reference-Frame: Distinguishing between pointwise ("Why this prediction?") and contrastive ("Why this and not an alternative?") explanations. Granularity: Ranging from fine-grained class-level (e.g., "Why Husky?") to coarse-grained group-level (e.g., "Why Dog?") interpretations. Using the RFxG lens, we demonstrate critical limitations in existing evaluation metrics, which overwhelmingly prioritize pointwise faithfulness while neglecting contrastive reasoning and semantic granularity. To systematically assess explanation quality across both RFxG dimensions, we propose four novel faithfulness metrics. Our comprehensive evaluation framework applies these metrics to ten state-of-the-art saliency methods, four model architectures, and three datasets. By advocating a shift toward user-intent-driven evaluation, our work provides both the conceptual foundation and the practical tools necessary to develop visual explanations that are not only faithful to the underlying model behavior but are also meaningfully aligned with the complexity of human understanding and inquiry.
Forget What You Know about LLMs Evaluations - LLMs are Like a Chameleon
Feb 11, 2025



Large language models (LLMs) often appear to excel on public benchmarks, but these high scores may mask an overreliance on dataset-specific surface cues rather than true language understanding. We introduce the Chameleon Benchmark Overfit Detector (C-BOD), a meta-evaluation framework that systematically distorts benchmark prompts via a parametric transformation and detects overfitting of LLMs. By rephrasing inputs while preserving their semantic content and labels, C-BOD exposes whether a model's performance is driven by memorized patterns. Evaluated on the MMLU benchmark using 26 leading LLMs, our method reveals an average performance degradation of 2.15% under modest perturbations, with 20 out of 26 models exhibiting statistically significant differences. Notably, models with higher baseline accuracy exhibit larger performance differences under perturbation, and larger LLMs tend to be more sensitive to rephrasings indicating that both cases may overrely on fixed prompt patterns. In contrast, the Llama family and models with lower baseline accuracy show insignificant degradation, suggesting reduced dependency on superficial cues. Moreover, C-BOD's dataset- and model-agnostic design allows easy integration into training pipelines to promote more robust language understanding. Our findings challenge the community to look beyond leaderboard scores and prioritize resilience and generalization in LLM evaluation.
BEE: Metric-Adapted Explanations via Baseline Exploration-Exploitation
Dec 23, 2024



Two prominent challenges in explainability research involve 1) the nuanced evaluation of explanations and 2) the modeling of missing information through baseline representations. The existing literature introduces diverse evaluation metrics, each scrutinizing the quality of explanations through distinct lenses. Additionally, various baseline representations have been proposed, each modeling the notion of missingness differently. Yet, a consensus on the ultimate evaluation metric and baseline representation remains elusive. This work acknowledges the diversity in explanation metrics and baselines, demonstrating that different metrics exhibit preferences for distinct explanation maps resulting from the utilization of different baseline representations and distributions. To address the diversity in metrics and accommodate the variety of baseline representations in a unified manner, we propose Baseline Exploration-Exploitation (BEE) - a path-integration method that introduces randomness to the integration process by modeling the baseline as a learned random tensor. This tensor follows a learned mixture of baseline distributions optimized through a contextual exploration-exploitation procedure to enhance performance on the specific metric of interest. By resampling the baseline from the learned distribution, BEE generates a comprehensive set of explanation maps, facilitating the selection of the best-performing explanation map in this broad set for the given metric. Extensive evaluations across various model architectures showcase the superior performance of BEE in comparison to state-of-the-art explanation methods on a variety of objective evaluation metrics.
Deep Integrated Explanations
Oct 28, 2023



This paper presents Deep Integrated Explanations (DIX) - a universal method for explaining vision models. DIX generates explanation maps by integrating information from the intermediate representations of the model, coupled with their corresponding gradients. Through an extensive array of both objective and subjective evaluations spanning diverse tasks, datasets, and model configurations, we showcase the efficacy of DIX in generating faithful and accurate explanation maps, while surpassing current state-of-the-art methods.
Visual Explanations via Iterated Integrated Attributions
Oct 28, 2023



We introduce Iterated Integrated Attributions (IIA) - a generic method for explaining the predictions of vision models. IIA employs iterative integration across the input image, the internal representations generated by the model, and their gradients, yielding precise and focused explanation maps. We demonstrate the effectiveness of IIA through comprehensive evaluations across various tasks, datasets, and network architectures. Our results showcase that IIA produces accurate explanation maps, outperforming other state-of-the-art explanation techniques.
Learning to Explain: A Model-Agnostic Framework for Explaining Black Box Models
Oct 25, 2023



We present Learning to Explain (LTX), a model-agnostic framework designed for providing post-hoc explanations for vision models. The LTX framework introduces an "explainer" model that generates explanation maps, highlighting the crucial regions that justify the predictions made by the model being explained. To train the explainer, we employ a two-stage process consisting of initial pretraining followed by per-instance finetuning. During both stages of training, we utilize a unique configuration where we compare the explained model's prediction for a masked input with its original prediction for the unmasked input. This approach enables the use of a novel counterfactual objective, which aims to anticipate the model's output using masked versions of the input image. Importantly, the LTX framework is not restricted to a specific model architecture and can provide explanations for both Transformer-based and convolutional models. Through our evaluations, we demonstrate that LTX significantly outperforms the current state-of-the-art in explainability across various metrics.